



面部变形检测:一种基于图像退化分析的方法
摘要
2014年,一种针对面部生物识别特定应用场景的新型身份盗窃方案被提出。在此方案中,所谓的人脸融合将两个或多个不同个体的人脸图像融合为一张图像,该图像在视觉上与多个真实人物相似。基于这种非真实的图像,可向相关机构申请签发基于图像的身份证明文件。因此,多个个体可以使用该文件,在仅含有人为弱化的模板的单个证件下通过基于图像的人员验证场景。目前尚无可靠的现有安全机制能够检测此类攻击。
本文提出了一种基于连续图像退化的新型人脸融合伪造检测方法。该方法的相关性在于,退化方法会创建多个人工自参考,并测量输入与这些参考之间的“距离”。较小的距离(明显小于原始图像所预期的距离)可被视为一种异常,表明媒体内容可能被篡改(例如由变形引起)。我们的退化过程基于不同压缩值的JPEG压缩。我们检测方法的评估结果在实验室条件下分类准确率达到90.1%,在现实世界条件下达到84.3%。
关键词
人脸融合攻击的数字图像取证 · Detection
1 引言
人脸是一种在多种认证场景中广泛使用且被普遍接受的生物特征模态。在这些场景中,个人的身份验证通常通过身份证件中的人脸图像来完成。由于基于人脸图像的认证场景被广泛使用,它们成为各种身份盗窃方案的重点攻击目标。
费雷拉等人[1]在他们的论文《魔术护照》中提出了一种针对面部生物识别的新型身份盗窃方案,该方案描述了一种方法,允许多个人仅凭一个以“魔术护照”形式存在的人为弱化模板,通过身份验证场景。为了实施这种攻击,他们创建了一个所谓的 人脸融合 ,即将不同人的两个人脸图像或多个人脸图像融合在一起,使其与多个真实人物相似(例如见图1)。如果将这种变形的图像用于制作身份证件,则多个面部被融合在证件所集成的人脸图像中的人可成功使用该证件。
费雷拉等人在[1]中发现,该文件成功通过了所有光学和电子真实性与完整性检查。这揭示了官方身份验证检查中的一个漏洞,因为目前尚无可靠的现有安全机制来检测此类攻击。
本文提出了一种基于连续图像退化分析的人脸变形伪造检测方法,这可视作本文的主要科学贡献。在图像退化过程中,我们对解压后的输入文件进行不同压缩值的JPEG压缩。为了分析该退化过程,我们采用从现有OpenCV( http://opencv.org)边缘检测方法中提取的特征集。随后,我们将退化图像中提取的特征值与参考图像(输入)进行比较,以描述退化情况。对于真实人脸图像,由于退化的影响,我们应观察到面部区域边缘信息显著丢失。我们假设,在人脸融合情况下会出现异常,因为在融合流程中的融合操作会导致输入图像的面部细节丢失,使得进一步的退化过程对人脸融合图像的影响比对真实图像的影响更小。
我们的工作结构如下:第2节描述了人脸融合攻击取证方面的相关工作。在第3节中,我们介绍了基于退化检测方法的概念,包括用于基于模式识别检测的特征空间。下一节概述了我们的实验数据集以及介绍了我们变形检测实验的测试目标。第5节展示了实验结果,第6节对本文进行了总结,并展望了未来的工作。

