







流行的机器学习应用模式与算法
本文将围绕机器学习的概念,尽可能归纳总结当前流行的机器学习应用模式及相关算法。
“对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么我们称这个计算机程序在从经验E学习。”
机器学习的各类算法之间,重叠交叉又各自不同,既然是从软件工程的角度来写,我们会先介绍机器学习算法所依存的框架,再在这个框架下介绍有哪些算法,算法详情不做介绍,只力图说明这些算法用来做什么。
矩阵范式
这是现在主流的机器学习应用框架,我这里姑且给它命名为矩阵范式,它的核心思想是把问题映射为矩阵,用机器学习算法学习矩阵,再将模型预测出的矩阵映射为问题的解决方案。
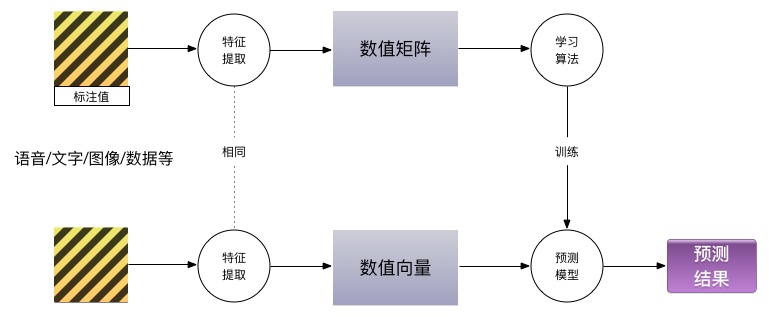
1.描述问题。
2.样本表达,收集并标注 x-y 形式的样本。x表示已知元素,y表示预测的元素,y可以为空。它们合并起来,是样本集 X-Y
3.设计特征提取方案,把每个X中的样本x映射为相同维度的向量vx,合并即矩阵MX,y映射为向量vy,合并为矩阵MY。
4.使用基于矩阵输入的机器学习算法,得到基于MX预测MY的模型M。
5.预测时,先提取特征,再套用模型预测MY,最后将MY反映射为Y。
图像识别的示例:
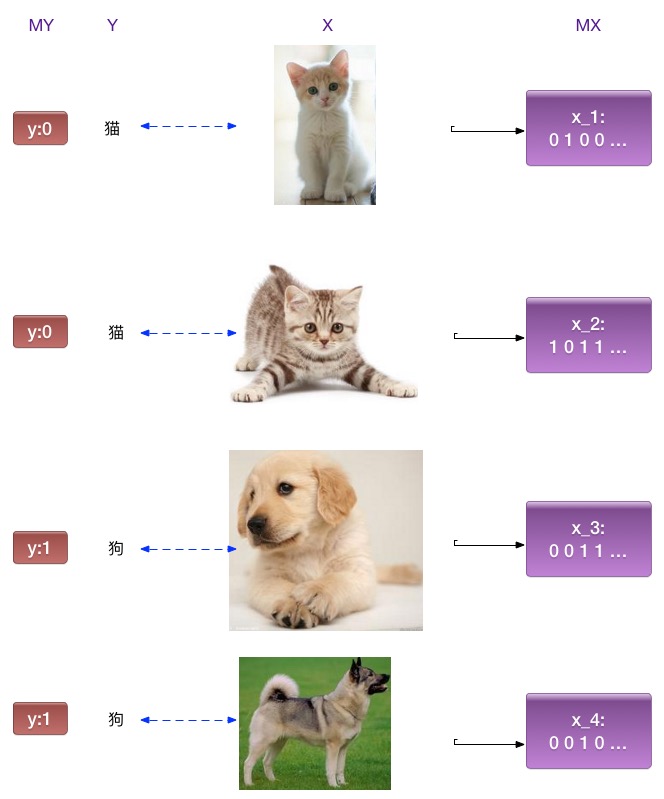
应用场景
人脸识别、图像识别、欺诈分析、文本识别、推荐系统、天气预测、医疗用于各类拟合预测、金融高频交易等等,目前企业用到机器学习算法的,经常制造新闻博人眼球的,基本上都是这个范式。
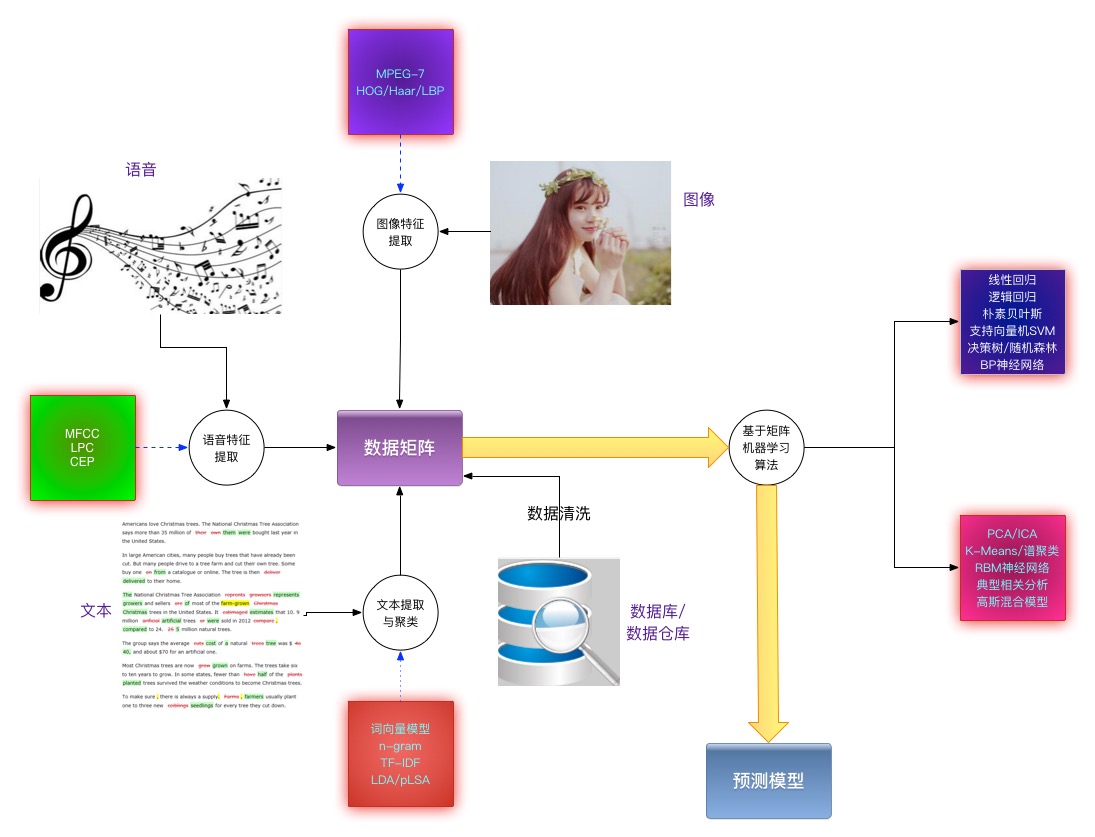
具体实现
这个范式下,可分为浅层学习(由于深度学习的兴起而变成了“浅层”)和深度学习两种具体实现:
浅层学习
着重于特征提取这一步,设计特征是最繁琐困难的工作。后续的学习算法基本上固定。
深度学习
