







本文记录学习下面三个任务过程中思考过的问题及大家讨论过程中学习到的知识点,欢迎指正。
- 线性回归
- Softmax与分类模型
- 多层感知机
基础知识部分直接参考Dive-into-DL-PyTorch
pytorch矩阵4种乘法的区别:*, torch.mul, torch.mm, torch.matmul
简单理解:前两者是点成,后两者是矩阵乘法
具体可参考: torch.Tensor的4种乘法
Tensor改变shape的方式
常见有view,但这个和原变量共享内存;
reshape;
但如何想要真正的新副本,x.clone.view();
具体 参考2.2.2
torch.randn中size参数的定义
torch.randn(size=[3,4]) # torch.randn(3,4),torch.randn((3,4)),
torch.randn(size=[4])# torch.randn(4)
查了下参数说明终于明白了。
size (int…): a sequence of integers defining the shape of the output tensor.
Can be a variable number of arguments or a collection like a list or tuple.
所以还可以用下面这种方式
l=[3,4]
torch.randn(size= l),torch.randn(*l)
训练集、验证集和测试集的比例应该怎么去进行分配呢?
传统上是6:2:2的比例,但是不同的情况下你的选择应当不同。这方面的研究也有很多,如果你想要知道我们在设置比例的时候应当参考那些东西,可以去看Isabelle Guyon的这篇论文:A scaling law for the validation-set training-set size ratio 。他的个人主页(http://www.clopinet.com/isabelle/)里也展示了他对于这个问题的研究。
模型容器(Containers)定义方式
nn.Sequetial:按顺序包装多个网络层
nn.ModuleList:像python的ist一样包装多个网络层
nn.ModuleDict:像python的dict一样包装多个网络层
利弊:
·nn.Sequential:顺序性,各网络层之间严格按顺序执行,常用于block构建
·nn.ModuleList:迭代性,常用于大量重复网构建,通过for循环实现重复构建
·nn.ModuleDict:索引性,常用于可选择的网络层
训练集、验证集和测试集的数据是否可以有所重合?
有些时候我们的数据太少了,又不想使用数据增强,那么训练集、验证集和测试集的数据是否可以有所重合呢?这方面的研究就更多了,各种交叉方法,感兴趣的话可以去看Filzmoser这一篇文章Repeated double cross validation
原链接
pytorch中除索引之外选择方式
index_select 可用索引替代
masked_select 选取特定值,如a[a>0]
gather 在计算交叉熵时用到
scatter_ 构造onehot时有用,可用索引方法代替,等价于 循环+result[i, x[i, 0]] = 1
如何修改parameter的值,但又不影响梯度的计算?
参数更新便需要这个机制
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size # ues .data to operate param without gradient track···
为了保证参数值正常更新的同时又不影响梯度的计算,即使用param.data可以将更新的参数独立于计算图,
阻断梯度的传播,当训练结束就可以得到最终的模型参数值。
原链接
还有种方法就是利用with torch.no_grad(),此部分的计算图会中断梯度追踪,参考书2.3.2
Torch转numpy方法
有.numpy()与 .item()
都是从Tensor转numpy,但前者可以是高维,后者是标量Tensor转成数字
但要注意是 Tensor必须先detach,否则会引发如下错误。
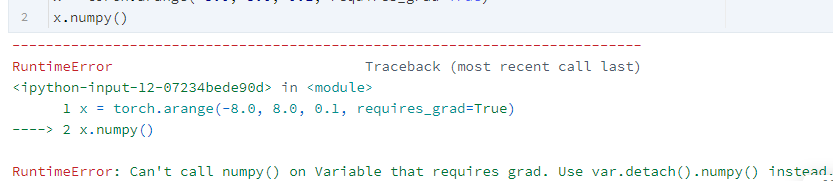
因为我们需要从计算图中分离出来Tensor,这在后续rnn相邻采样也用到此技巧,作用是在相邻采样中,使模型参数的梯度计算只依赖一次迭代读取的小批量序列(防止梯度计算开销太大)
if is_random_iter: # 如使用随机采样,在每个小批量更新前初始化隐藏状态
state = init_rnn_state(batch_size, num_hiddens, device)
else: # 否则需要使用detach函数从计算图分离隐藏状态
for s in state:
s.detach_()
requires_grad必须在定义Tensor时确定?