2 相关工作
2014年,费雷拉等人在[1]中提出了一种新颖的方法,通过所谓的人脸融合攻击来攻击基于人脸图像的人员验证系统。在他们的研究中,展示了一本“魔术护照”,其照片身份证件上包含一张人脸融合图像,该证件由官方机构签发,并且与多个真实人物外貌相似。
该攻击所利用的脆弱性在于,在许多国家,允许个人自行提供照片用于证件制作。因此,这些多人可以成功地在边境检查中使用该护照,因为该证件绝对真实,并能通过所有光学和电子的真实性与完整性检查。费雷拉等人并未提出可检测此类攻击的安全机制,因此为这种易于实现的攻击寻找一种检测机制显得尤为重要。
在[4]中确认了来自[1]的攻击的相关性。在这项工作中,费雷拉等人分析了三个自动人脸识别(AFR)系统对人脸融合图像的拒识能力。结果令人担忧,所评估的AFR系统无法区分变形的和真实的人脸。
变形攻击来自[1]使用GIMP/GAP(www.gimp.org)手动生成变形人脸,这使得变形过程耗时较长,并且只能生成少量的变形图像。因此,他们在[2]中创建了一种自动化流程,用于生成视觉上无瑕疵的人脸变形。这使得能够生成大量实验数据,这对于法医检测器的训练至关重要。这些变形的质量通过AFR(Luxand FaceSDK 6.1[19])系统进行了验证。该AFR系统在1%的误接受率决策阈值下,“对任意真实图像的11.78%的变形图像予以接受”。此外,我们还进行了一项主观实验,表明人类区分这些自动生成的变形图像与真实人脸的能力几乎接近随机猜测。这些结果证实了变形问题对证件安全构成了严重威胁。本研究中使用该自动化流程来生成训练和测试数据集的变形图像。
我们还提出了一种检测方法,利用从JPEG图像的量化DCT系数中提取的本福特特征来自动检测变形图像。评估结果显示,由于图像预处理步骤的影响,变形图像的系数分布表现出异常。
在[3]中,作者针对不同的后处理技术和反取证方法,对来自[2]的检测方法的鲁棒性进行了评估。为此,他们基于乌得勒支人脸数据库[18]生成了86614个样本,以分析所应用的图像处理对AFR系统以及来自[2]的取证检测器的影响。
评估结果表明,对于某些处理技术,取证检测器的性能表现非常敏感,而对生物特征AFR系统而言,这些处理几乎无影响。
这些作者在他们的研究中,针对自动性别估计方案,专注于在人脸图像中掩盖性别信息,同时保留其被人脸识别匹配器使用的能力。为此,他们使用一种变形方案来创建两个面部输入的混合图像。该变形过程“可用于逐步修改输入图像,使其性别信息逐步被抑制”。
舍廷格等人在[5]中指出,CFA和双重JPEG压缩伪影可作为变形检测的可靠痕迹。
此外,拉加文德拉等人在[6]中提出了一种变形检测方法。该方法基于二值化统计图像特征,并结合线性支持向量机进行使用。
在[8]中,作者评估了两种不同的人脸识别系统针对扫描的变形人脸图像的脆弱性。此外,还介绍了一项关于当前提出的各种人脸变形检测器的比较研究。