简化特征提取(比如图像识别,只需要固定到某一个大小,然后把像素全部输入),着重学习算法(具体来说是一系列的神经网络,最后一层加个逻辑回归/SVM之类的监督学习算法)的拼合设计。它实际上是用无监督算法对特征进行预处理,得到新的特征之后,再做监督学习,因此也被称为让计算机去自动学习特征。
注:从软件工程的角度看,深度学习只是矩阵范式的一种表现形式,而非一种单独的算法,RBM、Auto-Encoding、CNN这些才能叫学习算法。
基于矩阵输入的机器学习算法
python 的机器学习工具包scikit-learn,把机器学习学习算法分为分类、回归、聚类、降维四大类,这个工具包里面的算法,基本上都是基于矩阵输入的。
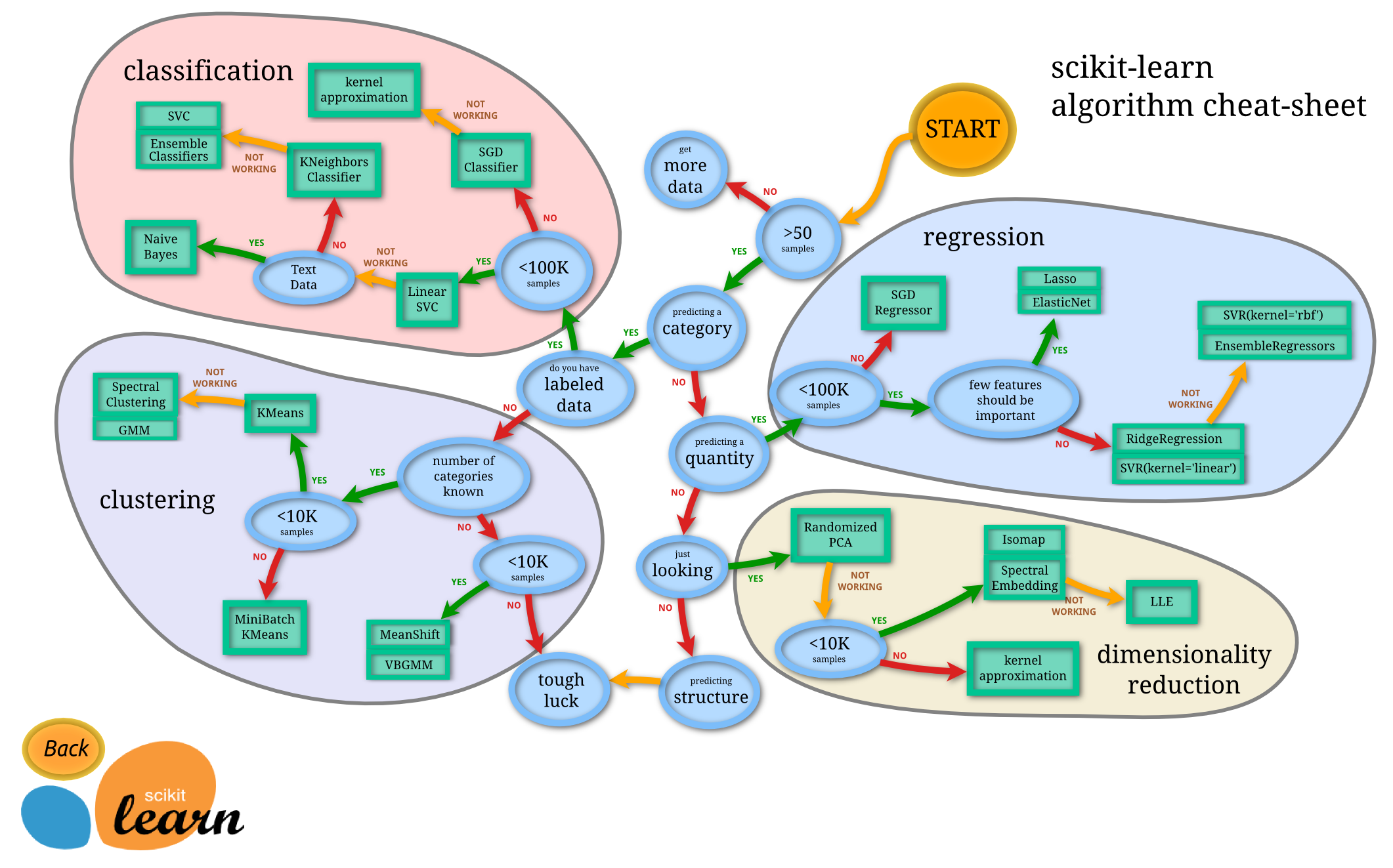
由于Java有接口和类这个语法,有类型要求但不用纠结指针,描述问题方便一些,因此下面用Java代码作下示意。
所有机器学习算法,最终需要获得这么一个模型类:
public interface Model {
public Matrix vPredict(Matrix X);
};这个模型的作用是把一个矩阵X,转变为与之同高但不一定同宽的另一个矩阵。
矩阵Matrix数据每一行是一条样本,此外Matrix中包含一个 meta 的成员变量,用来描述每一列的数据是离散值还是连续值。(底层存储往往是列存或压缩的,但这没关系,理解意思就行)。
监督学习
这类学习算法需要实现如下接口:
public interface SupervisedLearning{
public Model vTrain(Matrix X, Matrix Y);/*X.height() == Y.height()*/
};回归
1、线性回归
2、分类回归树(CART,Classification And Regression Tree)
3、BP神经网络
4、符号回归
分类
1、贝叶斯网络
2、K近邻算法KNN
