







 本文通过分析kaggle的'give me some credit'竞赛数据,运用逻辑回归、cart决策树、神经网络、xgboost和随机森林等模型进行用户贷款风险预测。通过数据清洗、异常值处理和模型评估,得出xgboost模型的精确度最高,达到0.860617。
本文通过分析kaggle的'give me some credit'竞赛数据,运用逻辑回归、cart决策树、神经网络、xgboost和随机森林等模型进行用户贷款风险预测。通过数据清洗、异常值处理和模型评估,得出xgboost模型的精确度最高,达到0.860617。
作者介绍:皮吉斯,热爱R语言,知乎号:皮吉斯
本次的分析数据来自kaggle数据竞赛平台的“give me some credit”竞赛项目。任务是提高模型精度AUC。
本次分析用到了多种算法,分别有:逻辑回归,cart决策树,神经网络,xgboost,随机森林。通过多种模型相互对比,最终根据auc选出最好的模型。
分析步骤:
1. 导入数据
2. 数据清洗及准备
3. 模型建立,
4. 模型评估
5. 多模型对比
下面正式开始吧!
一. 导入数据
cs_training <- read.csv("cs_training.csv")
names(cs_training)
a <- cs_training
a1 <- cs_training
colnames(a)<-c('id','response','x1','age','x2','debtratio','monthlyincome','x3','x4','x5','x6','x7')
导入数据,并对列名重命名,方便分析。
各字段的解释如下:

通过summary了解数据的整体情况,可以看到monthliincome和x7变量有缺失值

二. 数据清洗
# age变量
age<-a$age
var_age<-c(var="age",
mean=mean(age,na.rm=TRUE),#na.rm=TRUE去除NA的影响
median=median(age,na.rm=TRUE),
quatile(age,c(0,0.01,0.1,0.25,0.5,0.75,0.9,0.99,1),na.rm=TRUE),
max=max(age,na.rm=TRUE),
missing=sum(is.na(age)) )

这样可以看到各个变量的数据分布情况
# 查看异常值
boxplot(age~response,data = a,horizontal = T ,frame = F , col = "lightgray",main = "Distribution")
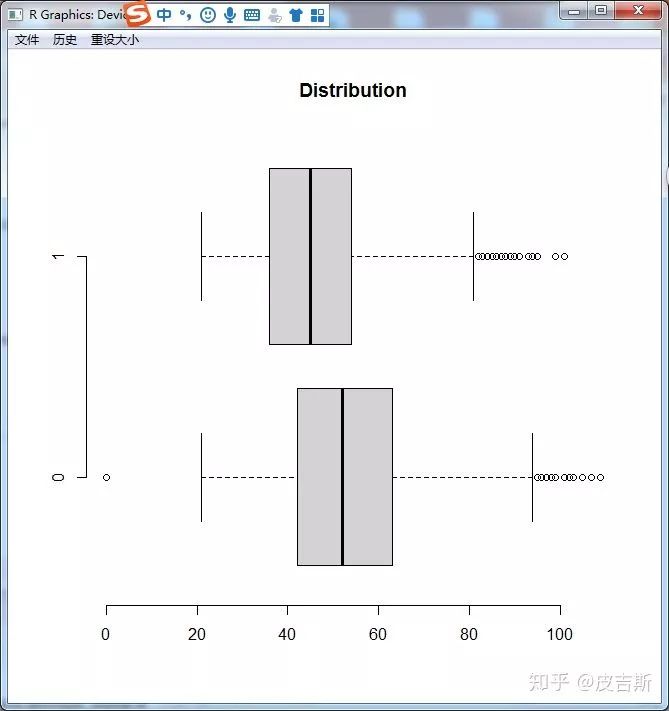
上图可以看到,数据存在异常值。
处理异常值:通常采用盖帽法,即用数据分布在1%的数据覆盖在1%以下的数据,用在99%的数据覆盖99%以上的数据。
block<-function(x,lower=T,upper=T){
if(lower){
q1<-quantile(x,0.01)
x[x<=q1]<-q1
}
if(upper){
q99<-quantile(x,0.99)
x[x>q99]<-q99
}
return(x)
}
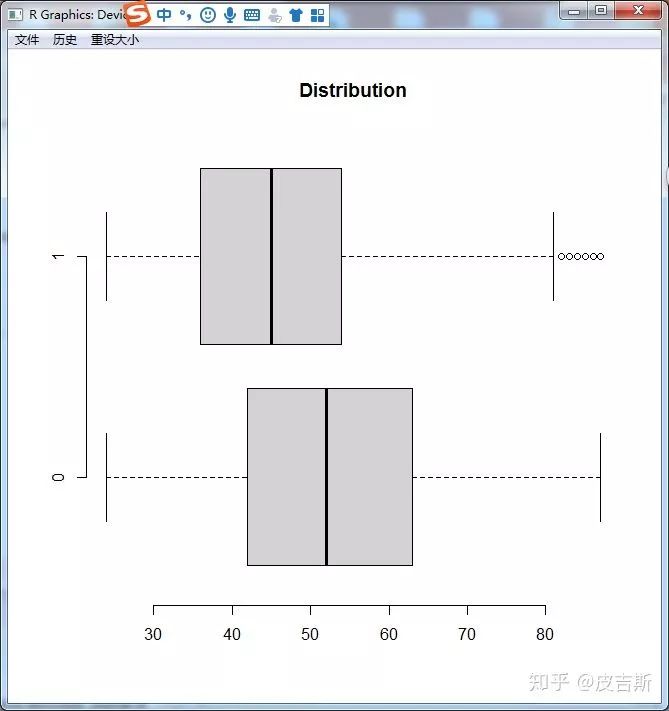
经过处理,异常值大量减少
# x1
xa1<-a$x1
var_x1<-c(var='xa1',
mean=mean(xa1,na.rm = T),
median=median(xa1,na.rm = T),
quantile(xa1,c(0,0.01,0.1,0.5,0.75,0.9,0.99,1),na.rm = T), max=max(xa1,na.rm = T),
miss=sum(is.na(xa1)) )
boxplot(x1~response,data=a,horizontal=T, frame=F, col="lightgray",main="Distribution")
#对X1变量进行处理
a$x1<-block(a$x1)
# x2
a$x2
summary(a$x2)
xa2<-a$x2
var_x2<-c(var='xa2',
mean=mean(xa2,na.rm = T),
median=median(xa2,na.rm = T),
quantile(xa2,c(0,0.01,0.1,0.5,0.75,0.9,0.99,1),na.rm = T), max=max(xa2,na.rm = T),
miss=sum(is.na(xa2)) )
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









