









原文链接:http://www.juzicode.com/image-ocr-python-easyocr
桔子菌之前在 pytesseract提取识别图片中的文字 中介绍过怎么在Python中使用tesseract提取和识别图片中的文字,今天再来聊一聊EasyOcr,它也是一款非常优秀的OCR包,使用起来是相当地easy。
1、安装easyocr包
这里以windows系统为例,需要先安装pytorch,在pytorch官网可以根据语言版本、操作系统等信息找到安装方法:
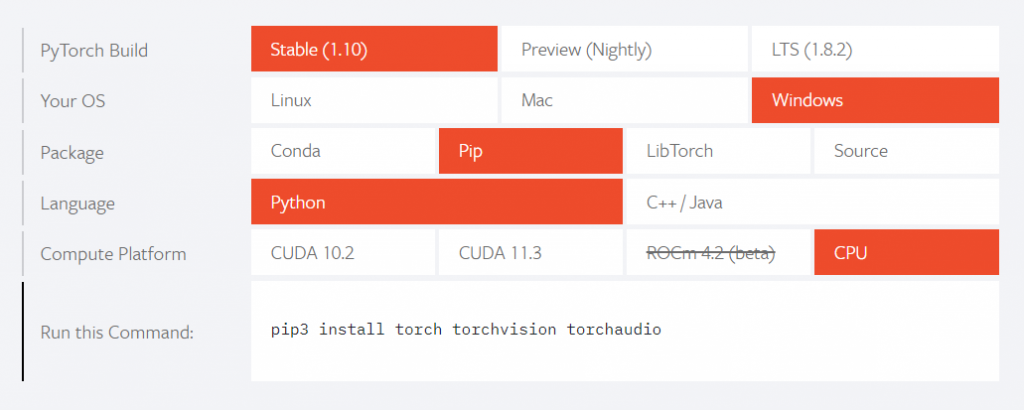
pip3 install torch torchvision torchaudio安装easyocr:
pip3 install easyocr安装完成后,可以通过easyocr.__version__查看版本号:
import easyocr
print(easyocr.__version__)2、安装检测模型、识别模型(语言包)
如果事先没有安装检测模型和识别模型,第一次执行脚本时会自动下载2种模型文件:


这种方式下载速度较慢,而且容易出错导致下载中断,可以通过手动方式下载、安装。
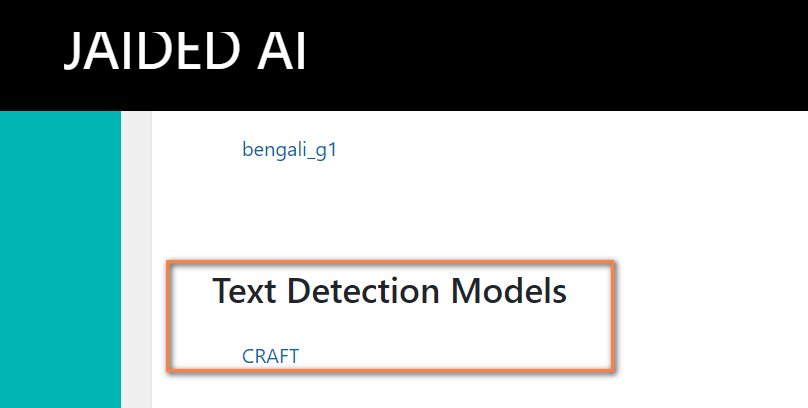
进入esayocr官网选择需要的模型下载(Jaided AI: EasyOCR model hub)。
首先下载文本检测模型:
接下来下载识别模型,识别模型对应了各种语言包,下图是简体中文和英文的识别模型:

将下载的模型文件解压后拷贝到当前登录的用户目录的.EasyOCR\model文件夹下,Windows系统为:C:\Users\yourname\.EasyOCR\model,其中yourname是登录用户名。
【注】这里下载的识别模型(语言包)的文件名称和后面看到的语言类型并不是完全对应的,比如在代码中的语言类型ch_sim对应简体中文(zh_sim_g2),en对应英文(english_g2)。
3、使用方法
EsayOcr的使用正如其名非常地简单,就是2个步骤,第1步创建Reader()实例,第2步用readtxt()方法检测和识别。
创建Reader()实例
初始化Reader()实例的参数有:
- lang_list (list):识别语言代码,比如[‘ch_sim’,’en’]分别表示简体中文和英文。
- gpu (bool, string, default = True) :是否使能GPU,只有安装了GPU版本才有效。
- model_storage_directory (string, default = None) :模型存储位置,依次查找系统变量EASYOCR_MODULE_PATH (preferred)、MODULE_PATH (if defined)表示的路径或者~/.EasyOCR/路径。
- download_enabled (bool, default = True):如果没有对应模型文件时,自动下载模型。
- user_network_directory (bool, default = None) :用户自定义识别网络的路径,如果没有指明,则在MODULE_PATH + ‘/user_network’ (~/.EasyOCR/user_network)目录中查找。
- recog_network (string, default = ‘standard’) :替代标准模型,使用自定义的识别网络。
- detector (bool, default = True) :是否加载检测模型。
- recognizer (bool, default = True) :是否加载识别模型。
创建完实例后,识别文字就要用到其readtext()方法。
检测与识别readtext()方法
下面是一个最简单的应用例子,首先创建一个reader对象,传入要使用的语言包(识别模型),然后在reader对象的readtext方法中传入要识别的文件名称:

#juzicode.com / vx:桔子code
import easyocr
reader = easyocr.Reader(['ch_sim','en'])
result = reader.readtext('road-poetry.png')
for res in result:
print(res)运行结果:
([[151, 101], [195, 101], [195, 149], [151, 149]], '西', 0.9816301184856115)
([[569, 71], [635, 71], [635, 131], [569, 131]], '东', 0.9986620851098884)
([[218, 92], [535, 92], [535, 191], [218, 191]], '诗和远方路', 0.8088406614287519)
([[137, 217], [177, 217], [177, 257], [137, 257]], 'W', 0.8304899668428476)
([[209, 217], [525, 217], [525, 257], [209, 257]], 'Poetry And The Places Afar Rd。', 0.40033782611925706)
([[571, 207], [611, 207], [611, 251], [571, 251]], 'C', 0.1553293824532922)readtext()方法返回一个元组,包含了多个元素,每个元素由识别到文字信息的边框,文字内容,可信度等3部分组成。
除了前面例子中readtext()传入文件名称,也可以在readtext()方法中传入图像的numpy数组,比如用opencv读取图片文件得到的numpy数组:
#juzicode.com / vx:桔子code
import easyocr
import cv2
reader = easyocr.Reader(['ch_sim','en'])
img = cv2.imread('road-poetry.png' )
result = reader.readtext(img)
color=(0,0,255)
thick=3
for res in result:
print(res)
pos = res[0]
text = res[1]
for p in [(0,1),(1,2),(2,3),(3,0)]:
cv2.line(img,pos[p[0]],pos[p[1]],color,thick)
cv2.imwrite('bx-road-poetry.jpg',img)运行结果:
([[151, 101], [195, 101], [195, 149], [151, 149]], '西', 0.9805448761688105)
([[569, 71], [635, 71], [635, 131], [569, 131]], '东', 0.9985224701960114)
([[217, 91], [534, 91], [534, 194], [217, 194]], '诗和远方路', 0.8750403596327564)
([[137, 217], [177, 217], [177, 257], [137, 257]], 'W', 0.7520859053705777)
([[209, 217], [523, 217], [523, 257], [209, 257]], 'Poetry And The Places Afar Rd。', 0.3012721541954036)
([[571, 207], [611, 207], [611, 251], [571, 251]], 'C', 0.15253169048338933)
第3种方法是在readtext()中传入读出的原始字节内容,注意图片文件是以rb方式读出:
#juzicode.com / vx:桔子code
import easyocr
reader = easyocr.Reader(['ch_sim','en'])
with open('road-poetry.png','rb') as pf:
img = pf.read()
result = reader.readtext(img)
for res in result:
print(res)运行结果:
([[151, 101], [195, 101], [195, 149], [151, 149]], '西', 0.673960519698312)
([[569, 71], [635, 71], [635, 131], [569, 131]], '东', 0.9128537192685862)
([[218, 92], [535, 92], [535, 191], [218, 191]], '诗和远方路', 0.7941057755221305)
([[137, 217], [177, 217], [177, 257], [137, 257]], 'W', 0.7182424534268108)
([[209, 217], [525, 217], [525, 257], [209, 257]], 'Poetry And The Places Afar Rd。', 0.5591090091224509)
([[571, 207], [611, 207], [611, 251], [571, 251]], 'C', 0.1532075452826911)EasyOcr,so easy,你学废了吗?
推荐阅读:















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