3、支持向量机SVM
注:去给机器学习/数据挖掘方向的人做面试,SVM确实是最适合问的一个算法,这一个算法几乎就把机器学习的全部步骤涵盖进来了:核函数变换、梯度下降、二次规划、交叉验证、网络搜索。
4、决策树
5、逻辑回归
修饰算法
之所以叫修饰算法,是指这类算法是一种聚合算法,可以由上面所述的分类/回归算法按一定规则生成新的算法。
在写代码时,我们应当是实现一个工厂,由原先的监督学习算法创建新的算法:
public interface AlgorithmFactory{
public SupervisedLearning vGenerate(SupervisedLearning origin);
};1、Boost/AdaBoost
2、随机森林
在绝大多数的文献和大部分的开源代码库实现中,这些算法都是以决策树为原始算法的。不过为了可扩展起见,还是建议是写一个工厂,将原始监督学习算法扩充而来。
无监督学习
在实际工作情况下,标注样本是非常耗人力的工作,为了利用浩如烟海的无标注样本,无监督学习还是很有用武之地的。它的作用一般在于预处理,生成新的特征。
public interface UnSupervisedLearning{
Model vTrain(Matrix X);
};无监督学习所得的Model,一般用于对数据作预处理。
聚类
1、K-Means
2、高斯混合模型 GMM
降维/特征提取
1、流形学习
2、主成分分析PCA(尽管PCA可以说是流形学习的一种,但研究流形学习的人应该不屑于提PCA吧)
3、RBM神经网络
4、自动编码器
基于时间序列的机器学习算法
在语音识别、语义识别、视频分析以及股价预测中,我们会遇到动态数据,
对于这种时间序列/动态数据的输入,可以将其扩展为矩阵,套用基于矩阵的机器学习的算法,但也有一些特殊算法就是基于时间序列而设计的,如:
1、隐马尔可夫模型HMM
2、条件随机场CRF
3、递归神经网络RNN
4、滑动平均模型MA
