







任务B为表格识别部分,本文暂只看表格识别
摘要(不重要,想直接看表格识别部分可以跳过).
科学文献包含与不同领域的前沿创新有关的重要信息。自然语言处理的进步推动了科学文献信息自动提取的快速发展。然而,科学文献通常以非结构化PDF格式提供。虽然PDF非常适合在画布上保存基本的视觉元素,如字符、线条、形状等,以便呈现给人类,但机器对PDF格式的自动处理带来了许多挑战。现有超过2.5万亿PDF文档,这些问题在许多其他重要应用领域也很普遍。
从科学文献中自动提取信息的一个关键挑战是,文档中通常包含非自然语言的内容,如图形和表格。然而,这些内容通常说明了研究的关键结果、信息或总结。为了全面理解科学文献,自动化系统必须能够识别文档的布局,并将非自然语言内容解析为机器可读的格式。我们的ICDAR 2021科学文献解析竞赛(ICDAR2021 SLP)旨在推动文档理解方面的进步。ICDAR221-SLP利用PubLayNet和PubTabNet数据集,提供数十万个培训和评估示例。在任务A(文档布局识别)中,具有最高性能的提交结合了对象检测和针对不同类别的专业解决方案。在任务B“表格识别”中,top提交依赖于识别表格组件的方法和生成表格结构和内容的后处理方法。这两项任务的结果都显示了令人印象深刻的性能,并为高性能的实际应用开辟了可能性。
1、引言(不重要,可跳过,有需要再看)
便携式文档格式(PDF)的文档随处可见,多个行业的文档数量超过2.5万亿[12],包括保险文档、医疗文件和同行评议科学文章。PDF是在线和离线知识的主要来源之一。虽然PDF非常适合保存画布上的基本元素(字符、线条、形状、图像等),供不同的操作系统或设备供人类使用,但它不是机器可以理解的格式。
目前大多数文档理解方法都依赖于深度学习,这需要大量的训练示例。我们使用本次比赛中使用的PubMed Central1自动生成了大型数据集。PubMed Central是美国国立卫生研究院/国家医学图书馆提供的生物医学领域的大量全文文章集。
截至今天,PubMed Central拥有2476种期刊的近700万篇全文文章,这为研究大量不同文章风格的文档理解问题提供了可能。我们的数据集是使用PubMed Central的一个子集生成的,该子集根据可供商业使用的知识共享许可证发布。
竞赛分为两个任务,一个是通过要求参与者识别文档页面中的几类信息来理解文档布局(任务A),另一个是通过要求参与者生成表格图像的HTML版本来理解表格(任务B)。IBM Research AI排行榜系统用于收集和评估参与者提交的信息。该系统基于EvalAI2。
在任务A中,参与者可以访问除最终评估测试集的基本事实之外的所有数据,测试集在PubLayNet可用时发布。在任务B中,我们在参与者提交最终结果前三天发布了最终评估测试集。在任务a的评估阶段,我们收到了来自78个不同团队的大量参与者提交的281份意见书。这两项任务的结果显示,当前最先进的算法具有令人印象深刻的性能,比之前报告的结果有显著改善,这为高性能的实际应用开辟了可能性。
3、任务B——表格识别
表格格式的信息在各种文件中都很普遍。与自然语言相比,表格提供了一种以更紧凑和结构化的格式总结大量数据的方法。表格还提供了一种格式,帮助读者查找和比较信息。本次竞赛旨在推进非结构化表格自动识别的研究。
该任务的参与者需要开发一个模型,该模型可以将表格数据的图像转换为相应的HTML代码,这是在PubMed Central 2021举行的HTML表格表示竞赛之后进行的。任务参与者生成的HTML代码应该正确地表示表的结构和每个单元格的内容。单元格内容中应包含定义文本样式(包括粗体、斜体、删除、上标和下标)的HTML标记。HTML代码不需要重建表格的外观,例如边框线、背景色或字体、字体大小或字体颜色。
3.1、相关工作
还有其他表格识别挑战,主要在国际文件分析与识别会议(ICDAR)上组织。ICDAR 2013 表格竞赛是首个关于表格检测和识别的竞赛[5]。ICDAR 2013表格竞赛共包括156张表格,用于评估表格检测和表格识别方法;然而,没有提供培训数据。ICDAR 2019表格检测和识别竞赛为表格检测和识别提供培训、验证和测试样本(总计3600个)[4]。两种类型的文档,历史手写和编程模型,都是以图像格式提供的。ICDAR 2019竞赛包括三项任务:1)确定表格区域;2) 识别具有给定表区域的表结构;3) 在没有给定表区域的情况下识别表结构。ground truth只包括表格单元格的边界框,不包括单元格内容。
我们的Task B竞赛提出了一项更具挑战性的任务:模型需要仅依靠表格图像,识别表格结构和表格的单元格内容。换句话说,模型需要推断表的树结构以及每个叶节点(表头\体单元格)的属性(内容、行跨度、列跨度)。此外,我们不提供单元格位置、邻接关系或行/列分割的中间注释,这些都是训练大多数现有表格识别模型所需的。我们只提供树表示的最终结果以供监督。我们相信这将激励参与者开发新的图像到结构映射模型。
3.2、数据
该任务使用了PubTabNet数据集(v2.0.0)[16]。PubTabNet包含超过500k个训练样本和9k个验证样本,其中提供了ground truthHTML代码,以及非空表单元格的位置。参与者可以使用训练数据训练他们的模型,并使用验证数据进行模型选择和超参数调整。9k+最终评估集(仅图像,无注释)在决赛最终评估阶段结束前3天发布 。参与者在最后阶段提交了他们在这一集上的结果。