戈麦斯‐巴雷罗等人在他们的论文[9]中提出了一种评估生物识别系统对变形攻击脆弱性的新框架。该分析表明,生物识别系统的脆弱性取决于验证阈值以及匹配和非匹配分数分布的形态,因而易受不同类型的攻击。
尽管该领域已有一些研究,但据我们所知,目前尚不存在一种绝对可靠的脸部图像变造检测方法,而利用退化过程来检测人脸变形伪造是一种新颖且具有前景的思路。
3 基于图像退化的变形检测方法概念
在本节中,我们介绍一种基于连续图像退化的检测方法。该方法本质上并非直接的变形检测方法,而是一种异常检测方法,用于检测由人脸变形过程引起的异常。该方法的基本思想是:我们所提出的特征对真实图像的退化反应较为敏感,而对变形图像的退化反应则不那么敏感。我们在面部区域使用了三种不同的角点特征检测器。由于退化的影响,真实图像中检测到的角点特征数量应显著减少。我们假设,在融合流程中的融合操作会导致变形图像在此处出现异常,因此退化过程对变形图像的影响不如对真实图像那样显著。该退化过程包含三个基本步骤(步骤I:预处理,步骤II:特征提取,步骤III:特征向量归一化),并在图2中进行了可视化。
在开始预处理之前,我们先将所有使用的图像解压缩并以PNG图像文件格式存储,以便为每个输入文件提供统一的基础。我们推荐使用这种格式,因为它是无损的且广为人知。作为预处理(步骤I),在特征提取(步骤II)之前,通过使用dlib编程库版本从Img中提取面部关键点
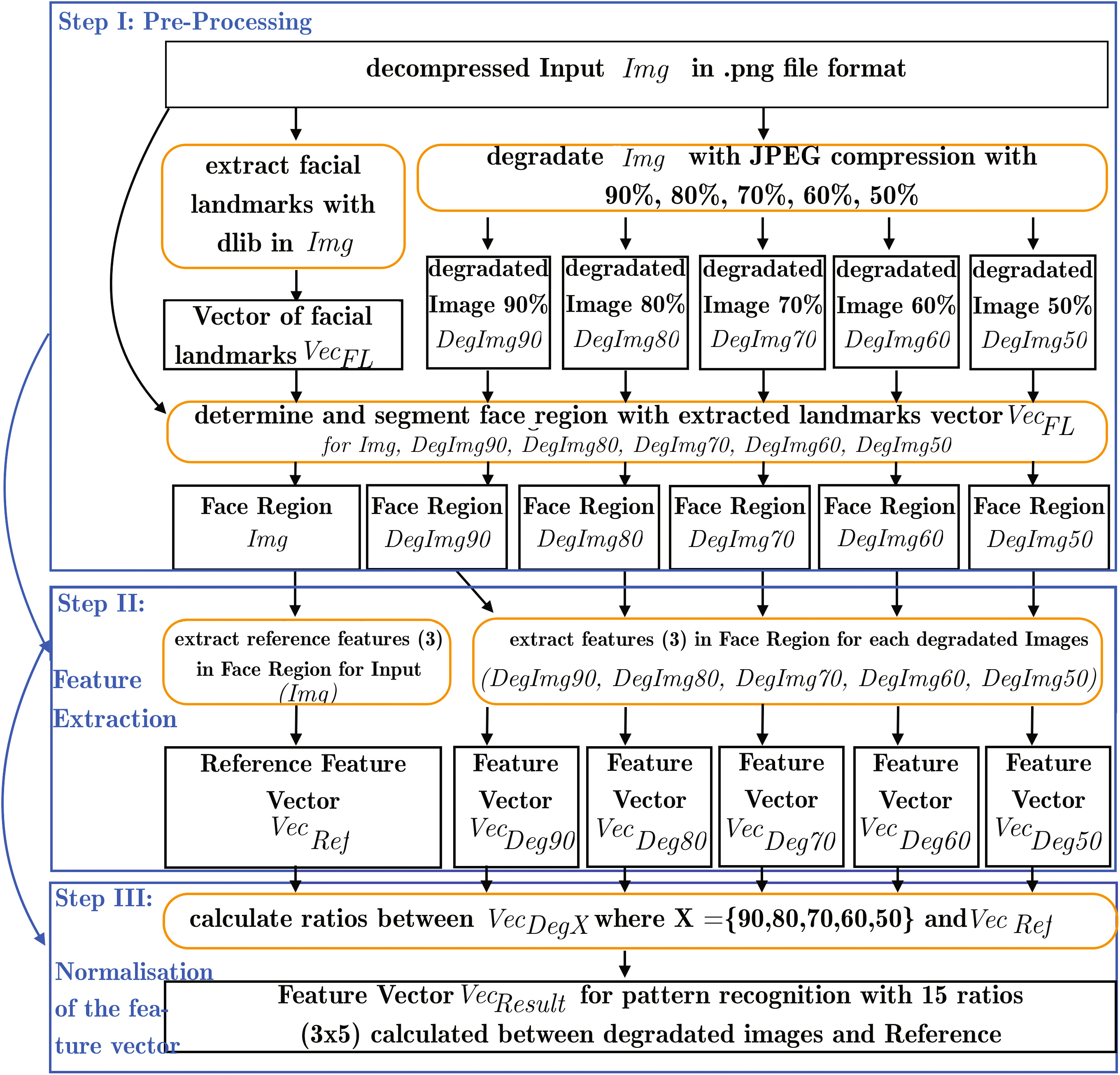
19.2(http://dlib.net/)。面部关键点的坐标保存在向量VecFL中。同时,我们从Img生成五张退化图像DegImgX,对应的JPEG质量级别分别为X={90%,80%,70%,60%,50%}。
通常,可以使用其他方法对图像进行退化处理,例如不同的滤波方法,但我们采用JPEG压缩,因为这是一种标准且广泛使用的图像退化或压缩方法。此外,可以使用更多的JPEG质量参数来更准确地描述退化过程,但我们认为这将导致类似的结果。随后,我们使用VecFL来确定并分割Img和DegImgX的面部关键点的凸包。接着,我们移除所有所用图像(Img和DegImgX)中面部区域凸包以外的任何图像信息。因此,预处理结果得到6张图像(输入Img和5张退化图像DegImgX),这些图像仅包含人脸的面部区域。
然后,在输入图像Img和退化图像DegImgX的面部区域进行特征提取(步骤II)。我们提取三个特征,即检测到的数量
– FAST[10],
– AGAST[11]和
– shiTomasi[12]
角点特征(例如见图3)。为了提取这三种特征,我们使用OpenCV 3.1版本中的现有方法(http://opencv.org/)并采用默认参数设置。从Img中提取的特征将作为从退化图像DegImgX中提取特征的参考。因此,我们将每幅图像提取出的3个特征分别保存在独立的特征向量(VecRef和VecDegX)中。我们使用角点特征检测器,因为它们对JPEG压缩反应敏感,似乎非常适合描述图像中的退化过程。其他特征检测器,例如SIFT[13]或SURF[14],对基于JPEG压缩的退化具有更强的鲁棒性,因此不太适合我们的目的。