注:AR自回归模型就是先扩展为矩阵,再套用线性回归,因此不列进来。
尽管理论上,它们可以处理任意的回溯深度,但在实际应用中,出于效率考虑,往往都会限制回溯深度,因此这些算法归根结底还是基于矩阵的机器学习算法。
其他学习算法
遗传规划/自动编程
Genetic Programming 的目标是自动生成计算机程序,这个学习过程一般来说就没办法用矩阵范式描述了。比如用 GP 生成 sql 语句来作数据挖掘。(A Genetic Programming Framework for Two Data Mining Tasks: Classification and Generalized Rule Induction.)
参数优化算法
遗传算法/粒子群算法/梯度下降/EM算法往往也被列进机器学习算法,但从工程角度而言,它们是机器学习算法中所用到的参数优化算法,并不是一种学习算法。
参考资料
介绍Haar特征比较详细的一篇文章:
http://blog.sina.com.cn/s/blog_4e6680090100d2sd.html
介绍词向量的一篇文章:
http://blog.csdn.net/zhoubl668/article/details/23271225
介绍典型相关分析的文章:
http://blog.csdn.net/statdm/article/details/7585113
流形学习:
http://www.cnblogs.com/tornadomeet/archive/2012/03/29/2422878.html
主成分分析PCA:
http://www.cnblogs.com/jerrylead/archive/2011/04/18/2020209.html















 1620
1620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