使用TEDS(基于树编辑距离的相似性)度量标准[16]对提交的内容进行评估。
T
E
D
S
TEDS
TEDS使用[11]中提出的树编辑距离测量两个表之间的相似性。插入和删除操作的成本为1。当
e
d
i
t
edit
edit将节点no替换为ns时,如果no或ns不是td,则代价为1。当no和ns都是td时,如果no和ns的列跨度或行跨度不同,则替换成本为1。否则,替代成本是no和ns含量之间的标准化
L
e
v
e
n
s
h
t
e
i
n
Levenshtein
Levenshtein相似性[9](在[0,1]中)。最后,两棵树之间的
T
E
D
TED
TED计算为
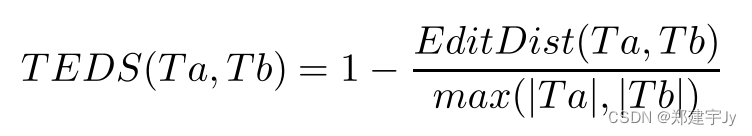
其中
E
d
i
t
D
i
s
t
EditDist
EditDist表示树编辑距离,
∣
T
∣
|T|
∣T∣ 是
T
T
T 中的节点数。一组测试样本上方法的表格识别性能定义为每个样本的识别结果和基本真理之间的
T
E
D
S
TEDS
TEDS分数的平均值。
比赛分为三个阶段。格式验证阶段贯穿整个竞赛,参与者可以使用我们提供的迷你开发集验证他们的结果文件是否符合我们的提交要求。开发阶段从比赛开始到比赛结束前3天。在这个阶段,参与者可以提交测试样本的结果,以验证他们的模型。最终评估阶段将在本次比赛的最后3天进行。参与者可以在此阶段提交最终评估集的推理结果。最终排名和获胜团队由最终评估阶段的表现决定。表3.2显示了不同任务B阶段使用的不同数据集的大小。
| Split | Size | Phase |
|---|---|---|
| Training | 500,777 | N/A |
| Development | 9,115 | N/A |
| Mini development | 20 | Format Verification Phase |
| Test | 9138 | Development |
| Final evaluation | 9064 | Final evaluation |
表3.2:任务B数据集统计
3.3、结果
对于任务B,我们有30个团队提交的30份意见书,用于最终评估阶段。在最终评估中,使用
T
E
D
S
TEDS
TEDS性能排名前十的系统如表4所示。由于最终评估数据集存在问题,在评估中未考虑的地方,使用粗体标记。
前四个系统具有相似的性能,而我们看到了更显著的不同。正如系统描述中所示,它们依赖于几个组件的组合,这些组件从表格图像中识别相关组件,然后组合它们。与之前报告的结果相比,使用图像到序列方法的
T
E
D
S
TEDS
TEDS指标的性能更好[17]。在[17]中,该数据集与本次比赛的测试集具有可比性,并源自PubMed Central。
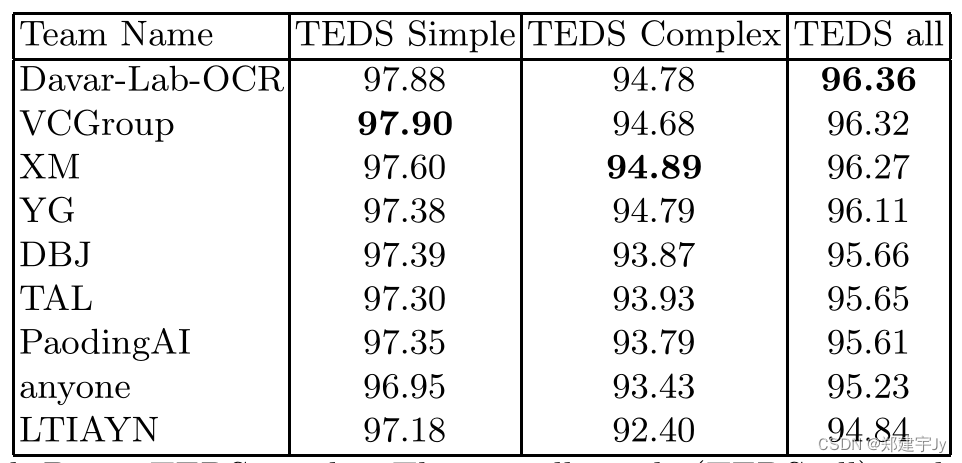
表4:总体结果(
T
E
D
S
TEDS
TEDS all)分解为简单和复杂的表格[16]
3.4、系统描述(只描述了一部分)
Team: Davar-Lab-OCR,海康威视研究所
Davar Lab OCR论文和源代码
表格识别框架包含两个主要过程:表格单元生成和结构推断
(1)基于MASK R-CNN检测模型建立表单元生成。具体来说,该模型经过训练,可以学习行 / 列对齐的单元级边界框,以及相应的文本内容区域掩码。我们引入金字塔掩码监督,并采用HRNet-W48级联MASK R-CNN的大型主干来获得可靠的
a
l
i
g
n
e
d
aligned
aligned
b
o
u
n
d
i
n
g
bounding
bounding
b
o
x
e
s
boxes
boxes。此外,我们还训练了一个单行文本检测模型和一个基于注意的文本识别模型来提供OCR信息。这只需选择只包含单行文本的实例即可实现。我们还采用了多尺度集合在单元格和单行文本检测模型上进一步提高性能。
(2)在结构推断阶段,单元的边界框可以根据对齐重叠进行水平/垂直连接。然后通过最大团搜索(Maximum Clique Search)过程生成行\列信息,在此过程中可以轻松找到空单元格。
为了处理一些特殊情况,我们训练另一个表检测模型来过滤不属于该表的文本。
Team: VCGroup
VCGroup Github repo:
在我们的方法[7,10,14]中,我们将表格内容识别任务分为四个子任务:表格结构识别、文本行检测、文本行识别和方框分配。我们的表格结构识别算法是基于MASTER定制的,MASTER是一种健壮的图像文本识别算法。PSENet用于检测表格图像中的每一行文本。对于文本行识别,我们的模型也基于MASTER。最后,在文本框分配阶段,我们将PSENet检测到的文本框与表结构预测重构的结构项相关联,并将识别出的文本行内容填充到相应的项中。我们提出的方法在开发阶段对9115个验证样本的
T
E
D
S
TEDS
TEDS评分为96.84%,在最终评估阶段对9064个样本的
T
E
D
S
TEDS
TEDS评分为96.32%。
Team: Tomorrow Advancing Life(TAL)
TAL系统由两个方案组成:
(1)通过表头检测、行检测、列检测、单元格检测和文本行检测5种检测模型重建表格结构。选择Mask R-CNN作为这5种检测模型的基线,针对不同的检测任务进行有针对性的优化。在识别部分,将单元检测和文本行检测的结果输入到CRNN模型中,得到每个单元对应的识别结果。