特征提取后,在步骤III中进行特征向量归一化。因此,我们使用每种3个特征在退化图像中检测到的角点特征的绝对数量。基本上,我们仅计算退化图像的特征向量与来自输入的参考特征向量VecDegX之间的比值VecRef(VecDeg90.at(0)/VecRef.at(0), …, VecDeg50.at(2)/VecRef.at(2))。最终,我们得到15特征(每幅退化图像提取3个比值,共5幅退化图像)用于Img,用以描述退化过程。我们有意省略了进一步的归一化步骤(例如:通过将检测到的角点特征数量除以人脸像素数量来对图像分辨率进行归一化),以避免扭曲退化过程。
这些特征被保存为带有标签(“变形”或“真实”)的特征向量VecResult,用于基于模式识别的方法来检测变形人脸图像。对于该检测方法,我们通过对两个类别中的所有人脸图像应用所述退化过程,训练一个二分类分类模型Mod。其中一个类别对应真实人脸图像,另一个类别对应变形人脸图像。实验设置在第4节中描述。
4 评估目标和设置
本节介绍了我们基于模式识别的检测方法,并概述了我们的训练和测试数据。此外,我们定义了评估目标。
4.1 评估目标
为了评估我们的退化过程作为检测变形图像中异常的有效方法,我们定义了三个评估目标:
–
G1
:通过10折交叉验证,确定我们的分类模型 Mod 在两种示例性攻击实现下的参考准确率,以评估我们设计的特征空间。
–
G2
:分析退化过程对 Mod 中真实和变形图像特征空间的影响。
–
G3
:确定 Mod 在不同测试数据集上的检测准确率,这些测试数据集未参与训练。
这三个目标在以下小节中描述的三个独立的评估测试(T1, T2, T3)中加以解决。
G1 中的交叉验证模拟了一次实验室测试。在此,检测器在理想条件下进行测试。我们选择10折交叉验证,因为这种方法使用了 Mod 的全部数据作为训练和测试数据,并且相较于单次百分比分割数据的方法,能提供更准确的结果(尤其是关于异常值的处理)。在交叉验证中采用更多的折数并不合适,因为它更加耗时,且结果相当。
G2 用于检验 Mod 特征的区分能力,以验证特征空间,而 G3 旨在通过更接近现实条件的独立测试集来推广 Mod 的检测准确率,这些测试集在第4.2小节中有详细描述。
4.2 评估设置
我们采用一种基于模式识别的方法来分析退化过程并检测变形人脸图像。为此,我们训练了一个包含两个类别的分类模型 Mod
– 类别1: “真实” (600 个样本) 和
– 类别2: “变形” (600 个样本),
