






在MongoDB中结合爬虫、数据存储和数据分析是一个常见的流程,用于从互联网上收集数据、存储到数据库中,并对这些数据进行各种分析和查询。下面,我将简要概述这个流程,并提供一些关键理论和代码示例。
1. 爬虫(Scraping)
爬虫用于从网站上抓取数据。你可以使用Python的requests库来发送HTTP请求,并使用BeautifulSoup或Scrapy等库来解析HTML内容。
示例代码(使用requests和BeautifulSoup):
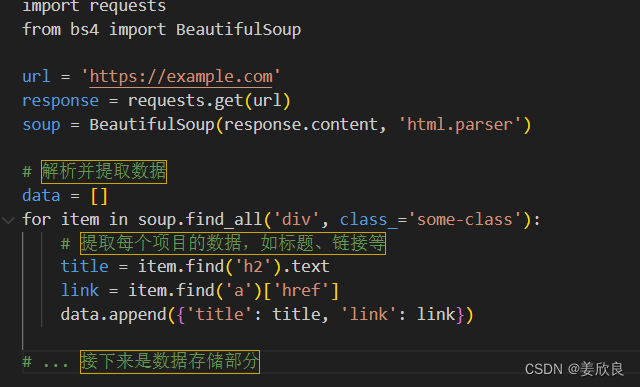
python
| import requests | |
| from bs4 import BeautifulSoup | |
| url = 'https://example.com' | |
| response = requests.get(url) | |
| soup = BeautifulSoup(response.content, 'html.parser') | |
| # 解析并提取数据 | |
| data = [] | |
| for item in soup.find_all('div', class_='some-class'): | |
| # 提取每个项目的数据,如标题、链接等 | |
| title = item.find('h2').text | |
| link = item.find('a')['href'] | |
| data.append({'title': title, 'link': link}) | |
| # ... 接下来是数据存储部分 |
2. 数据存储(MongoDB)
MongoDB是一个NoSQL数据库,非常适合存储非结构化或半结构化数据。你可以使用Python的pymongo库来与MongoDB交互。
示例代码(使用pymongo):
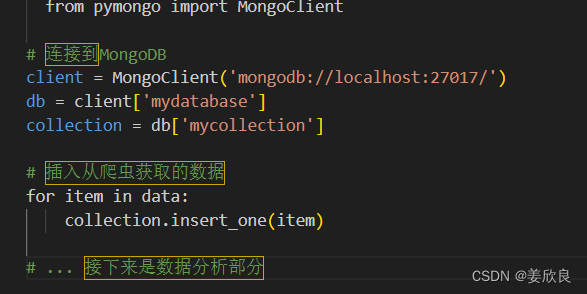
python
| from pymongo import MongoClient | |
| # 连接到MongoDB | |
| client = MongoClient('mongodb://localhost:27017/') | |
| db = client['mydatabase'] | |
| collection = db['mycollection'] | |
| # 插入从爬虫获取的数据 | |
| for item in data: | |
| collection.insert_one(item) | |
| # ... 接下来是数据分析部分 |
3. 数据分析
数据分析可以从简单的聚合查询到复杂的MapReduce操作,甚至使用MongoDB的Aggregation Pipeline。
示例代码(使用MongoDB的聚合管道):
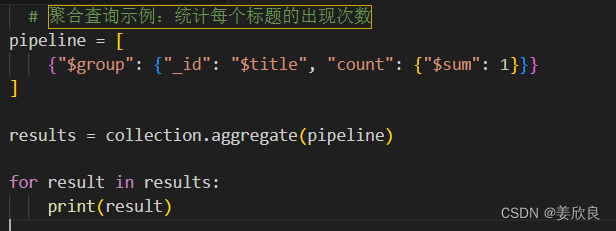
python
| # 聚合查询示例:统计每个标题的出现次数 | |
| pipeline = [ | |
| {"$group": {"_id": "$title", "count": {"$sum": 1}}} | |
| ] | |
