






深度强化学习算法:DDPG TD3 SAC
实验环境:机器人MuJoCo
YID:7750717083674322
什么都会的超级工科男
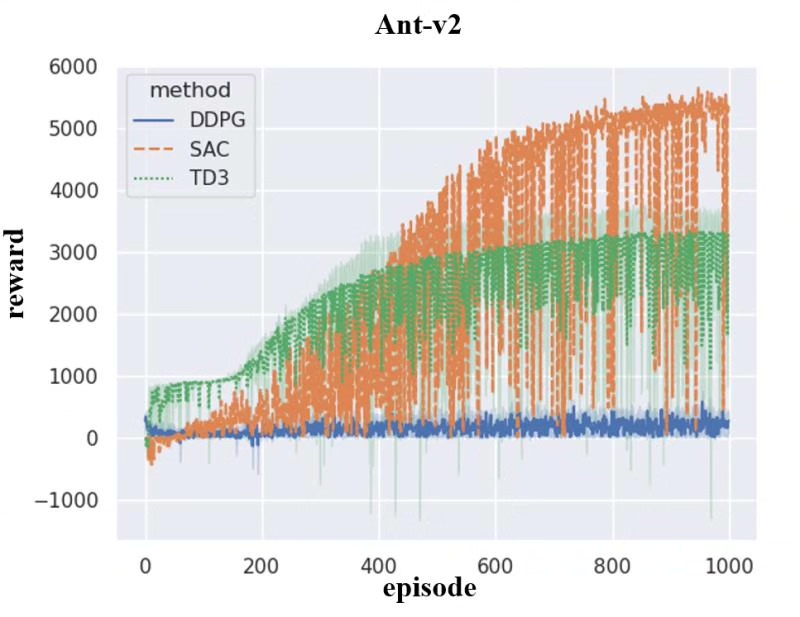
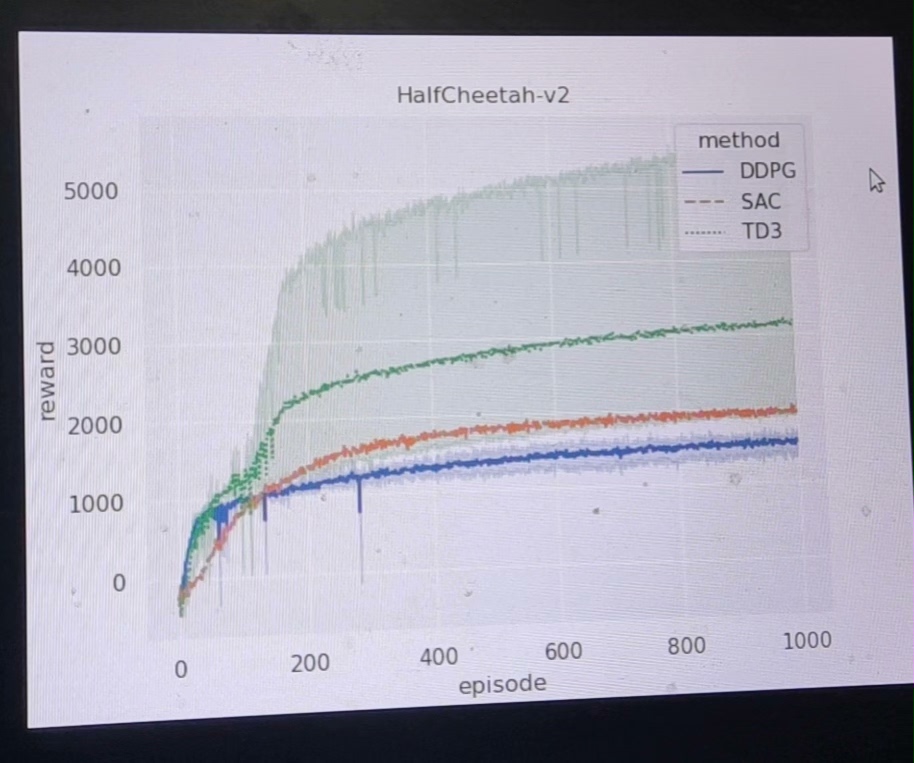
深度强化学习算法是当今人工智能领域的热点研究方向之一。它通过结合深度学习和强化学习的方法,使得机器能够通过大量的样本数据进行训练并逐步优化自身的决策能力。DDPG、TD3和SAC是深度强化学习中的三个重要算法,它们在解决连续动作空间的问题上具有独特的优势。本文将围绕这三个算法展开论述,并以机器人MuJoCo作为实验环境进行验证。
首先,我们来介绍一下DDPG算法。DDPG是一种基于策略梯度的强化学习算法,它通过构建一个Q函数网络和一个策略网络来实现对连续动作空间的建模。Q函数网络用于评估给定状态和动作对的奖励值,而策略网络则被训练用于生成最优的动作。通过交替训练和更新,DDPG算法能够逐步提升机器的决策能力,并在实验中取得了显著的效果。
接下来,我们介绍TD3算法。TD3是DDPG算法的改进版,在原有的基础上引入了三个技巧来进一步提升算法的性能。首先是延迟更新技巧,即将目标网络的更新频率降低,从而减少训练过程中的振荡。其次是双Q网络技巧,使用两个独立的Q网络来评估动作的质量,以减少过度估计和提高稳定性。最后是噪声干扰技巧,通过添加噪声来探索更广泛的动作空间。这些改进使得TD3算法在处理连续动作空间的问题上更加高效和稳定。
最后,我们介绍SAC算法。SAC是一种基于最大熵理论的强化学习算法,它通过最大化系统熵来实现更好的探索和利用平衡。与传统的强化学习算法不同,SAC能够在充分探索环境的同时,保持策略的多样性,从而更好地应对复杂的连续动作空间。在机器人MuJoCo环境中的实验结果显示,SAC算法在性能上比DDPG和TD3有了显著的提升。
综上所述,DDPG、TD3和SAC是深度强化学习中的三个重要算法。它们在解决连续动作空间的问题上具有独特的优势,能够有效地提升机器的决策能力。在机器人MuJoCo环境的实验中,它们都取得了较好的性能表现。未来,我们可以进一步探索这些算法的应用领域,并结合其他技术手段对其进行进一步优化和拓展。
以上相关代码,程序地址:http://wekup.cn/717083674322.html















 1225
1225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