(2)表结构的恢复被视为img2seq问题。为了缩短解码长度,我们用不同的数字替换每个单元格内容。这些数字来自文本行检测结果。然后我们使用CNN对图像进行编码,并使用变压器模型对表的结构进行解码。然后,可以使用CRNN模型获得相应的文本行内容。
以上两种方案可以得到完整的表格结构和内容识别结果。我们有一套选择规则,结合了两种方案的优点,以输出一个最佳的最终结果。
Team: PaodingAI, Beijing Paoding Technology Co., Ltd
团队:保定AI,北京保定科技有限公司
保定AI的系统分为三个主要部分:文本块检测、文本块识别和表格结构识别。文本块检测器由MMDetection提供的检测器级联rcnn r50 2x模型进行训练。
文本块识别器由SAR TF模型训练。表结构识别器是我们自己对[13]中提出的模型的实现。除了上述模型之外,我们还使用规则和简单的分类模型来处理、<b和空白字符。我们的系统不是端到端模型,也没有使用集成方法。
Team: Kaen Context, Kakao Enterprise
公司位于韩国京畿道城南西
为了有效地解决表识别问题,我们使用了12层仅限解码器的线性transformer结构[8]。
数据准备:我们使用RGB图像(无需重新缩放)作为输入条件,合并的HTML代码用作目标文本序列。我们将一张表格图像重塑为一系列形状平坦的面片(N,8✖8✖3),其中8是每个图像面片的宽度和高度,N是面片的数量。然后,我们用线性投影层将图像序列映射到 512 维。目标文本序列通过嵌入层转换为 512 维嵌入,并附加在投影图像序列的末尾。最后,我们将不同的位置编码添加到文本和图像序列中,以使我们的模型能够区分它们。
训练:将拼接后的图像文本序列作为模型的输入,在教师强制算法下通过交叉熵损失对模型进行训练。
推论:我们的模型的输出通过beam搜索进行采样(beam=32)。
参考文献:
Antonacopoulos, A., Bridson, D., Papadopoulos, C., Pletschacher, S.: A realistic dataset for performance evaluation of document layout analysis. In: 2009 10th International Conference on Document Analysis and Recognition. pp. 296–300.IEEE (2009)
Clausner, C., Antonacopoulos, A., Pletschacher, S.: Icdar2017 competition on recognition of documents with complex layouts-rdcl2017.In: 2017 14th IAPR In- ternational Conference on Document Analysis and Recognition (ICDAR). vol. 1, pp. 1404–1410. IEEE (2017)
Clausner, C., Papadopoulos, C., Pletschacher, S., Antonacopoulos, A.: The enp image and ground truth dataset of historical newspapers.In: 2015 13th International Conference on Document Analysis andRecognition (ICDAR). pp. 931–935.IEEE (2015)
Gao, L., Huang, Y., Li, Y., Yan, Q., Fang, Y., Dejean, H., Kleber, F., Lang, E.M.:ICDAR 2019 competition on table detection and recognition. In: 2019 International Conference on Document Analysis and Recognition (ICDAR). pp. 1510–1515. IEEE (Sep 2019).https://doi.org/10.1109/ICDAR.2019.00166
G¨ obel, M., Hassan, T., Oro, E., Orsi, G.: ICDAR 2013 table competition. In: 201312th International Conference on Document Analysis and Recognition. pp. 1449–1453. IEEE (2013)
Grygoriev, A., Degtyarenko, I., Deriuga, I., Polotskyi, S., Melnyk, V., Zakharchuk,D., Radyvonenko, O.: HCRNN: A novel architecture for fast online handwrittenstroke classification. In: Proc. of Int. Conf.on Document Analysis and Recognition(2021)