并应用第3节中提到的引入的退化过程(见图2)到每个样本。类别“真实”包含自采集的未修改人脸图像,作为我们的真实基准,见图1(人物1和人物2)。所有这些训练图像均遵循国际民航组织标准[15],用于国际护照文件中的图像,以创建一个逼真的护照场景。类别“真实”包含50个不同人物的600个样本,因此我们为每个人使用12张人脸图像,这些图像通过2种不同的相机和不同的参数获取。此外,我们还使用了这两种相机的两个不同实例。通过这种方式,我们试图为训练类别真实创建一个多样化的数据集。我们假设这可以在更真实的测试条件下获得更准确的结果。所使用的参数和相机如表1所示。
| 相机 | 分辨率 | ISO值 |
|---|---|---|
|
2 ∗佳能EOS 1200D
镜头:EF28‐1005 f/4‐5.6 | 2304× 3456 | 100,400 |
|
2 ∗佳能EOS 1200D
镜头:EF28‐1005 f/4‐5.6 | 1728× 2592 | 100 |
| 2 ∗Nikon Coolpix A100 | 1704× 2272 | 100,400 |
| 2 ∗Nikon Coolpix A100 | 1200× 1600 | 100 |
第二个类别“变形”的分类模型使用两种不同攻击类型的自动生成的人脸变形图像进行训练。这两种变形方法在[2]中描述。第一种攻击类型 Morphcomplete 可被视为对包含头发、躯干和背景的完整面部图像进行扭曲与融合的结果。第二种攻击类型 Morphsplicing 通过裁剪面部区域,对其进行扭曲并融合成一个共同面部,再无缝拼接到其中一个输入图像中,从而实现更逼真的效果。图4给出了可视化这两种攻击类型的示例。对于 Morphcomplete 而言,重影伪影几乎可以忽略,因为我们仅使用面部区域的凸包进行本方法的研究,并且我们意识到攻击者可能会移除此类明显可见的伪影。因此,这两种攻击类型都非常适合作为训练和测试数据,因为它们代表了几乎完全消除视觉伪影的真实人脸。这些融合图像从 Authentic 类别的50名受试者中随机生成并选取。为了训练一个无偏分类模型,我们为两个类别各选择600个变形样本。对于 Morphcomplete 获得了200个样本,而对于 Morphsplicing 400 则有更多样本,后一种攻击类型样本数量较多是为了反映其包含两个融合目标(见图4)。
因此,Mod 包含1200个训练样本,用于分析我们的评估目标(G1 − G3)。为了实现这些目标,我们进行了三项测试(T1, T2, T3)。

–
T1
:为了实现 G1,我们在优化条件下进行10折交叉验证,以评估 Mod 的参考准确率。我们使用开源数据挖掘工具 WEKA[16] 版本3.8.0,并采用默认参数设置的逻辑模型树[17](LMT)分类器。LMT 是一种在叶节点处具有逻辑回归函数的决策树。我们测试了多种其他分类器(例如:剪枝后的 C4.5 决策树、朴素贝叶斯、装袋预测器),但 LMT 决策树在我们进行的测试中提供了最精确的结果。
–
T2
