







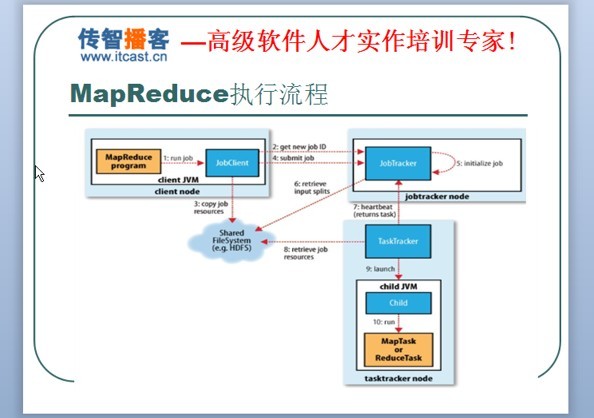
对于MapReduce这张图是相当经典的,在网上看到很多谈到MapReduce的执行过程都会用到这张图片,下面我也讲讲自己对它的基础认识。
1,用户向jobclient提交MapReduce job。
2,jobclient向Jobtracker申请一个新的job id(通过调用jobtracker的getnewjobid()获得)。
3,将运行job所需的资源(Jar包,配置文件与计算所得的输入划分)copy到共享文件系统(share Filesystem)中,这此之前会判断MapReduce job 传参,如input dir与output dir 是否存在等等。
4,向Jobtracker提交作业。
5,提交成功后,将此job加入到作业队列,交由作业调度器进行调度,并对其初始化,初始化首先创建一个对象来封装job运行的tasks, status以及progress。
6,job调度器从share Filesystem获取此job的input splits。
7,Jobtracker通过与Tasktracker之间的heartbeat(心跳,是Tasktracker用于告之Jobtracker是否还存放有及传输信息用的),让Jobtracker选取相应的Tasktracker来执行job。
8,收到执行job的Tasktracker向share Filesystem获取执行job所需的相应资源。
9,Tasktracker会新建一个TaskRunner实例(JVM)来运行任务,child JVM与Tasktracker之间通过通信来告之执行进度。
这是我理解的MapReduce,很基础。希望获得高手们跟贴指点交流!















 3004
3004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









