









文章主页:http://www.cs.toronto.edu/polyrnn/
1 简介:

文章作者基于深度学习提出一种半自动目标事例标注(semi-automatic annotation of object instances)的算法。大多数前人是将目标分割看作是像素级别的标注问题(pixel-labeling)问题,但是文章作者是将其看做是一个多边形预测的任务(polygon prediction)。两者区别如下(本人自己注释,左图为像素级分割,右侧是多边形标注):

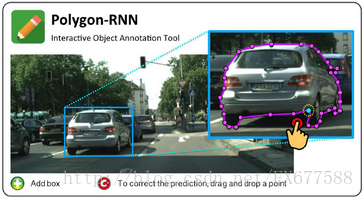
当前大多数语义图像分割算法是基于深度学习的方式,但是深度学习的效果很大程度上依赖于大量的训练数据,这就造成圈内人士需要花费很大的人力物力和时间去手动标注大规模训练数据集。这篇文章的目标正是为了加快标注精度很高的真值(ground truth)。
那这篇文章为何称为半自动目标事例标注呢?这是因为以下两点:
①、这篇文章算法首先需要给定一个bounding box真值,然后使用一个RNN(Recurrent Neural Network),文中称为Polygon-RNN在这个目标框中画出目标一个多边形圈住的轮廓。因为相比较手动标注目标轮廓,bounding box标注只要两下鼠标点击即可,容易很多(见上方右图)。
②、算法标注轮廓过程,人为可干预从而产生更精确的标注结果。这块细节下文再仔细介绍过程。
2 Polygon-RNN:
2.1 介绍
我们再来好好总结一下整个过程,作者是想创建一个有效的标注工具(annotation tool),从而以多边形形式标注目标事例。当给定bounding box中的图像块(image patch),文章算法基于RNN可以预测一个封闭的多边形来圈出目标的轮廓。多边形设计方法就是先找到一个起点,然后以顺时针方式连续生成多边形的其他顶点,顺序连接所有顶点即形成这个圈出目标轮廓的多边形。
模型是一个RNN,每一次迭代预测一个多边形顶点。RNN每一次迭代的输入it
Γ
(
n
)
=
(
n
−
1
)
!
∀
n
∈
N
,依一个特殊方向形成多边形;第三是起点,帮助RNN决定何时封闭多边形。整个网络框架如下图:
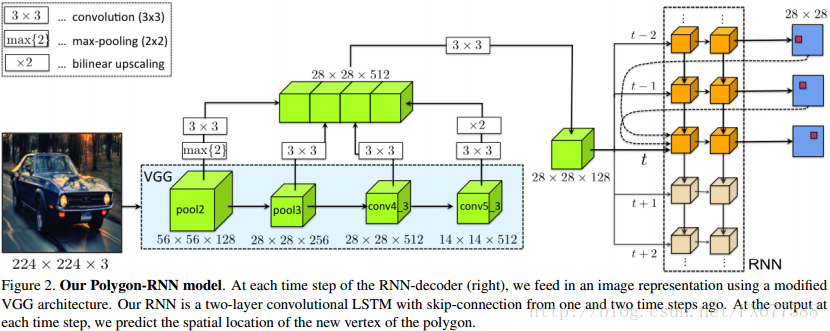
网络是端到端(end-to-end)训练RNN+CNN,其中关键是帮助CNN能够微调(fine-tuned)来预测目标边界,并且帮助RNN从这些边界学习来利用其循环特性编码目标形状。
2.2 CNN形成图片特征表示
文章使用一个VGG-16结构表示图片特征,首先移除全连接层和最后的max-pooling层pool5,然后通过上采样和max-pooling统一跳跃连接VGG不同层的尺寸,形成一个28*28*512串联特征。最后是一个卷积层结合ReLu处理整个串联特征从而形成最终图片特征表示28*28*128,如上图绿色部分。
2.3 RNN预测顶点
RNN网络可以在迭代过程中,通过线性和非线性方程携带复杂的历史信息,正是从这点考虑作者希望通过RNN来依次预测出多边形的顶点。文中RNN使用的是一个ConvolutionalLSTM框架,详细来说,作者设计了一个核为3*3和16通道的两层ConvLSTM框架,然后在每一步迭代就输出一个顶点yt ( t h i s ) . t e x t ( ) . s p l i t ( ′ \n ′ ) . l e n g t h ; v a r 计算如下:

当给定两个连续的顶点,下一个多边形顶点则是唯一的了。但是这个情况不能应用在第一个顶点,因为多边形任意顶点可以看做是起点,多边形是一个循环体。所以作者特别对待起始顶点。怎么对待的说实话这块我还没看懂。
2.4 训练
我们使用RNN的每次迭代的交叉熵(cross-entropy)去训练模型,为了不过于惩罚接近真值顶点的不准确的预测,每一次迭代都平滑目标分布。作者给真值距离很近的位置也分配一个非零概率。
训练的时候还是做出每一步的预测,但是是将真值顶点输入到下一个迭代。但是对于起始顶点的预测是利用多任务loss训练另一个CNN。作为目标边界的真值,作者画出真值多边形的边,然后使用多边形的顶点作为真值的顶点层。
2.5 预测与循环中人为矫正
模型预测阶段,在RNN每一步得到最高概率分数的顶点。此外标注着可以在每一步纠正预测。我们可以输入人为纠正的顶点到RNN下一步,然后让模型返回到正确的划分道路上。正常情况下,一个目标圈出轮廓仅需要250ms。
实验质量上结果如下:

个人学习记录,由于能力和时间有限,如果有错误望读者纠正,谢谢!
转载请注明出处:CSDN 无鞋童鞋。
- ').addClass('pre-numbering').hide(); (this).addClass(′has−numbering′).parent().append( ( t h i s ) . a d d C l a s s ( ′ h a s − n u m b e r i n g ′ ) . p a r e n t ( ) . a p p e n d ( numbering); for (i = 1; i
快捷键
- 加粗
Ctrl + B - 斜体
Ctrl + I - 引用
Ctrl + Q - 插入链接
Ctrl + L - 插入代码
Ctrl + K - 插入图片
Ctrl + G - 提升标题
Ctrl + H - 有序列表
Ctrl + O - 无序列表
Ctrl + U - 横线
Ctrl + R - 撤销
Ctrl + Z - 重做
Ctrl + Y
Markdown及扩展
Markdown 是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档,然后转换成格式丰富的HTML页面。 —— [ 维基百科 ]
使用简单的符号标识不同的标题,将某些文字标记为粗体或者斜体,创建一个链接等,详细语法参考帮助?。
本编辑器支持 Markdown Extra , 扩展了很多好用的功能。具体请参考Github.
表格
Markdown Extra 表格语法:
| 项目 | 价格 |
|---|---|
| Computer | $1600 |
| Phone | $12 |
| Pipe | $1 |
可以使用冒号来定义对齐方式:
| 项目 | 价格 | 数量 |
|---|---|---|
| Computer | 1600 元 | 5 |
| Phone | 12 元 | 12 |
| Pipe | 1 元 | 234 |
定义列表
-
Markdown Extra 定义列表语法:
项目1
项目2
- 定义 A
- 定义 B 项目3
- 定义 C
-
定义 D
定义D内容
代码块
代码块语法遵循标准markdown代码,例如:
@requires_authorization
def somefunc(param1='', param2=0):
'''A docstring'''
if param1 > param2: # interesting
print 'Greater'
return (param2 - param1 + 1) or None
class SomeClass:
pass
>>> message = '''interpreter
... prompt'''脚注
生成一个脚注1.
目录
用 [TOC]来生成目录:
数学公式
使用MathJax渲染LaTex 数学公式,详见math.stackexchange.com.
- 行内公式,数学公式为: Γ(n)=(n−1)!∀n∈N Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N 。
- 块级公式:
更多LaTex语法请参考 这儿.
UML 图:
可以渲染序列图:
或者流程图:
离线写博客
即使用户在没有网络的情况下,也可以通过本编辑器离线写博客(直接在曾经使用过的浏览器中输入write.blog.csdn.net/mdeditor即可。Markdown编辑器使用浏览器离线存储将内容保存在本地。
用户写博客的过程中,内容实时保存在浏览器缓存中,在用户关闭浏览器或者其它异常情况下,内容不会丢失。用户再次打开浏览器时,会显示上次用户正在编辑的没有发表的内容。
博客发表后,本地缓存将被删除。
用户可以选择 把正在写的博客保存到服务器草稿箱,即使换浏览器或者清除缓存,内容也不会丢失。
注意:虽然浏览器存储大部分时候都比较可靠,但为了您的数据安全,在联网后,请务必及时发表或者保存到服务器草稿箱。
浏览器兼容
- 目前,本编辑器对Chrome浏览器支持最为完整。建议大家使用较新版本的Chrome。
- IE9以下不支持
- IE9,10,11存在以下问题
- 不支持离线功能
- IE9不支持文件导入导出
- IE10不支持拖拽文件导入
- 这里是 脚注 的 内容. ↩















 3505
3505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









