







一、eclipse+maven构建storm项目
前期准备JDK、IDEA、maven
创建maven项目
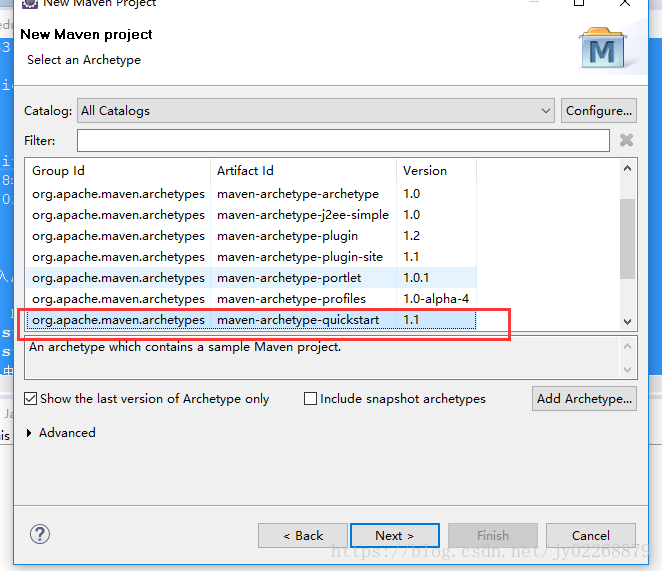
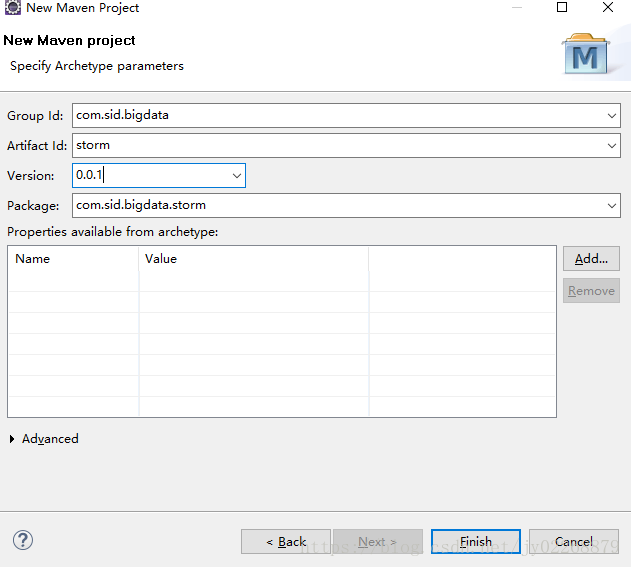
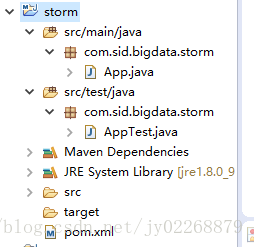
添加maven的storm依赖
打开官网:http://storm.apache.org/releases/1.1.2/index.html

