







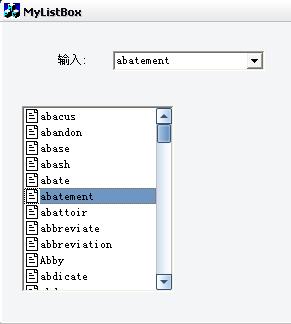
有看过这篇文章(上)的朋友应该都清楚这个控件的界面是怎样完成的吧,为什么要分开写两篇文章呢,因为写(上)的时候,我还没解决索引文件的问题.这几天一直在想索引文件的问题,刚开始的时候是去星际译王下载免费的词典,然后读单词原型并生成XML文件,原以为是很简单的事情,后来才发现没有一本词典是按从a到z设计的,根本就不可能用来做索引(因为我的控件是读一个单词,添加一个单词的). 接着,我就找金山词霸的文件,可是,它封装得很好,根本不给我机会. 呵呵,最后,让我找到了同样是金山的产品:词霸豆豆!它里面就有一个有1万6千多个单词原型的索引文件.金山是用特殊算法把它读出来的,有兴趣的朋友可以研究一下.但是我觉得太麻烦了,就将它改成了一个标准的XML文件,怎样改呢?
词霸豆豆的索引文件的格式是这样的:
IndexNum:281
a:0:323
ab:323:745
ac:1068:979
ad:2047:868
ae:2915:109
af:3024:322
ag:3346:330
ah:3676:47
ai:3723:132
ak:3855:5
al:3860:953
am:4813:544
an:5357:1227
ao:6584:6
ap:6590:944
aq:7534:35
………….
………….
a&a case in point&a couple of&a far cry&a few&a good deal&a good deal of&a good few&a good many&a great deal&a great many&a group of&a handful of&a hard nut to crack&a kind of&a large number of&a little&a little of&a lot&a lot of&a number of&a pair of&a piece of&a………………….
用EditPlus打开,将所有&字符替换成</item><item>(节点名你自己决定),然后稍微修改,然后把a:0:323, ab:323:745…这些删掉,这样就把词霸豆豆的索引文件转换成了标准格式的XML文件,接下来就是读XML了.下面是代码:
//当输入框文本发生变化时触发
void CMyListBoxDlg::OnEditchangeInputword()
{
//static int lastlistlen=0;
MSXML2::IXMLDOMElementPtr e;
{
//static int lastlistlen=0;
MSXML2::IXMLDOMElementPtr e;
GetDlgItemText(IDC_INPUTWORD,Inputword);
int Inputlen=Inputword.GetLength();
if(Inputlen==0)
{
m_list.ResetContent();
}
else if(Inputlen==1)
{
e=pDoc->documentElement;
CString str;
CString xml;
CString ch1;
ch1=Inputword.Mid(0,1);
ch1.MakeLower();
if(ch1>="a"&&ch1<="z")
{
int len2=m_list.GetCount();
for(int a=0;a<len2;a++)
{
m_list.DeleteString(0);
}
int Inputlen=Inputword.GetLength();
if(Inputlen==0)
{
m_list.ResetContent();
}
else if(Inputlen==1)
{
e=pDoc->documentElement;
CString str;
CString xml;
CString ch1;
ch1=Inputword.Mid(0,1);
ch1.MakeLower();
if(ch1>="a"&&ch1<="z")
{
int len2=m_list.GetCount();
for(int a=0;a<len2;a++)
{
m_list.DeleteString(0);
}
str=Inputword;
str.MakeLower();
xml="//"+str+"//a1";
nodelist = e->selectNodes((_bstr_t)xml);
int len;
len=nodelist->length;//获取item节点的个数
MSXML2::IXMLDOMElementPtr childNode;
VARIANT varVal;
CString strValue;
for(int i=0;i<len;i++)
{
childNode=nodelist->Getitem(i);
str.MakeLower();
xml="//"+str+"//a1";
nodelist = e->selectNodes((_bstr_t)xml);
int len;
len=nodelist->length;//获取item节点的个数
MSXML2::IXMLDOMElementPtr childNode;
VARIANT varVal;
CString strValue;
for(int i=0;i<len;i++)
{
childNode=nodelist->Getitem(i);
childNode->get_nodeTypedValue(&varVal);
strValue = (char*)(_bstr_t)varVal;
strValue = (char*)(_bstr_t)varVal;
m_list.AddString(strValue,0);
}
}
}
}
}
else if(Inputlen==2)
{
else if(Inputlen==2)
{
e=pDoc->documentElement;
CString str;
CString xml;
CString ch1;
CString ch2;
ch1=Inputword.Mid(0,1);
ch1.MakeLower();
if(ch1>="a"&&ch1<="z")
{
ch2=Inputword.Mid(1,1);
ch2.MakeLower();
if(ch2>="a"&&ch2<="z"||ch2==" "||ch2=="-")
{
int len2=m_list.GetCount();
for(int a=0;a<len2;a++)
{
m_list.DeleteString(0);
}
str=Inputword.Mid(0,2);
