








🏡作者主页:点击!
🤖编程探索专栏:点击!
⏰️创作时间:2024年11月24日14点43分
神秘男子影,
秘而不宣藏。
泣意深不见,
男子自持重,
子夜独自沉。
Poke Face 也会无法隐藏你的内心

随着用户生成的在线内容的丰富,MSA 最近成为自然语言处理领域的一个活跃领域。提高针对数据丢失的鲁棒性已成为多模态情感分析(MSA)的核心挑战之一,该分析旨在从语言、视觉和听觉信号中判断说话人的情感。 目前的研究中,针对模态特征不完整的MSA提出了基于平移的方法和张量正则化方法。 然而,它们都无法应对非对齐序列中缺失的随机模态特征。
本文提出了一种基于Transformer的特征重建网络,以提高模型针对非对齐模态序列中随机缺失的鲁棒性
同时,在流行的多模态任务–多模态情感计算的数据集上对模型进行了测试,得到了不错的效果,证明了该模型的可靠性。具体来说,使用了MOSI,MOSEI,以及中文数据集 SIMS,以及抑郁症数据集AVEC2019,为医学心理学等领域提供帮助。
【注】 文章中所用到的数据集,都经过重新特征提取形成新的数据集特征文件(.pkl),另外该抑郁症数据集因为涉及患者隐私,需要向数据集原创者申请,申请和下载链接都放在了附件中的 readme文件中,感兴趣的小伙伴可以进行下载,谢谢支持!
一、研究背景
随着用户生成的在线内容的丰富,MSA 最近成为一个相当活跃领域。 使用手动对齐的完整信息,包括转录语言、音频和视觉,之前的工作在 MSA 任务上取得了显着的改进。 然而,用户生成的野外视频通常并不完美。 首先,不同模式的受体可能具有不同的接收频率,这导致性质不一致。 其次,许多不可避免的因素,例如用户生成的视频中的噪声损坏或传感器故障,可能会导致模态特征提取器的失败。 在上述情况下,需要一种能够处理随机模态特征缺失的模型。 因此,在 MSA 中构建能够处理特征确实的模型仍然是一个开放的研究。
二、模型结构和代码
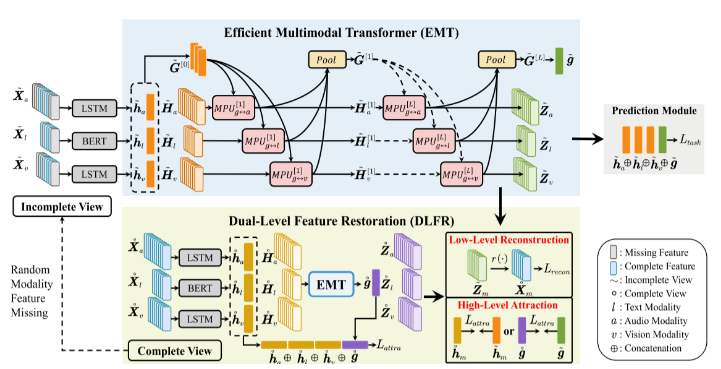
在本节中,作者描述了所提出的具有双级特征恢复的高效多模态Transformer,用于鲁棒MSA,其整个流程处于不完整模态设置中,如上图所示。在此设置中,作者使用真实标签–完整的视图,从不完整的多模态序列中实现鲁棒的表示学习。 具体来说,对于这两种视图,作者首先利用特定于模态的编码器从不同模态输入获取话语级(即全局)和元素级(即局部)模态内特征。 然后,采用高效多模态变压器来有效且高效地捕获全局多模态上下文和局部单模态特征之间有用的跨模态交互。 之后,结合话语级的模态内和模间特征来得到最终的情感强度预测。 为了提高模型对随机模态特征缺失的鲁棒性,双级特征恢复同时进行高级特征吸引和低级特征重建。 前者明确地吸引潜在空间中两种视图的高级模态内和模态间表示,而后者从完整视图中重构低级模态输入,以隐式地促使模型学习语义信息。
1. 单模态特征编码
参考前人的工作,作者使用强大的 BERT模型将原始文本标记编码为上下文词嵌入。对于音频和视频模态,作者选择了简单的方法,使用常用的长短期记忆(LSTM)递归神经网络来捕捉特征序列中的时间依赖性,即