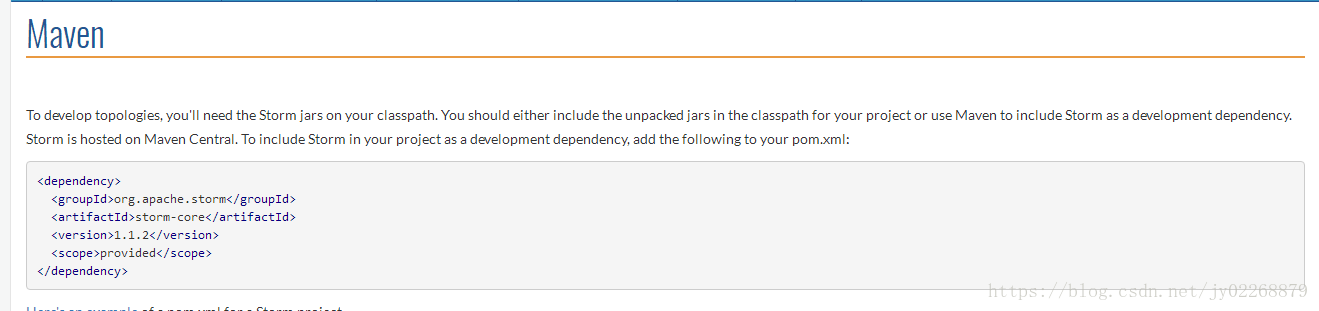
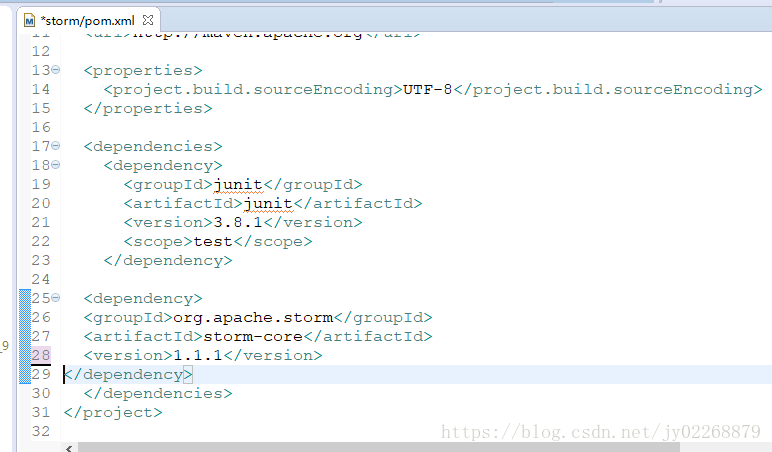
打开pom.xml文件
把官网的这个配置加进来,我这里用的是1.1.1
二、iSpout核心接口
1.概述
自己写的spout需要实现ISpout核心接口,spout负责发送数据(tuple)到拓扑(topology)中去处理,每一个tuple通过spout发送出去,storm将会跟踪整个DAG图保证可靠性。当storm发现每一个tuple在DAG里面都被成功处理了,它将会发送一个ACK的消息给spout。如果说某条tuple执行失败,可以通过org.apache.storm.Config配置一个timeout,storm将把这条失败的信息再发送给spout。
当一个spout发送出一个tuple的时候,它会给这个tuple添加message ID的标签。message ID可以是任意类型的。storm在ack 或者 fail一个消息的时候,会把这个消息ID回传来鉴别是哪个tuple。
storm会在同一个线程里面调用ack、fail、nextTuple方法。这意味着一个ISpout实现类并不需要担心并发问题,它是线程安全的。这也意味着我们需要确保ISpout实现类的nextTuple不是阻塞的。
2.核心方法

open方法。当task在worker上被初始化的时候会调用这个方法。

close方法。在这个方法中释放资源。

nextTuple方法。发送数据。当storm需要spout发射数据到output collector的时候,这个方法会被调用。这个方法不能被阻塞。如果spout没有发送任何数据,这个方法应该被返回。

ack方法传进来的是一个message id。消息处理成功storm会返回给spout一个成功的消息。
fail方法,消息处理失败storm会返回给spout一个失败的消息。
3.实现类
public abstract class BaseRichSpout extends BaseComponent implements IRichSpout
public interface IRichSpout extends ISpout, IComponent
public class DRPCSpout extends BaseRichSpout
public class ShellSpout implements ISpout
三、iComponent核心接口
1.概述
为topology中所有可能的组件提供公共方法。当我们用JAVA API定义topologies的时候这个接口会被使用。
2.核心方法

declareOutputFields方法。定义输出的规则。声明spout或者bolt发出的数据的名字。
3.实现类
public abstract class BaseComponent implements IComponent
四、iBolt核心接口
1.概述
一个Ibolt是一个组件,它接收tuple(数据),然后做数据处理,把处理后的数据再输出。它并不需要立刻处理数据,可以先接收数据,之后晚一点再处理。即是hold数据再处理。
bolt的声明周期:Ibolt对象在客户端的机器上面被创造,它序列化以后再提交到master(nimbus主节点)上去运行。nimbus启动worker,反序列化对象,调用prepare方法,然后才开始处理tuple。
2.核心方法