:对于 G2,我们研究了来自两个类别 Mod 的特征空间中所有提取的特征。因此,我们对每个特征在每类600个样本上计算其均值。通过这些数据,我们能够可视化变形人脸图像和真实人脸图像在三种提取的角点特征(FAST、AGAST、shiTomasi)上的退化过程。
–
T3
:对于 G3,我们在更现实世界条件下,使用独立测试集评估 Mod 的分类准确率。在对测试数据集进行分类时,我们也采用 LMT 决策树,以使结果与 T1 具有可比性。通过该测试,我们可以了解我们的检测方法在现实世界条件下可能的表现效果。
为了执行 T3,我们确定了 Mod 对来自不同来源的图像的分类准确率。因此,我们创建了六个独立的测试数据集。其中三个基于 Utrecht ECVP [18](一个公开的人脸参考数据库)生成。我们使用不微笑的乌得勒支真实人脸图像构建 Morphcomplete(1326个样本)和 Morphsplicing(2614个样本)。此外,我们还使用了与训练数据中相同的50名受试者的400张自采真实人脸图像,但这些数据采用了两台不同的相机(2×尼康 D3300,镜头:尼克尔镜头:AF‐S 50mm f/1.8G),并设置了不同的参数(分辨率:2000× 2992、3000× 4496,ISO值:100、400)。因此,我们为每个人采集了8张图像。基于这些数据,我们为两个独立的测试数据集生成了完整的融合变形和拼接变形。表2给出了测试数据集的概述。我们注意到,这三个自采集的测试数据集与训练数据并非完全独立,因为50名测试人员是相同的。但我们认为,不同的采集参数(相机、镜头和分辨率)应能使测试数据相对于训练数据保持无偏性。接下来的部分将展示所述三项测试(T1、T2、T3)的评估结果。
| 名称 | 分辨率 | 类型 | 类别 | 样本库 | 来源 |
|---|---|---|---|---|---|
| TDSAuthentic−Utrecht | 900× 1200 | 真实 | Authentic | 73 | 乌得勒支 [18] |
| TDSMorphSplicing−Utrecht | 900× 1200 | Morphsplicing | Morphing | 2614 | 乌得勒支 [18] |
| TDSMorphComplete−Utrecht | 900× 1200 | Morphcomplete | Morphing | 1326 | 乌得勒支 [18] |
| TDSAuthentic−AMSL | 2000× 2992 | 真实 | Authentic | 400 | 自采集 |
| TDSAuthentic−AMSL | 3000× 4496 | 真实 | Authentic | 400 | 自采集 |
| TDSMorphSplicing−AMSL | 2000× 2992 | Morphsplicing | Morphing | 300 | 自采集 |