其中 𝐻𝑚∈𝑅𝑇𝑚×𝑑𝑚Hm∈RTm×dm,𝑚∈{𝑙,𝑎,𝑣}m∈{l,a,v}。由于 BERT 中的 [CLS] 标记聚合了所有标记的信息,作者使用其嵌入作为文本模态的语句级表示 ℎ𝑙∈𝑅𝑑𝑙hl∈Rdl。对于 ℎ𝑎∈𝑅𝑑𝑎ha∈Rda 和 ℎ𝑣∈𝑅𝑑𝑣hv∈Rdv,作者仅使用 Ha 和 Hv 中最后一个时间步的特征。最后,作者使用多个线性层将 𝐻𝑙Hl,𝐻𝑎Ha,𝐻𝑣Hv,ℎ𝑙hl,ℎ𝑎ha,和 ℎ𝑣hv 投射到相同的维度 $d%,以便于后续的多模态融合。
2. 高效多模态Transformer
以下是这段文本的中文翻译,公式用$括起来:
在这一部分中,作者首先进行初步介绍。然后作者介绍了EMT的基本构建单元,称为相互促进单元(Mutual Promotion Unit, MPU)。基于MPU,作者详细说明了三种用于建模跨模态交互的多模态融合策略。然而,它们都存在涉及模态的二次计算复杂度问题。第三种策略在实际中具有线性扩展成本,因此默认在EMT中采用。最后,作者提出了EMT的分层参数共享,以进一步提高参数效率。
- 初步介绍:自注意力机制是Transformer的核心组件。它允许通过缩放点积注意力在序列中建模全局依赖关系。对于输入序列𝐻𝑡∈𝑅𝑇𝑡×𝑑Ht∈RTt×d,将查询定义为𝑄𝑡=𝐻𝑡𝑊𝑄Qt=HtWQ,键值定义为𝐾𝑡=𝐻𝑡𝑊𝐾Kt=HtWK,值定义为𝑉𝑡=𝐻𝑡𝑊𝑉Vt=HtWV,其中𝑊𝑄WQ 和 𝑊𝐾∈𝑅𝑑×𝑑𝑘WK∈Rd×dk,𝑊𝑉∈𝑅𝑑×𝑑𝑣WV∈Rd×dv。然后SA可以公式化如下:

跨模态注意力机制涉及两个模态。查询来自目标模态𝑡t,而键和值来自源模态𝑠s,即𝑄𝑡=𝐻𝑡𝑊𝑄Qt=HtWQ,𝐾𝑠=𝐻𝑠𝑊𝐾Ks=HsWK,𝑉𝑠=𝐻𝑠𝑊𝑉Vs=HsWV。通过这种方式,CA可以提供从模态𝑠s到𝑡t的潜在适配:

这是一种融合跨模态信息的好方法。需要注意的是,为了简化,作者只展示了单头注意力机制的公式。在实际操作中,作者使用多头自注意力或多头跨模态注意力来使模型能够关注来自不同特征子空间的信息。
- 相互促进单元:MPU的架构如下图所示。它主要利用对称的跨模态注意力来探索两个输入特征序列之间元素的内在关联。通过这种方式,MPU能够在两个序列之间进行有用的信息交换,从而它们可以相互促进。为了进一步整合信息,采用自注意力机制在每个特征序列中建模时间依赖性。形式上,MPU以两个序列𝐻𝑚Hm 和𝐻𝑛Hn 为输入,输出它们相互促进的序列𝐻𝑛→𝑚Hn→m 和𝐻𝑚→𝑛Hm→n:

其中→→和↔↔表示信息流的方向。具体而言,𝑀𝑃𝑈𝑛→𝑚(𝐻𝑚,𝐻𝑛)MPUn→m(Hm,Hn)的计算如下:

其中LNLN表示层归一化,FFN是Transformer中的位置前馈网络。𝑀𝑃𝑈𝑚→𝑛(𝐻𝑛,𝐻𝑚)MPUm→n(Hn,Hm)可以以类似的方式公式化。
- 多模态融合策略:基于MPU,作者现在以渐进的方式描述三种多模态融合策略,并对它们的计算复杂度进行分析。需要注意的是,第三种融合策略(图1)在EMT中被默认采用,作者将其在消融研究中的经验比较留在第五节(V-B节)。为简化起见,作者仅展示了从𝑖i层到𝑖+1i+1层的信息流。假设输入特征序列为𝐻𝑚[0]=𝐻𝑚+𝑃𝐸𝑚∈𝑅𝑇𝑚×𝑑Hm[0]=Hm+PEm∈RTm×d,相应的语句级表示为ℎ𝑚[0]=ℎ𝑚∈𝑅𝑑hm[0]=hm∈Rd,其中𝑚∈{𝑙,𝑎,𝑣}m∈{l,a,v},𝑃𝐸𝑚∈𝑅𝑇𝑚×𝑑PEm∈RTm×d为标准Transformer中的正弦位置嵌入。
3. 预测模块
在多模态融合之后,作者将EMT中最终的全局多模态上下文(即 𝐺[𝐿]G[L])的时间维度展开,得到语句级别的跨模态表示 𝑔∈𝑅3𝑑g∈R3d。接着,作者将 𝑔g 与语句级别的各单模态表示 ℎ𝑚hm(𝑚∈{𝑙,𝑎,𝑣}m∈{l,a,v})进行拼接,最后通过多层感知机(MLP)得到情感预测值 𝑦y。作者使用L1损失作为预测损失函数,即:
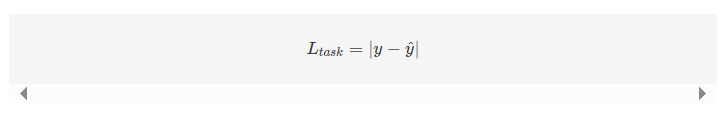
三、数据集介绍
1. 多模态情感计算数据集:
- CMU-MOSI: CMU-MOSI数据集是MSA研究中流行的基准数据集。该数据集是YouTube独白的集合,演讲者在其中表达他们对电影等主题的看法。MOSI共有93个视频,跨越89个远距离扬声器,包含2198个主观话语视频片段。这些话语被手动注释为[-3,3]之间的连续意见评分,其中-3/+3表示强烈的消极/积极情绪;
- CMU-MOSEI: CMU-MOSEI数据集是对MOSI的改进,具有更多的话语数量,样本,扬声器和主题的更大多样性。该数据集包含23453个带注释的视频片段(话语),来自5000个视频,1000个不同的扬声器和250个不同的主题
- SIMS/SIMSV2: CH-SIMS数据集是一个中文多模态情感分析数据集,为每种模态提供了详细的标注。该数据集包括2281个精选视频片段,这些片段来自各种电影、电视剧和综艺节目,每个样本都被赋予了情感分数,范围从-1(极度负面)到1(极度正面);
3. 多模态抑郁检测数据集:
- AVEC2019: AVEC2019 DDS数据集是从患者临床访谈的视听记录中获得的。访谈由虚拟代理进行,以排除人为干扰。与上述两个数据集不同的是,AVEC2019中的每种模态都提供了几种不同的特征。例如,声学模态包括MFCC、eGeMaps以及由VGG和DenseNet提取的深度特征。在之前的研究中,发现MFCC和AU姿势分别是声学和视觉模态中两个最具鉴别力的特征。因此,为了简单和高效的目的,作者们只使用MFCC和AU姿势特征来检测抑郁症。数据集用区间[0,24]内的PHQ-8评分进行注释,PHQ-8评分越大,抑郁倾向越严重。该基准数据集中有163个训练样本、56个验证样本和56个测试样本。