prepare方法。当task在worker上初始化的时候会被调用。它会提供bolt的运行时环境。

execute方法。它会处理每一个进来的tuple(数据)。Tuple对象包含了一些元数据,如component/stream/task(从哪儿来的之类的)。用getValue能访问到tuple的值。用OutputCollector可以把这个tuple再发射出去。

cleanup方法。清理资源。不一定会被调用,如果用kill -9,不保证这个方法会被调用。
3.实现类
public abstract class BaseRichBolt extends BaseComponent implements IRichBolt
public interface IRichBolt extends IBolt, IComponent
public class RichShellBolt extends ShellBolt implements IRichBolt
五、求和案例编程
需求
把spout发出的数字全部加起来算出结果。
实现方案
spout发出数字作为Input
bolt求和
结果打印到控制台
Topology设计
DatasourceSpout----->SumBolt
功能实现
package com.sid.bigdata.storm;
import java.util.Map;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
/**
* @author liyijie
* @date 2018年6月7日下午5:33:27
* @email 37024760@qq.com
* @remark
* @version
*
* 用storm实现累加求和的操作
*/
public class LocalSumStormTopology {
/**
* Spout需要继承BaseRichSpout
* 产生数据并且发送出去
* */
public static class DataSourceSpout extends BaseRichSpout{
private SpoutOutputCollector collector;
/**
* 初始化方法,在执行前只会被调用一次
* @param conf 配置参数
* @param context 上下文
* @param collector 数据发射器
* */
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
int number = 0;
/**
* 产生数据,生产上一般是从消息队列中获取数据
* */
public void nextTuple() {
this.collector.emit(new Values(++number));
System.out.println("spout发出:"+number);
Utils.sleep(1000);
}
/**
* 声明输出字段
* @param declarer
* */
public void declareOutputFields(OutputFieldsDeclarer declarer) {
/**
* num是上nextTuple中emit中的new Values对应的。上面发几个,这里就要定义几个字段。
* 在bolt中获取的时候,只需要获取num这个字段就行了。
* */
declarer.declare(new Fields("num"));
}
}
/**
* 数据的累计求和Bolt
* 接收数据并且处理
* */
public static class SumBolt extends BaseRichBolt{
/**
* 初始化方法,只会被执行一次
* */
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
int sum=0;
/**
* 获取spout发送过来的数据
* */
public void execute(Tuple input) {
//这里的num就是在spout中的declareOutputFields定义的字段名
//可以根据index获取,也可以根据上一个环节中定义的名称获取
Integer value = input.getIntegerByField("num");
sum+=value;
System.out.println("Bolt:sum="+sum);
}
/**
* 声明输出字段
* @param declarer
* */
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main (String[] args){
//本地模式,没有提交到服务器集群上,不需要搭建storm集群
LocalCluster cluster = new LocalCluster();
//TopologyBuilder根据spout和bolt来构建Topology
//storm中任何一个作业都是通过Topology方式进行提交的
//Topology中需要指定spout和bolt的执行顺序
TopologyBuilder tb = new TopologyBuilder();
tb.setSpout("DataSourceSpout", new DataSourceSpout());
//SumBolt以随机分组的方式从DataSourceSpout中接收数据
tb.setBolt("SumBolt", new SumBolt()).shuffleGrouping("DataSourceSpout");
//第一个参数是topology的名称,第三个参数是Topology
cluster.submitTopology("LocalSumStormTopology", new Config(), tb.createTopology());
}
}
六、词频统计案例编程
需求
读取指定目录的数据,实现单词计数功能。
实现方案
spout读取指定目录数据,作为后续bolt的input
bolt把Input的数据切割开,按照空格分开
bolt进行最终的单词数量统计,并输出。
Topology设计
DatasourceSpout----->SplitBolt----->CountBolt
功能实现
maven的pom文件中添加一个IO读写的工具类
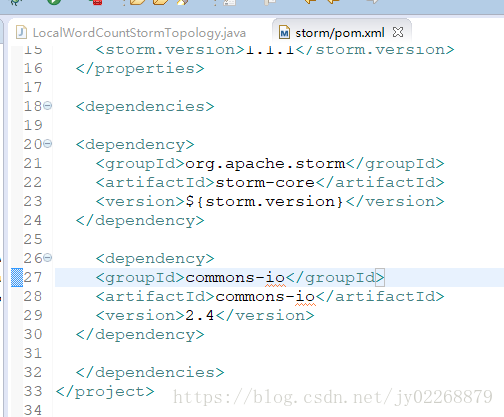
package com.sid.bigdata.storm.wordcount;
import java.io.File;
import java.io.IOException;
