







前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、汉字点阵字库
1.汉字编码
汉字编码(Chinese character encoding )是为汉字设计的一种便于输入计算机的代码。
(1)区位码
1980年,为了使每个汉字有一个全国统一的代码,我国颁布了汉字编码的国家标准:GB2312-80《信息交换用汉字编码字符集》基本集,这个字符集是我国中文信息处理技术的发展基础,也是国内所有汉字系统的统一标准。国标码是一个四位十六进制数,区位码是一个四位的十进制数,每个国标码或区位码都对应着一个唯一的汉字或符号,但因为十六进制数我们很少用到,所以大家常用的是区位码,它的前两位叫做区码,后两位叫做位码。
编码规则:
01-09区为特殊符号
10-15区为用户自定义符号区(未编码)
16-55区为一级汉字,按拼音排序
56-87区为二级汉字,按部首/笔画排序
88-94区为用户自定义汉字区(未编码)
(2)机内码
汉字机内码,又称“汉字ASCII码”,简称“内码”,指计算机内部存储,处理加工和传输汉字时所用的由0和1符号组成的代码。输入码被接受后就由汉字操作系统的“输入码转换模块”转换为机内码,与所采用的键盘输入法无关。机内码是汉字最基本的编码,不管是什么汉字系统和汉字输入方法,输入的汉字外码到机器内部都要转换成机内码,才能被存储和进行各种处理。
因为汉字处理系统要保证中西文的兼容,当系统中同时存在ASCII码和汉字国标码时,将会产生二义性。例如:有两个字节的内容为30H和21H,它既可表示汉字“啊”的国标码,又可表示西文“0”和“!”的ASCII码。为此,汉字机内码应对国标码加以适当处理和变换。
国标码的机内码为二字节长的代码,它是在相应国标码的每个字节最高位上加“1”,即
汉字机内码=汉字国标码+8080H
例如,上述“啊”字的国标码是3021H,其汉字机内码则是B0A1H。
汉字机内码的基础是汉字国标码。
机内码:为了避免ASCII码和国标码同时使用时产生二义性问题,大部分汉字系统都采用将国标码每个字节高位置1作为汉字机内码。这样既解决了汉字机内码与西文机内码之间的二义性,又使汉字机内码与国标码具有极简单的对应关系。
汉字机内码、国标码和区位码三者之间的关系为:区位码(十进制)的两个字节分别转换为十六进制后加2020H得到对应的国标码;机内码是汉字交换码(国标码)两个字节的最高位分别加1,即汉字交换码(国标码)的两个字节分别加80H得到对应的机内码;区位码(十进制)的两个字节分别转换为十六进制后加A0H得到对应的机内码。
2.点阵字库结构
(1)点阵字库的显示原理
所有的汉字或者英文都是下面的原理,由左至右,每8个点占用一个字节,最后不足8个字节的占用一个字节,而且从最高位向最低位排列。
生成的字库说明:(以12×12例子)
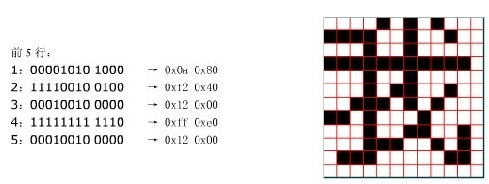
一个汉字占用字节数:12÷8=1····4也就是占用了2×12=24个字节。
编码排序A0A0→A0FE A1A0→A2FE依次排列。
以12×12字库的“我”为例:“我”的编码为CED2,所以在汉字排在CEH-AOH=2EH区的D2H-A0H=32H个。所以在12×12字库的起始位置就是[{FE-A0}*2EH+32H]*24=104976开始的24个字节就是我的点阵模,其他的类推即可;英文点阵也是如此推理。
参考文章
参考文章:https://blog.csdn.net/a511244213/article/details/45846443
(2)点阵字库与字符字模
在dos终端模式下是不可以显示中文汉字的,只能显示英文。
汉字与英文的区别是:
1. 汉字字库中,任何字符均用2个字节编码,即区码和位码,在英文字库中,所有字符均用单字节编码。
2. 16点阵汉字字库(1616)用32个字节存储一个字符的字模,16点阵英文字库(816)用16个字节存储单个字符的字模。
在DOS终端模式下用的是16点阵英文字库,如果要让DOS终端中显示中文,可以改写终端模式下的16点阵英文字库,使其显示的不是原有的英文字符,而是汉字字符,当然也可以加入自造点阵图形图像。原理为:
我们输入AB,正常显示的是AB,但如果改变AB的字模,用汉字的字模代替,这样输入AB字符,并不显示AB,而是显示一个汉字。将一个汉字从中间劈为两半,左面部分顶替A的字模,右面部分顶替B的字模。
dos所用字库,文件头结构很简单,如默认的8*16英文字库,文件头长度为4,跳过这四个字节就是字模数据;也有没有文件头的,从第一个字节开始就是字模数据。
(3)汉字点阵的获取方式
1、利用区位码获取汉字
汉字点阵字库是根据区位码的顺序进行存储的,因此,我们可以根据区位来获取一个字库的点阵,它的计算公式如下:
点阵起始位置 = ((区码- 1)*94 + (位码 – 1)) * 汉字点阵字节数
获取点阵起始位置后,我们就可以从这个位置开始,读取出一个汉字的点阵。
2、利用汉字机内码获取汉字
前面我们己经讲过,汉字的区位码和机内码的关系如下:
机内码高位字节 = 区码 + 20H + 80H(或区码 + A0H)
机内码低位字节 = 位码 + 20H + 80H(或位码 + AOH)
反过来说,我们也可以根据机内码来获得区位码:
区码 = 机内码高位字节 - A0H
位码 = 机内码低位字节 - AOH
将这个公式与获取汉字点阵的公式进行合并计就可以得到汉字的点阵位置。
二、在Ubuntu环境下输出文字(利用opencv)
1.创建一个c++文件,并输入代码
首先创建一个c++文件,打开ubuntu环境下的终端软件,输入以下代码打开编辑器:
gedit
之后在新建的文件中输入以下代码:
#include<iostream>
#include<opencv/cv.h>
#include"opencv2/opencv.hpp"
#include<opencv/cxcore.h>
#include<opencv/highgui.h>
#include<math.h>
using namespace cv;
void PaintSChinese(Mat& image, int x_offset, int y_offset, unsigned long offset);
void PaintSAscii(Mat& image,int x_offset, int y_offset, unsigned long offset);
void putTextToImage(int x_offset,int y_offset,String imagePath ,char* txtPath);
int main(){
String image_path="图片3.png";
char* logo_path=(char*)"logo.txt";
putTextToImage(20,300 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 639
639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