| TDSMorphComplete−AMSL | 2000× 2992 | Morphcomplete | Morphing | 100 | 自采集 |
5 评估结果
本节说明了我们三项测试的结果(第4.2节)。此外,我们还讨论了是否实现了我们的评估目标(第4.1节)。
在 T1 中,我们评估了分类模型 Mod 的准确性。该测试确定了在优化条件下,针对我们示例性的两种合成攻击类型(Morphsplicing 和 Morphcomplete)的参考检测准确率(G1)。表3显示了 T1 的结果。
| 真实 | 变形 | ← 分类为 |
|---|---|---|
| 89.0% | 11.0% | 真实(真实) |
| 8.7% | 91.3% | 变形(真实) |
参考分类准确率为 Mod,达到90.2%(G1)。因此,退化过程对真实人脸图像的影响并不像我们假设的那样显著。例如,“平滑”真实人脸的检测准确率并不如预期理想,因为在退化过程中边缘关键点的减少程度与变形人脸图像相似。
为了分析退化过程对变形的人脸图像和真实人脸图像(G2)的影响,我们进行了第二次测试 T2。为此,我们比较了均值
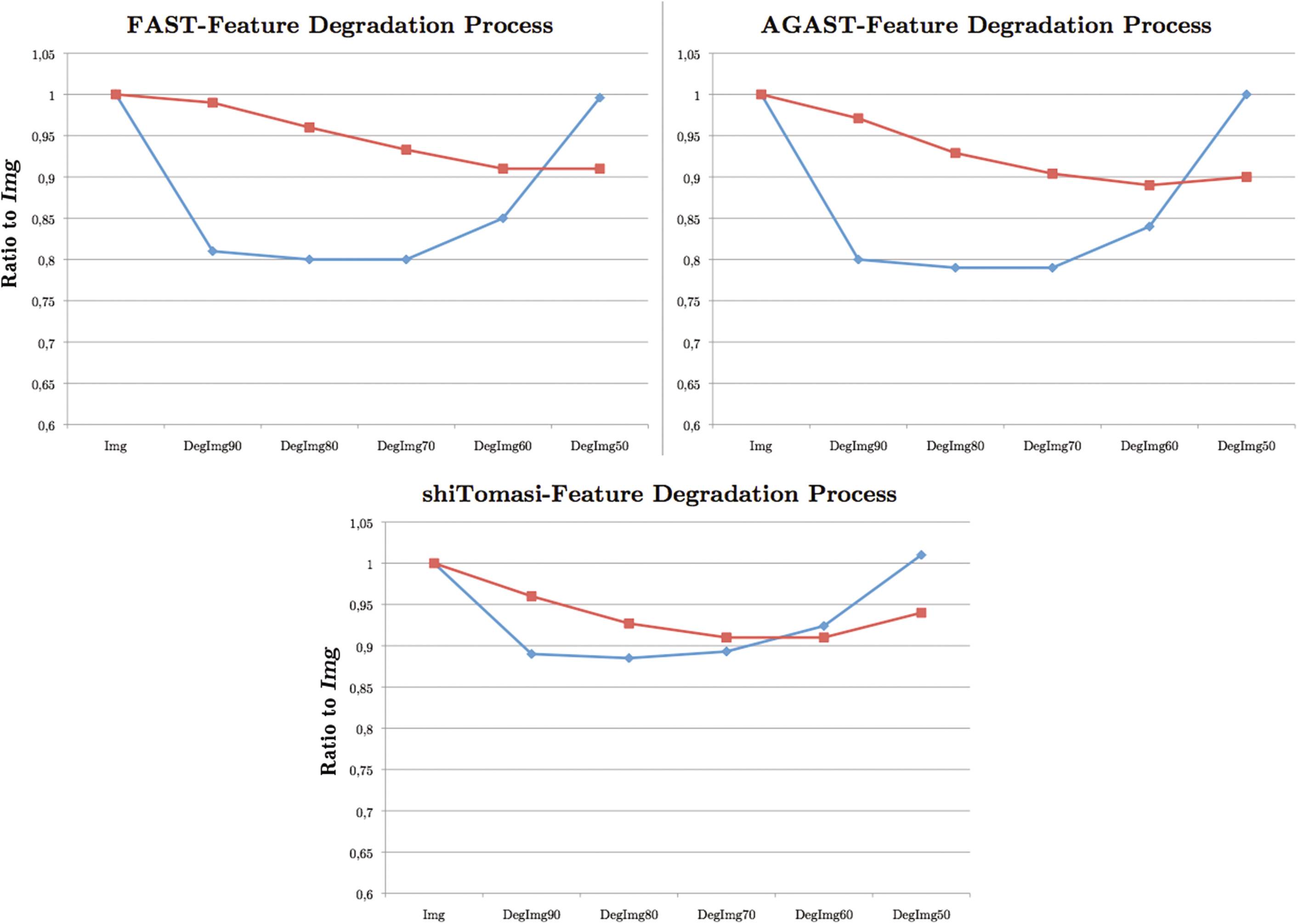
基于 Mod 的训练样本,每种角点检测器(FAST, AGAST, shiTomasi)的提取特征值。图5显示了退化过程对真实和变形人脸图像的影响存在显著差异。
退化过程对真实人脸图像的影响在所有三个角点特征上均大于对变形人脸图像的影响。在有损退化图像(DegImg60 和 DegImg50)上,由于检测到 JPEG 压缩伪影,三种特征的变形人脸图像所检测到的角点特征数量均有所增加。但我们也可以观察到,shiTomasi 角点检测器相较于其他两种检测器对退化更具鲁棒性。因此,shiTomasi 角点特征相比 FAST 和 AGAST 角点检测器提取的特征不具备同等程度的区分能力。最终我们可以断定,退化过程对使用 FAST 和 AGAST 角点特征的真实人脸图像具有显著影响,相比之下对变形人脸图像的影响较小。因此 T2 验证并证明了我们选择特征空间的合理性,同时也激励我们寻找更合适的特征来描述退化过程。
在 T3 我们希望在更现实的条件下评估我们的分类模型 Mod。为此,我们确定了 Mod 在6个独立且分离的测试数据集(G3)上的检测准确率,总结见表2。T3 的结果如表4所示。T3 在人脸
| 测试数据集 | 真实 | 变形 |
|---|---|---|
| TDSAuthentic−Utrecht | 19.2% | 80.8% |
| TDSMorphSplicing−Utrecht | 16.9% | 83.1% |
| TDSMorphComplete−Utrecht | 10.9% | 89.1% |
| TDSAuthentic−AMSL | 77.5% | 22.5% |
| TDSMorphSplicing−AMSL | 3.7% | 96.3% |