import java.util.Collection;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.shade.org.apache.commons.io.FileUtils;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* @author liyijie
* @date 2018年6月7日下午7:58:14
* @email 37024760@qq.com
* @remark
* @version
*
* 使用storm完成词频统计
*/
public class LocalWordCountStormTopology {
public static class DataSourceSpout extends BaseRichSpout{
private SpoutOutputCollector collector;
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
/**
* 1.读取指定目录的文件夹下的数据:F:\storm\wordcount.txt
* 2.把每一行数据发射出去
* */
@SuppressWarnings("deprecation")
public void nextTuple() {
//maven的pom文件中添加的IO读写的工具类
//获取所有文件
Collection<File> files = FileUtils.listFiles(new File("F:\\storm"),new String[]{"txt"},false);
for(File file:files){
try {
//获取文件中的所有内容
List<String> lines = FileUtils.readLines(file);
//获取文件中的每行内容
for(String line:lines){
//发射出去
this.collector.emit(new Values(line));
}
FileUtils.moveFile(file, new File(file.getAbsolutePath()+System.currentTimeMillis()));
} catch (IOException e) {
e.printStackTrace();
}
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}
public static class SplitBolt extends BaseRichBolt{
private OutputCollector collector;
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
/**
* 业务逻辑
* line:对line进行分割,按照空格
* */
public void execute(Tuple input) {
String value = input.getStringByField("line");
String[] words = value.split(",");
for(String word:words){
this.collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
/**
* 词频汇总Bolt
* */
public static class CountBolt extends BaseRichBolt{
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
Map<String,Integer> map = new HashMap<String,Integer>();
/**
* 业务逻辑
* 1.获取每个单词
* 2.对所有单词进行汇总
* 3.输出
* */
public void execute(Tuple input) {
String word = input.getStringByField("word");
Integer count = map.get(word);
if(count==null){
count=0;
}
count++;
map.put(word, count);
System.out.println("~~~~~~~~~~~~~~~~~~~~~");
Set<Entry<String, Integer>> entrySet = map.entrySet();
for(Map.Entry<String, Integer> entry:entrySet){
System.out.println(entry);
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) {
//本地模式,没有提交到服务器集群上,不需要搭建storm集群
LocalCluster cluster = new LocalCluster();
//TopologyBuilder根据spout和bolt来构建Topology
//storm中任何一个作业都是通过Topology方式进行提交的
//Topology中需要指定spout和bolt的执行顺序
TopologyBuilder tb = new TopologyBuilder();
tb.setSpout("DataSourceSpout", new DataSourceSpout());
//SumBolt以随机分组的方式从DataSourceSpout中接收数据
tb.setBolt("SplitBolt", new SplitBolt()).shuffleGrouping("DataSourceSpout");
tb.setBolt("CountBolt", new CountBolt()).shuffleGrouping("SplitBolt");
//第一个参数是topology的名称,第三个参数是Topology
cluster.submitTopology("LocalWordCountStormTopology", new Config(), tb.createTopology());
}
}
七、编程注意事项
1.topology定义spout和bolt的名字时不能以双下划线开头。
2.topology名字不能相同。














 1409
1409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