定义Tensor和requires_grad=True可以分开
W1 = torch.tensor(np.random.normal(0, 0.01, (num_inputs, num_hiddens)), dtype=torch.float)
W1 .requires_grad_(requires_grad=True)
# W1 = torch.tensor(np.random.normal(0, 0.01, (num_inputs, num_hiddens)), dtype=torch.float,requires_grad=True)
有论文里也将KL散度作为多分类训练的目标函数
由于CrossEntropyLoss与KL散度等价
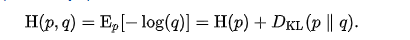
具体可参考.Kullback–Leibler divergence定义
同时可以理解下为什么CrossEntropy作为两个分布的距离。
如何计算网络参数量
from torchsummary import summary
num_inputs, num_outputs, num_hiddens = 256*256, 10, 1000
net = nn.Sequential(
d2l.FlattenLayer(),
nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.Linear(num_hiddens, num_outputs),
)
summary(net,(1, 256,256))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
FlattenLayer-1 [-1, 65536] 0
Linear-2 [-1, 1000] 65,537,000
ReLU-3 [-1, 1000] 0
Linear-4 [-1, 10] 10,010
================================================================
Total params: 65,547,010
Trainable params: 65,547,010
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.25
Forward/backward pass size (MB): 0.52
Params size (MB): 250.04
Estimated Total Size (MB): 250.81
----------------------------------------------------------------
为何用softmax归一化
补充说明一下,以上说明方法来自书籍pattern recognition and machine learning中的一种线性分类概率生成式模型,原文中softmax函数形式为
p
(
C
k
∣
x
)
=
p
(
x
∣
C
k
)
p
(
C
k
)
∑
j
p
(
x
∣
C
j
)
p
(
C
j
)
=
exp
(
a
k
)
∑
j
exp
(
a
j
)
p(C_{k}|x) = \frac{p(x|C_{k})p(C_{k})}{\sum_{j}p(x|C_{j})p(C_{j})}=\frac{\exp(a_{k})}{\sum_{j}\exp(a_{j})}
p(Ck∣x)=∑jp(x∣Cj)p(Cj)p(x∣Ck)p(Ck)=∑jexp(aj)exp(ak)
其中
a
k
=
ln
p
(
x
∣
C
k
)
p
(
C
k
)
a_{k}=\ln p(x|C_{k})p(C_{k})
ak=lnp(x∣Ck)p(Ck)
k为当前计算类别,j代表所有类别的索引
本说明方式中softmax函数处理的是经过处理之后已经生成的概率
网上另有证明多项式分布属于指数分布族后推导softmax函数的方法,处理的数据也是概率数据
softmax函数是来自于sigmoid函数在多分类情况下的推广,他们的相同之处:
1.都具有良好的数据压缩能力是实数域R→[ 0 , 1 ]的映射函数,可以将杂乱无序没有实际含义的数字直接转化为每个分类的可能性概率。
2.都具有非常漂亮的导数形式,便于反向传播计算。
3.它们都是 soft version of max ,都可以将数据的差异明显化。
相同的,他们具有着不同的特点,sigmoid函数可以看成softmax函数的特例,softmax函数也可以看作sigmoid函数的推广。
1.sigmoid函数前提假设是样本服从伯努利 (Bernoulli) 分布的假设,而softmax则是基于多项式分布。首先证明多项分布属于指数分布族,这样就可以使用广义线性模型来拟合这个多项分布,由广义线性模型推导出的目标函数即为Softmax回归的分类模型。
2.sigmoid函数用于分辨每一种情况的可能性,所以用sigmoid函数实现多分类问题的时候,概率并不是归一的,反映的是每个情况的发生概率,因此非互斥的问题使用sigmoid函数可以获得比较漂亮的结果;softmax函数最初的设计思路适用于首先数字识别这样的互斥的多分类问题,因此进行了归一化操作,使得最后预测的结果是唯一的。
原链接
ReLu激活函数为什么没有梯度消失问题,当输入<=0时,梯度不也变成0了
ReLU在x<0部分会有梯度消失问题,但只有一半;所以后续有Leaky ReLU来缓解这个问题
但是相比于sigmoid梯度最大值0.25并且大部分区域都非常小,ReLU只有一半区域还是缓解很多
画函数梯度图时为何先用y.sum().backward()
每个x相当于 x i x_i xi, ∑ f ( x i ) \sum f(x_i) ∑f(xi)对 x i x_i xi求导,相当于 f ( x i ) f(x_i) f(xi)对 x i x_i xi求导。
Torch是否允许一维张量对一维张量求导;y.backward()时为什么不需要传入gradient参数值
不允许,只允许标量对张量,所以目前都是损失函数都是标量
但y.backward()时,y是张量,这个时候只需要传入和y同形的张量v,也一样能求导,这是因为y.backward()时会先计算l=torch.sum(y*v),则l是张量,转为标量对张量的问题。















 422
422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