| TDSMorphComplete−AMSL | 10.0% | 90.0% |
面部图像变造在独立测试数据集上的检测准确率,以进行初步评估。在全部四个变形测试数据集中,我们实现了85.9%的检测准确率(4340个样本中有3732个正确分类样本)。但真实人脸图像的检测性能不如预期,在两个真实测试数据集上的准确率为68.4%(473个样本中有324个正确分类)。最终,该方法在所有测试样本上的总体检测准确率为84.3%(4813个样本中有4056个正确分类)。
TDSAuthentic−Utrecht 的错误分类样本数量较多,原因可以解释如下:该数据集中的样本已经多次经过 JPEG 压缩。因此,退化过程对样本的影响与人脸融合图像更为相似,而不是直接从相机拍摄的图像。所以,我们建议在国际护照文件中使用的图像应采用严格的压缩策略。此外,由于 T1 中提到的原因,TDSAuthentic−AMSL 的误报率仍然较高(22.5%)。我们希望未来可以通过其他机制来抑制误报率,从而作为安全系统的一部分支持本方法。最后,三项测试(T1、T2、T3)的结果表明,我们的退化过程在检测人脸变形伪造方面具有前景。该结果对于初步评估而言是可接受的,若能增加训练数据并采用更具针对性的退化步骤,该方法有望取得更好的效果。
6 结论与未来工作
本文提出了一种基于图像退化的新型人脸变形伪造检测方法。这是一种有前景的盲异常检测方法,通过自建人工参考图像进行工作。我们介绍了退化过程的设计,并实施了基于模式识别的检测方法。我们实现了一个初步的测试设置以评估该方法的性能。实验结果表明,该过程在实验室条件下表现良好。在此情况下,我们的分类模型对人脸变形伪造的总体检测准确率达到91.3%。此外,我们还对变形图像和真实人脸图像的退化过程影响进行了可视化比较。这种比较显示出两类图像之间存在显著差异,从而验证了我们的特征空间。
图像之间的显著差异验证了我们的特征空间。随后,我们在六种不同的测试数据集上评估了分类模型在更接近实际条件下的准确性。该评估显示,对于人脸变形图像的检测准确率为85.9%,但在正确分类真实图像方面存在困难(68.4%)。因此,误报率在实际应用中尚不可接受,若要将该过程应用于实际场景,则必须加以改进。总体而言,该退化过程在检测人脸变形方面具有潜力,鼓励对该方法进行进一步研究。
在未来的工作中,构建更大的真实标注训练数据集有助于训练更精细的分类模型,有望提供更准确的评估结果。此外,应提高退化过程的粒度,以观察是否能带来更好的分类结果。而且,退化过程可以采用其他退化处理方法进行,例如中值滤波。目前,我们的方法基于三个角点检测器来描述退化过程。通过引入更多对退化敏感的特征来扩展特征空间,将具有重要意义。

















 35
35

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









