







一个MapReduce任务就是一个Job。Job分为2个阶段:
Map
和
Reduce
Map函数接收一个
<key,value>形式的输入,然后产生一个
<key,value>形式的中间输出,Hadoop会把相同中间Key值的value集合在一起传给reduce函数。
reduce 函数接收<key,(list of values)> 形式的输入,然后对values集合进行处理,输出
<key,value>形式。
一个MapReduce Job 包括:输入数据,MapReduce程序和配置信息(
Configuration
)。Hadoop将 Job 分成多个 tasks :
map tasks
和
reduce tasks
。
Hadoop集群中有两类节点,一个jobtracker 和多个tasktrackers。
Hadoop 对 【输入数据分片】,为每个分片创建一个map task。大多数情况下,分片大小与HDFS中块大小一致。
Map 任务在每个数据节点上运行。Map 将中间结果保存在本地文件系统中。
如果只有一个reduce task,map task 的输出经过排序处理,发送到运行 reduce task的节点。
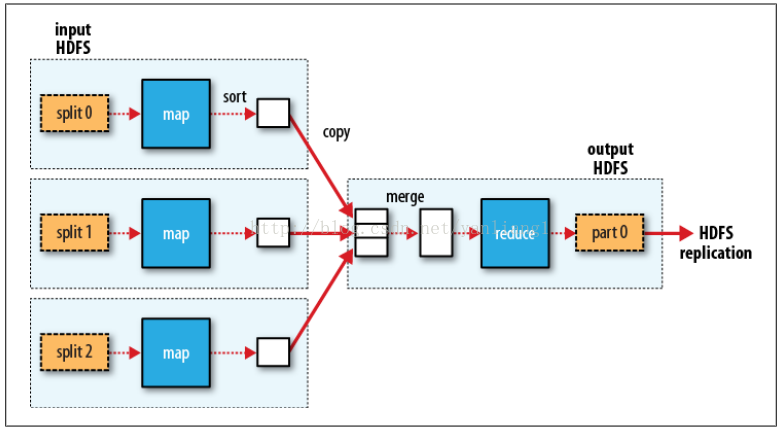
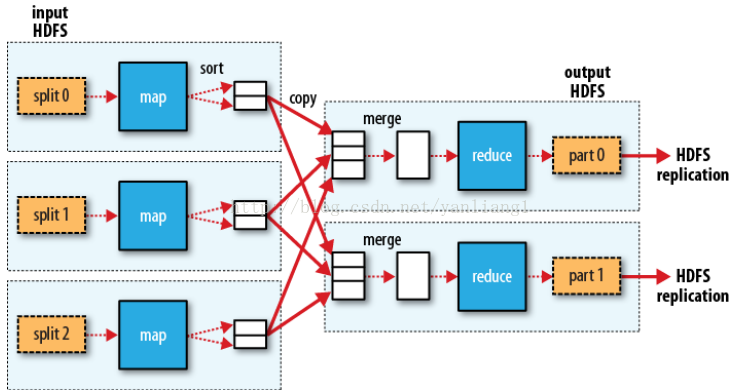
如果有
多个reduce task,map task 会对输出进行
partition
。
一个分区
对应
一个reduce 任务。Map 的中间结果会分配到分区中,相同Key的输出在一个分区中。可以自定义分区函数,默认是哈希分区算法。















 1778
1778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









