






进行大批量图片识别时候,很重要一点就是减少无用的识别,这样可以提高整体的运行效率,以免不必要的资源浪费,所以裁剪是一个很有效的方法,能大大提高大批量处理的效率,而且裁剪后保存的储存空间会缩小很多。
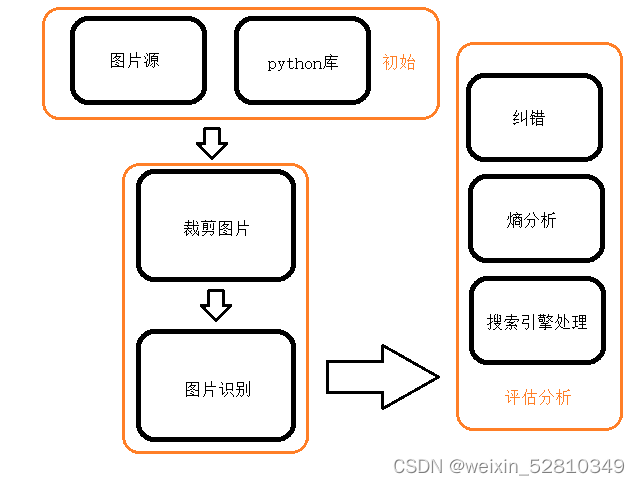
架构图如下:
末尾有图片展示一部分的操作结果
这里采用的是pil方法,也可以采用cv2,以下是pil和cv2方法
from PIL import Image
import os
from os import path
import time
def scaner_file (url):
a =0
file = os.listdir(url)
time_start =time.time()
for f in file:
a+=1
print(url + "/" + f)
img = Image.open(url + "/" + f)
crop_img = img.crop((25,150,1055,2230))#裁剪的范围,这里用的是手机上下无用边框
crop_img.save('G:/test/'+f)#保存路径,f是作为保存图片名称,这里用了原始图片名
time_end = time.time()
n = 100#通过这个来设置数量多少
if a == n:
print("break")
break
print("平均时长为%.5f"%((time_end - time_start)/a))
print("时长为%.5f"%(time_end - time_start),"秒")
print(len(file))
scaner_file('G:/photo')#文件夹位置,会遍历文件夹的所有文件import cv2
import os
from os import path
def scaner_file (url):
file = os.listdir(url)
a = 0
for f in file:
a+=1
print(url + "/" + f)
img = cv2.imread(url + "/" + f)#img_path为图片所在路径
crop_img = img[2240:300,0:1080]#x0,y0为裁剪区域左上坐标;x1,y1为裁剪区域右下坐标
print(crop_img)
print(img)
cv2.imwrite('G:/test/'+f,crop_img) #保存路径,f是作为保存图片名称,这里用了原始图片名
if a == 10:
print("break")
break
scaner_file('G:/photo')#文件夹位置,会遍历文件夹的所有文件做完裁剪后,就可以做图片识别了
这里采用的是easyocr模型
import os
from os import path
import easyocr
import time
#定义一个函数
reader = easyocr.Reader(['ch_sim', 'en'])#用到的语言
def scaner_file (url):
time_start = time.time()
time_number = 0
#遍历当前路径下所有文件
file = os.listdir(url)
print(len(file))
for f in file:
time_number+=1
#打印出来
article = ''
print(url + "/" + f)
article = ocr(url,f,article)
txt(article,time_number)
print(f)
time_end = time.time()
print("平均为:%.2f"%((time_end-time_start)/time_number)+"秒"+"\n次数为:",
time_number,"\n总时长为:%.2f"%((time_end-time_start)/60)+"分钟")
if time_number == 10000:#数量
print("break")
break
#调用自定义函数
def ocr(url,f,article):
result = reader.readtext(url + "/" + f, detail=0)
for i in range(len(result)):
article += result[i] # 将列表中的字符串依次拼接在一起
print(article)
return article
def txt(article,time_number):#保存txt文件的时候不能出现一些特殊字符要经过处理
name =""
for i in range(len(article)):#处理语句
if i <=30:
if article[i] >= u'\u4e00' and article[i] <= u'\u9fa5':
name += article[i]
if article[i] >= u'\u0030' and article[i] <= u'\u0039':
name += article[i]
if (article[i] >= u'\u0041' and article[i] <= u'\u005a') or (article[i] >= u'\u0061' and article[i] <= u'\u007a'):
name += article[i]
with open("G:/test/"+name+str(time_number)+".txt", 'w+', encoding='UTF-8') as file_object:#这里的地址是放置的地方
file_object.write(article)
scaner_file('G:/txt')#这里是识别图片的地址,地址不能用中文,easyocr问题,如果通过对easyocr源码将中文放入内存的修改,就可以使用中文了对图片识别后要对识别的文字数据进行处理这里
这里我用到pycorrector来文字纠错,效果较差,但是考虑到大型模型运行效率较低,则可以实验感受一下,源码如下:
import pycorrector
import os
from os import path
import time
def scaner_file (url):
file = os.listdir(url)
start = time.time()
b=0
for f in file:
print(f)
b+=1
f1 = open(url + "/" + f, 'r+', encoding='UTF-8')
n = f1.read()
corrected_sent,detail = pycorrector.correct(n)
print(corrected_sent)
print(detail)