| results = collection.aggregate(pipeline) | |
| for result in results: | |
| print(result) |
4. 数据处理分析理论
- 数据清洗:在存储之前,你可能需要清洗数据,如去除HTML标签、特殊字符、转换为统一的日期格式等。
- 数据规范化:将数据转换为一致的格式和结构,以便于分析。
- 索引优化:为常用的查询字段创建索引,以加快查询速度。
- 聚合分析:使用MongoDB的聚合管道对数据进行分组、排序、过滤等操作,以获得有意义的摘要和统计数据。
- 数据挖掘与机器学习:将数据存储到MongoDB后,你可以使用其他工具或库(如scikit-learn、TensorFlow等)进行数据挖掘和机器学习分析。
注意事项:
- 爬虫伦理:在编写爬虫时,请确保遵守网站的
robots.txt文件,并尊重网站的带宽和服务。 - 数据隐私和版权:确保你收集的数据不涉及隐私泄露,并且你有权访问和使用这些数据。
- 性能优化:对于大型数据集,考虑使用MongoDB的分片、复制和其他性能优化技术。
- 安全性:保护你的MongoDB实例免受未授权访问的侵害,使用身份验证、授权和防火墙等措施。
5.在MongoDB中结合爬虫、数据存储和数据分析通常涉及多个步骤和工具
下面是一个简化的概述,包括使用Python的示例代码片段,这些代码片段展示了如何执行这些任务。请注意,这只是一个基本的示例,实际的实现可能会根据您的具体需求和目标而有所不同。
5.1 爬虫 (使用Python的requests和BeautifulSoup库)
首先,我们需要一个爬虫来从网站上抓取数据。这里我们假设您要抓取一个包含文章列表的网页,并且每个文章都有一个标题和URL。
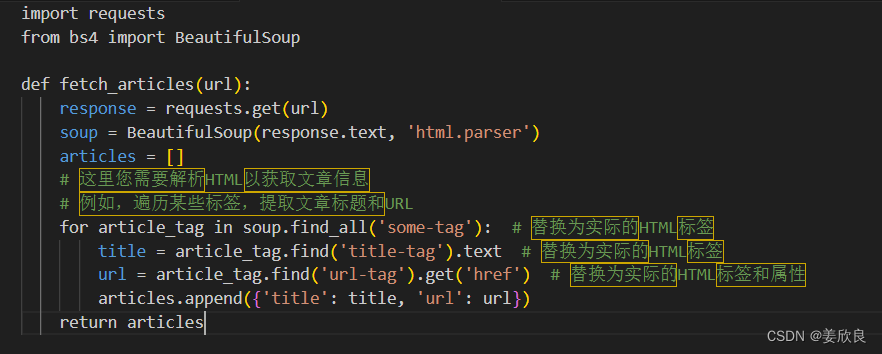
python
| import requests | |
| from bs4 import BeautifulSoup | |
| def fetch_articles(url): | |
| response = requests.get(url) | |
| soup = BeautifulSoup(response.text, 'html.parser') | |
| articles = [] | |
| # 这里您需要解析HTML以获取文章信息 | |
| # 例如,遍历某些标签,提取文章标题和URL | |
| for article_tag in soup.find_all('some-tag'): # 替换为实际的HTML标签 | |
| title = article_tag.find('title-tag').text # 替换为实际的HTML标签 | |
| url = article_tag.find('url-tag').get('href') # 替换为实际的HTML标签和属性 | |
| articles.append({'title': title, 'url': url}) | |
| return articles |
5.2数据存储 (使用Python的pymongo库)
接下来,我们将使用pymongo库将爬虫获取的数据存储在MongoDB数据库中。
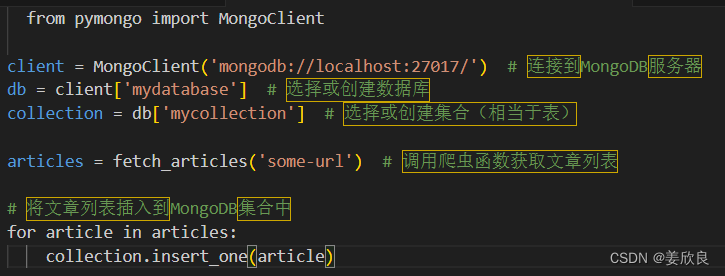