str.MakeLower();
xml="//"+str+"//a1";
nodelist = e->selectNodes((_bstr_t)xml);
ch1.MakeLower();
if(ch1>="a"&&ch1<="z")
{
ch2=Inputword.Mid(1,1);
ch2.MakeLower();
if(ch2>="a"&&ch2<="z"||ch2==" "||ch2=="-")
{
int len2=m_list.GetCount();
for(int a=0;a<len2;a++)
{
m_list.DeleteString(0);
}
str=Inputword.Mid(0,2);
str.MakeLower();
xml="//"+str+"//a1";
nodelist = e->selectNodes((_bstr_t)xml);
str=Inputword;
str.MakeLower();
str.MakeLower();
int len;
len=nodelist->length;//获取item节点的个数
VARIANT varVal;
CString strlower;
CString strValue;
MSXML2::IXMLDOMElementPtr childNode;
for(int i=0;i<len;i++)
{
childNode=nodelist->Getitem(i);
childNode->get_nodeTypedValue(&varVal);
strlower = (char*)(_bstr_t)varVal;
strlower.MakeLower();
strValue = (char*)(_bstr_t)varVal;
if(str<=strlower)
{
m_list.AddString(strValue,0);
}
}
}
}
len=nodelist->length;//获取item节点的个数
VARIANT varVal;
CString strlower;
CString strValue;
MSXML2::IXMLDOMElementPtr childNode;
for(int i=0;i<len;i++)
{
childNode=nodelist->Getitem(i);
childNode->get_nodeTypedValue(&varVal);
strlower = (char*)(_bstr_t)varVal;
strlower.MakeLower();
strValue = (char*)(_bstr_t)varVal;
if(str<=strlower)
{
m_list.AddString(strValue,0);
}
}
}
}
}
else if(Inputlen>=3)
{
CString str;
CString xml;
CString ch1;
CString ch2;
else if(Inputlen>=3)
{
CString str;
CString xml;
CString ch1;
CString ch2;
ch1=Inputword.Mid(0,1);
ch1.MakeLower();
if(ch1>="a"&&ch1<="z")
{
ch2=Inputword.Mid(1,1);
ch2.MakeLower();
if(ch2>="a"&&ch2<="z"||ch2==" "||ch2=="-")
{
int len2=m_list.GetCount();
for(int a=0;a<len2;a++)
{
m_list.DeleteString(0);
}
ch1.MakeLower();
if(ch1>="a"&&ch1<="z")
{
ch2=Inputword.Mid(1,1);
ch2.MakeLower();
if(ch2>="a"&&ch2<="z"||ch2==" "||ch2=="-")
{
int len2=m_list.GetCount();
for(int a=0;a<len2;a++)
{
m_list.DeleteString(0);
}
str=Inputword;
str.MakeLower();
str.MakeLower();
int len;
len=nodelist->length;//获取item节点的个数
MSXML2::IXMLDOMElementPtr childNode;
VARIANT varVal;
CString strlower;
CString strValue;
for(int i=0;i<len;i++)
{
childNode=nodelist->Getitem(i);
childNode->get_nodeTypedValue(&varVal);
strlower = (char*)(_bstr_t)varVal;
strlower.MakeLower();
strValue = (char*)(_bstr_t)varVal;
if(str<=strlower)
{
m_list.AddString(strValue,0);
}
}
}
}
}
}
len=nodelist->length;//获取item节点的个数
MSXML2::IXMLDOMElementPtr childNode;
VARIANT varVal;
CString strlower;
CString strValue;
for(int i=0;i<len;i++)
{
childNode=nodelist->Getitem(i);
childNode->get_nodeTypedValue(&varVal);
strlower = (char*)(_bstr_t)varVal;
strlower.MakeLower();
strValue = (char*)(_bstr_t)varVal;
if(str<=strlower)
{
m_list.AddString(strValue,0);
}
}
}
}
}
}
/
我在索引文件加了<ab>ab开头的单词</ab>,<ac> ac开头的单词</ac>…
因为如果不分的话,读入xml文件的时间太长,分了后,显示单词索引的速度比词霸豆要快
我这里是将输入单词的前两位取出来,在XML读相应的单词.这样一个类似于词霸豆豆的索引控件了.
今天在网上看到一张贴,说做词霸的技术其实很低,仿做金山词霸根本在浪费时间,我不知道是什么样的牛人说出这样的话,就算真的是这样,我现在还是一名学生,通过做这东西,还是学到了很多VC的知识. 以后会有更多相关资料会写上来,希望大家多多支持!!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









