







我们前边说过MySQL在一般情况下执行一个查询时最多只会用到单个二级索引,但存在有特殊情况,在这些特殊情况下也可能在一个查询中使用到多个二级索引,MySQL中这种使用到多个索引来完成一次查询的执行方法称之为:索引合并/index merge,具体的索引合并算法有下边三种。
1.Intersection合并
Intersection翻译过来的意思是交集。这里是说某个查询可以使用多个二级索引,将从多个二级索引中查询到的结果取交集,比方说下边这个查询:
SELECT * FROM order_exp WHERE order_no = 'a' AND expire_time = 'b';
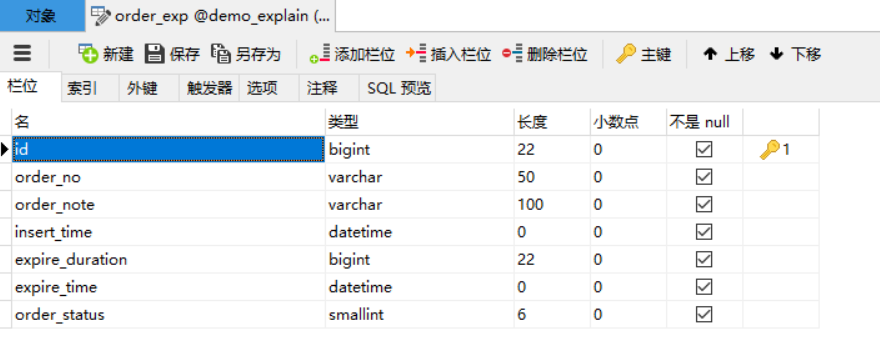
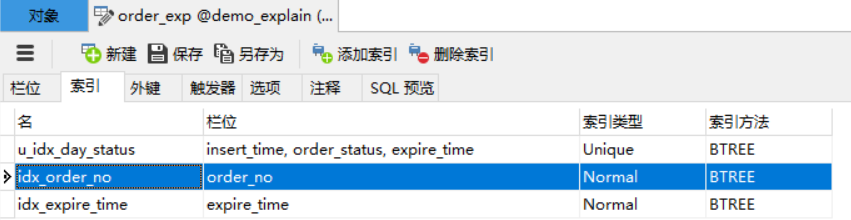
假设这个查询使用Intersection合并的方式执行的话,那这个过程就是这样的:
-
从idx_order_no二级索引对应的B+树中取出order_no='a'的相关记录。
-
从idx_expire_time二级索引对应的B+树中取出expire_time='b'的相关记录。
二级索引的记录都是由索引列 + 主键构成的,所以我们可以计算出这两个结果集中id值的交集。
按照上一步生成的id值列表进行回表操作,也就是从聚簇索引中把指定id值的完整用户记录取出来,返回给用户。
为啥不直接使用idx_order_no或者idx_expire_time只根据某个搜索条件去读取一个二级索引,然后回表后再过滤另外一个搜索条件呢?这里要分析一下两种查询执行方式之间需要的成本代价。
只读取一个二级索引的成本:
1.按照某个搜索条件读取一个二级索引
2.根据从该二级索引得到的主键值进行回表操作
3.然后再过滤其他的搜索条件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