python
| from pymongo import MongoClient | |
| client = MongoClient('mongodb://localhost:27017/') # 连接到MongoDB服务器 | |
| db = client['mydatabase'] # 选择或创建数据库 | |
| collection = db['mycollection'] # 选择或创建集合(相当于表) | |
| articles = fetch_articles('some-url') # 调用爬虫函数获取文章列表 | |
| # 将文章列表插入到MongoDB集合中 | |
| for article in articles: | |
| collection.insert_one(article) |
5.3 数据分析 (使用MongoDB的聚合管道或Python的pandas库)
一旦数据被存储在MongoDB中,您可以使用MongoDB的聚合管道进行复杂的数据分析,或者使用Python的pandas库将数据导出到pandas DataFrame中进行进一步分析。
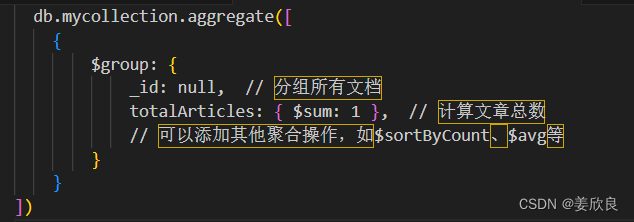
使用MongoDB聚合管道 (在MongoDB shell或MongoDB Compass中执行)

javascript
| db.mycollection.aggregate([ | |
| { | |
| $group: { | |
| _id: null, // 分组所有文档 | |
| totalArticles: { $sum: 1 }, // 计算文章总数 | |
| // 可以添加其他聚合操作,如$sortByCount、$avg等 | |
| } | |
| } | |
| ]) |
使用Python和pandas
首先,从MongoDB导出数据到pandas DataFrame:
python
| import pandas as pd | |
| # 使用pymongo的find方法获取所有数据,并转换为列表的字典形式 | |
| all_articles = list(collection.find({}, {'_id': 0})) # 不包括_id字段 | |
| # 将数据转换为pandas DataFrame | |
| df = pd.DataFrame(all_articles) | |
| # 现在可以使用pandas进行各种数据分析操作 | |
| print(df.describe()) # 显示数据摘要统计信息 |
请注意,上述代码示例仅用于说明目的。在实际应用中,您可能需要处理更复杂的HTML结构、网络请求错误、数据库连接问题、数据清洗和转换等。此外,对于大规模的数据集和高并发的应用,您可能还需要考虑使用异步I/O、连接池、索引优化等技术来提高性能和可扩展性。
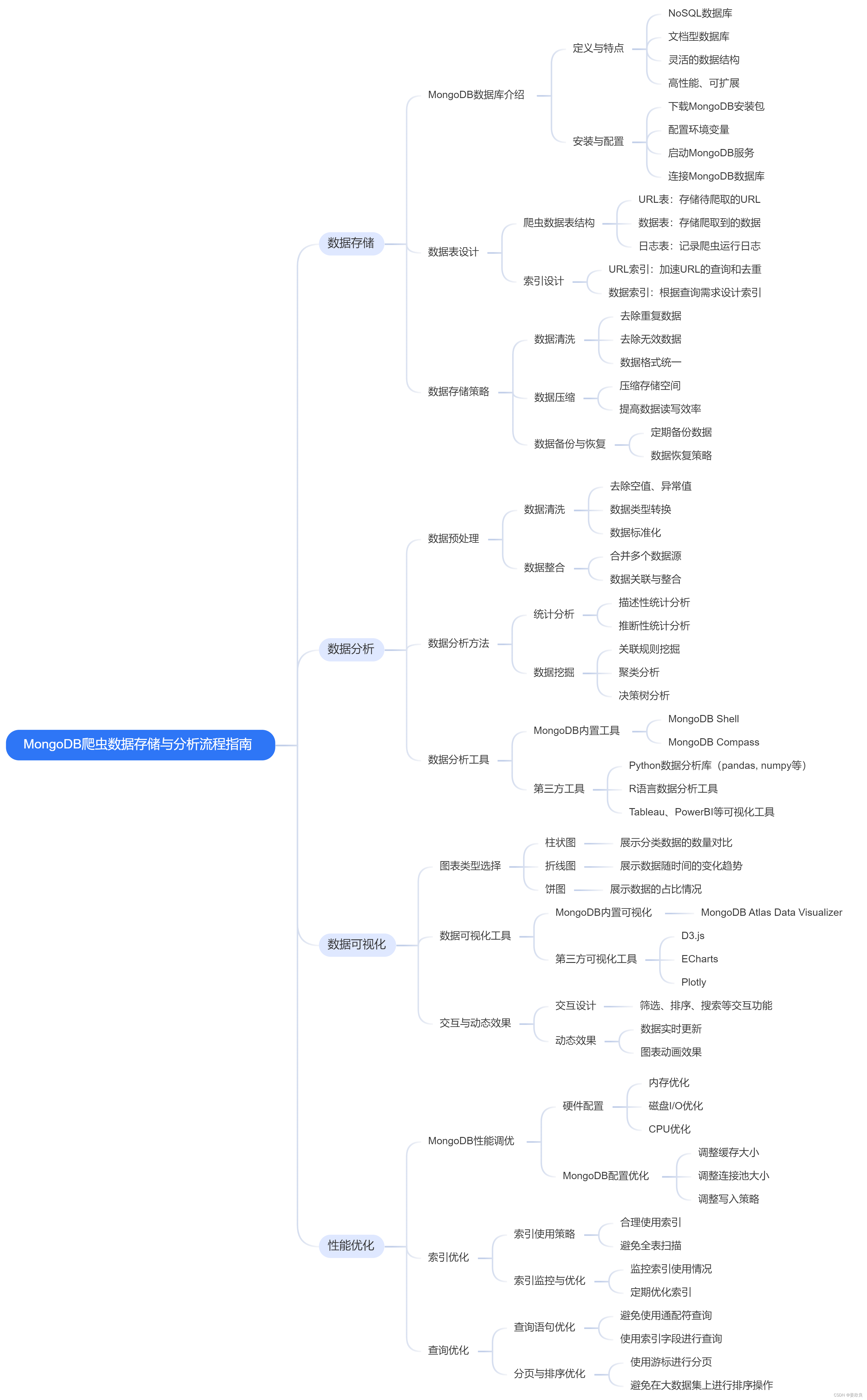
6.以下是MongoDB爬虫数据存储与分析流程的思维导图















 884
884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