end =time.time()
print("平均时间:%.4f"%((end - start)/b),"秒")
if b ==5:#这里用了5个作为测试,但效果较差
print("break")
break
scaner_file('G:/txt')#文件夹
这里我通过熵来简单判断有问题的数据
import os
from os import path
def scaner_file (url):
file = os.listdir(url)
for f in file:
f1 = open(url+"/"+f , 'r+', encoding='UTF-8')
n = f1.read()
f1.close()
ie = 0#信息熵
chaos = 0 #我认为混乱熵为 3.5 ,每有一个时混乱度上升3.5
for i in range(len(n)):
chaos+=3.5#我这里设计混乱为3.5
if n[i] >= u'\u4e00' and n[i] <= u'\u9fa5':#中文
ie+=9.59
if n[i] >= u'\u0030' and n[i] <= u'\u0039':#数字
ie+=1.5
if (n[i] >= u'\u0041' and n[i] <= u'\u005a') or (
n[i] >= u'\u0061' and n[i] <= u'\u007a'): #英文
ie+=3.9
#汉字信息熵9.59,英语信息熵3.9,数字信息熵1.5
#混乱字熵计算问题
sum_e = chaos - ie#这里sum_e是整体熵值,能评估整体
if len(n) ==0:
n ="1"
mean_e = sum_e/len(n)#这里的mean_e是平均熵,能够发现乱码或其他识别错误的问题
if sum_e >= -500 or mean_e >=-3:#这里的-500和-3是自己定义的,根据不同的值出来的效果也不同
print("总熵为:",sum_e)
print("平均熵为:",mean_e)
print(f)#输出文件名
print(n)#输出内容
#os.remove(os.path.join(url,f))#删除语句小心谨慎
print("查找成功")
scaner_file('G:/txt')#文件夹
print("完成")这里我设计了通过selenium来和搜索引擎配合来处理文字数据,这里采用的是百度搜索引擎来处理,这里是大概代码模板,每个网页不一样,要进行细修
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import os
from os import path
import time
import jieba
import numpy
def scaner_file (url):
file = os.listdir(url)
start = time.time()
m = 0
for f in file:
t_n = ""
article = ""
m +=1
f1 = open(url+"/"+f , 'r+', encoding='UTF-8')
text = f1.read()
f1.close()
# 精确模式
n1 = jieba.lcut(text, cut_all = False)
print(n1)
b = 0
for i in range(len(n1)):
if i != " ":
b += 1
print(str(b) + "个字")
N = 0
num = 0
if b != 0:
for i in n1:
num += 1
if i != " ":
article += i
if (i == "。" or i == "." or i == "!" or i == "!"
or i == "?" or i == "?" or i == '”'
or i == '’' or i == '"') and len(article) >= 2:
print(article)
article = ""
N += 1
if len(article) >= 45:
print(article)
article = ""
N += 1
if num == len(n1):
print(article)
N += 1
print("平均长度:%.2f"%(b/N))
if m ==100:
print("break")
break
cword(article, t_n)
end = time.time()
print("平均每个时间:%.4f"%((end - start)/m)+"秒")
print("全部时间:%.4f"%(end - start)+"秒")
def cword(article,t_n):
n = str(article)
options = Options()
options.headless = False
driver =webdriver.Chrome(options = options)
driver.get('http://www.baidu.com')
time.sleep(0.5)
input = driver.find_element_by_id("kw").send_keys(n)
b = driver.find_element_by_id("su").click()
time.sleep(0.5)
number = driver.find_element_by_class_name("hint_PIwZX.c_font_2AD7M")#这里需要把空格换成点
print(number.text)
t_n = ""
for i in number.text:
if i >= u'\u0030' and i <= u'\u0039':
t_n += i
print(t_n)
if int(t_n) <=500:
print("搜索小于500")
print(n)
driver.close()
return t_n
time.sleep(1)
scaner_file('K:/txt')#文件夹
再进阶就是利用GPT来处理文字数据,但是文字识别上问题较多,所以GPT在使用过程中不没有那么好的性能和效率。
大概整体的效果为:
裁剪前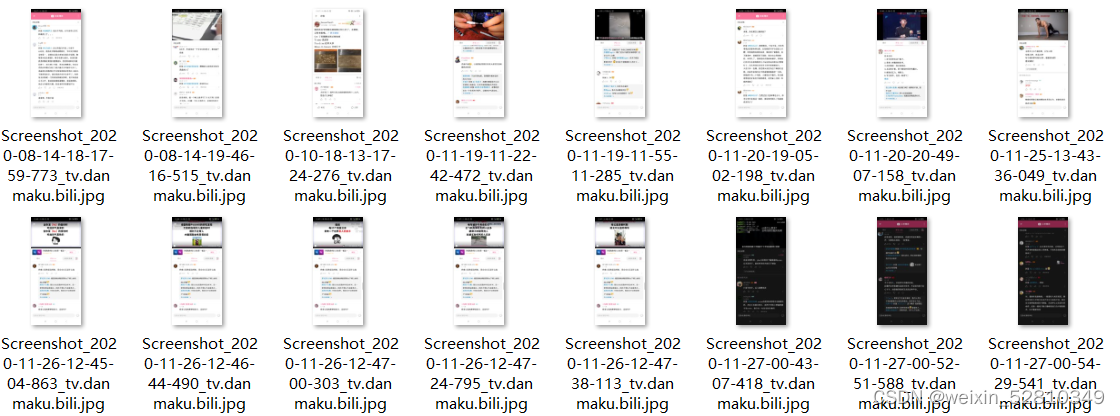
裁剪后
easyocr的处理

我写的熵识别
全部代码和资源已经上传到同站https://download.csdn.net/download/weixin_52810349/87902732?spm=1001.2014.3001.5503















 4081
4081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