He, Y., Qi, X., Ye, J., Gao, P., Chen, Y., Li, B., Tang, X., Xiao, R.: Pingan- vcgroup’s solution for icdar 2021 competition on scientific table image recognitionto latex. arXiv (2021)
Katharopoulos, A., Vyas, A., Pappas, N., Fleuret, F.: Transformers are rnns: Fastautoregressive transformers with linear attention. In:International Conference onMachine Learning. pp. 5156–5165. PMLR(2020)
Levenshtein, V.I.: Binary codes capable of correcting deletions, insertions, andreversals. In: Soviet physics doklady. vol. 10, pp.707–710. Soviet Union (1966)
Lu, N., Yu, W., Qi, X., Chen, Y., Gong, P., Xiao, R., Bai, X.: Master: Multi-aspectnon-local network for scene text recognition.Pattern Recognition (2021)
Pawlik, M., Augsten, N.: Tree edit distance: Robust and memory-efficient. Infor-mation Systems 56, 157–173 (2016)
Staar, P.W., Dolfi, M., Auer, C., Bekas, C.: Corpus conversion service: A machinelearning platform to ingest documents at scale. In:Proceedings of the 24th ACM SIGKDD International Conference onKnowledge Discovery & Data Mining. pp.774–782 (2018)ICDAR 2021Competition on Scientific Literature Parsing 13
Tensmeyer, C., Morariu, V.I., Price, B., Cohen, S., Martinez, T.: Deep splittingand merging for table structure decomposition. In: 2019 International Conference on Document Analysis and Recognition (ICDAR).pp. 114–121. IEEE (2019)
Ye, J., Qi, X., He, Y., Chen, Y., Gu, D., Gao, P., Xiao, R.: Pingan-vcgroup’s solution for icdar 2021 competition on scientific literature parsing task b: Table recognition to html. arXiv (2021)
Zheng, X., Burdick, D., Popa, L., Zhong, X., Wang, N.X.R.: Global table extrac-tor (gte): A framework for joint table identification and cell structure recognition using visual context. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp.697–706 (2021)
Zhong, X., ShafieiBavani, E., Yepes, A.J.: Image-based table recognition: data,model, and evaluation. arXiv preprint arXiv:1911.10683 (2019)
Zhong, X., Tang, J., Yepes, A.J.: Publaynet: largest dataset ever for document lay-out analysis. In: 2019 International Conference on Document Analysis and Recog-nition (ICDAR). pp. 1015–1022. IEEE (2019)


















 508
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











