







前言
#在计算机系统中,数据的存储方式是编程和系统设计的基础
本次我学习了关于计算机中整数,浮点数,以及字节序的相关知识,
我将以我的理解进行知识的分享。
一、整数在内存中的存储
1. 无符号整数
unsigned int/char 等等类型
意义 无符号整数只能表示非负数值,其存储方式直接使用二进制原码。
例如,一个 8 位无符号整数可以表示 0 到 255 之间的数值:

例如 数值 5 的二进制表示:0000 0101
例如 数值 255 的二进制表示:1111 1111
2. 有符号整数
signed int/char 等等类型
有符号整数需要同时表示正数和负数,因此采用补码形式存储。
补码的优势在于可以将减法运算转换为加法运算,简化硬件设计。
补码的计算规则:
正数的补码与原码相同
负数的补码是其绝对值的原码取反加一
例如,一个 8 位有符号整数:
数值 5 的二进制表示:0000 0101(最高位为 0 表示正数)
数值 - 5 的二进制表示:5 的原码:0000 0101 取反:1111 1010 加一:1111 1011
3. 整数溢出
当一个整数的值超出其数据类型所能表示的范围时,就会发生溢出。
溢出的结果在无符号和有符号整数中表现不同:
无符号整数溢出会 “环绕”,例如 255 + 1 会变成 0

有符号整数溢出是未定义行为,可能导致程序崩溃或产生不可预期的结果
-127的二进制已经是1111 1111如果此时减一 -1是 1000 0001,会造成严重的溢出
1 1000 0000 (溢出,丢弃进位)
二、大小端字节序和字节序判断
1. 大小端字节序的概念
字节序是指多字节数据在内存中存储时的字节排列顺序。
常见的字节序有两种:
大端字节序:高位字节存储在低地址,低位字节存储在高地址。类似人类读写数字的顺序。
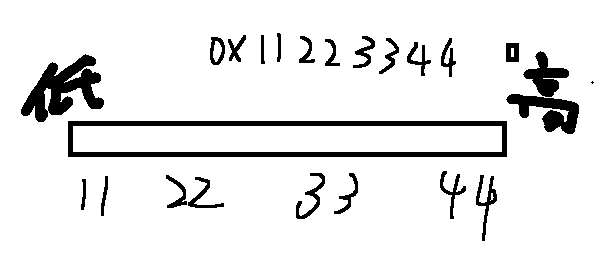
小端字节序:低位字节存储在低地址,高位字节存储在高地址。常见于 x86 和 ARM 架构。
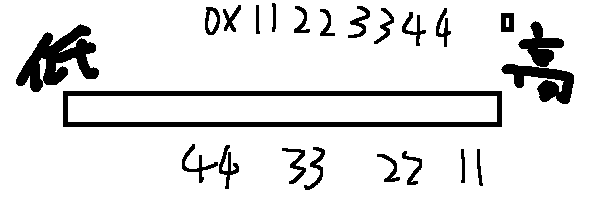
2. 字节序的判断方法
方法一:使用联合(Union)
#include <stdio.h>
int isLittleEndian() {
union {
int i;
char c[4];
} u;
u.i = 1;
return u.c[0] == 1; // 小端字节序下,最低地址字节为1
}
int main() {
if (isLittleEndian()) {
printf("小端字节序\n");
} else {
printf("大端字节序\n");
}
return 0;
}方法二:指针类型转换
#include <stdio.h>
int isLittleEndian() {
int num = 1;
char *c = (char*)#
return *c == 1; // 小端字节序下,第一个字节为1
}3. 字节序的应用场景
三、浮点数在内存中的存储
浮点数的存储比整数复杂得多,主要遵循 IEEE 754 标准。
1. IEEE 754 标准
IEEE 754 标准定义了两种主要的浮点数格式:
单精度浮点数(float):32 位,由 1 位符号位(S)、8 位指数(E)和 23 位尾数(M)组成
双精度浮点数(double):64 位,由 1 位符号位、11 位指数和 52 位尾数组成
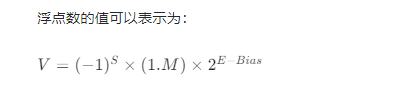
其中:
S 为符号位(0 表示正数,1 表示负数)
M 为尾数(二进制小数)
E 为指数(需要减去一个偏置值 Bias,单精度 Bias 为 127,双精度为 1023)
3. 浮点数的精度问题
由于浮点数的二进制表示无法精确表示所有十进制小数,因此会存在精度丢失问题


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