六、性能展示
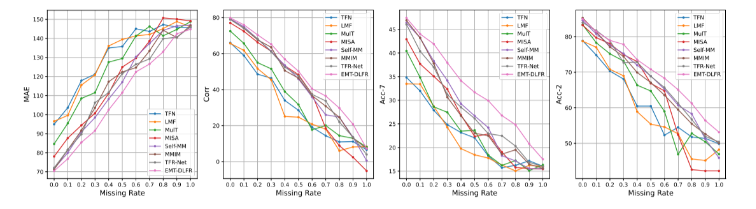
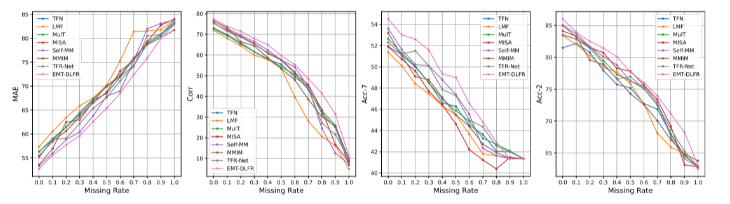
- 在情感计算任务中,作者们的模型性能有了明显提升,证明了其有效性;
MOSI:
MOSEI:
SIMS:
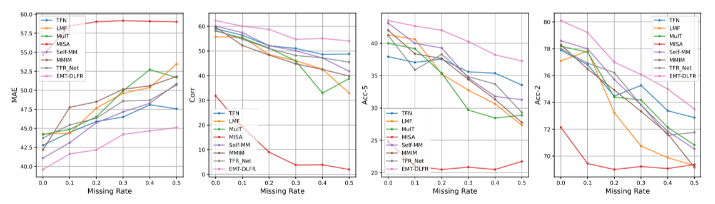
AVEC2019:
| Model | CCC | MAE |
| Baseline | 0.111 | 6.37 |
| EF | 0.34 | – |
| Bert-CNN & Gated-CNN | 0.403 | 6.11 |
| Multi-scale Temporal Dilated CNN | 0.430 | 4.39 |
| Proposed | 0.472 | 3.96 |
六、实现过程
在下载附件并准备好数据集并调试代码后,进行下面的步骤,附件已经调通并修改,可直接正常运行;
1. 数据集准备
下载附件中多种数据集已提取好的特征文件。把它放在"./dataset”目录。
2. 下载需要的包
pip install MMSA3. 进行训练
from MMSA import MMSA_run
# run LMF on MOSI with default hyper parameters
MMSA_run('EMT-DLFR', 'mosi', seeds=[6758], is_tune=False, gpu_ids=[0], config_file="../config/config_regression.json",
model_save_dir="../saved_models", res_save_dir="../saved_results")七、运行过程
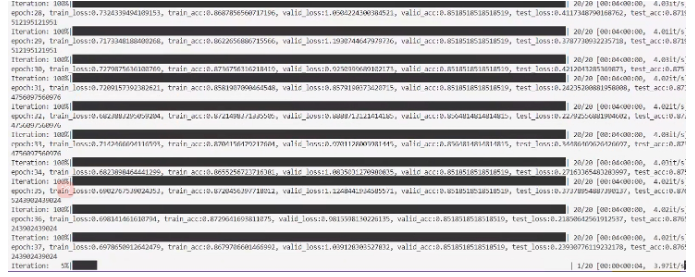
- 训练过程
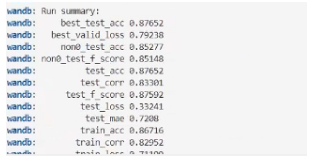
2.最终结果
成功的路上没有捷径,只有不断的努力与坚持。如果你和我一样,坚信努力会带来回报,请关注我,点个赞,一起迎接更加美好的明天!你的支持是我继续前行的动力!"
"每一次创作都是一次学习的过程,文章中若有不足之处,还请大家多多包容。你的关注和点赞是对我最大的支持,也欢迎大家提出宝贵的意见和建议,让我不断进步。"
神秘泣男子




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











