







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
>
> 这个配置文件描述了一个名为 `es-kibana` 的 Kubernetes Service,该 Service 不分配 Cluster IP(`ClusterIP: None`),它会将流量路由到具有特定标签 `app: es-kibana` 的 Pod,这些 Pod 的端口 9200 和 9300 将被公开,并且可以通过相应的 `targetPort` 进行访问。用于集群内部访问
>
>
>
###### 8.创建es-kibana的nodeport类型的svc
vi es-nodeport-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: es-kibana
name: es-kibana-nodeport-svc
namespace: kube-system
spec:
ports:
- name: 9200-9200
port: 9200
protocol: TCP
targetPort: 9200
#nodePort: 9200
- name: 5601-5601
port: 5601
protocol: TCP
targetPort: 5601
#nodePort: 5601
selector:
app: es-kibana
type: NodePort
kubectl apply -f es-nodeport-svc.yaml
>
> 这个配置文件创建了一个名为 “es-kibana-nodeport-svc” 的 Kubernetes Service。该 Service 使用 NodePort 类型,允许从集群外部访问服务。Service 公开了两个端口,9200 和 5601,分别将流量路由到具有相应标签的 Pod 的对应端口。Pod 的选择基于标签 `app: es-kibana`。用于暴露端口,从集群外部访问es和kibana
>
>
>
外网暴露的端口是k8s随机分配的,有两种办法可以查看
#在服务器使用命令查看
kubectl get svc -n kube-system|grep es-kibana

Rancher上查看
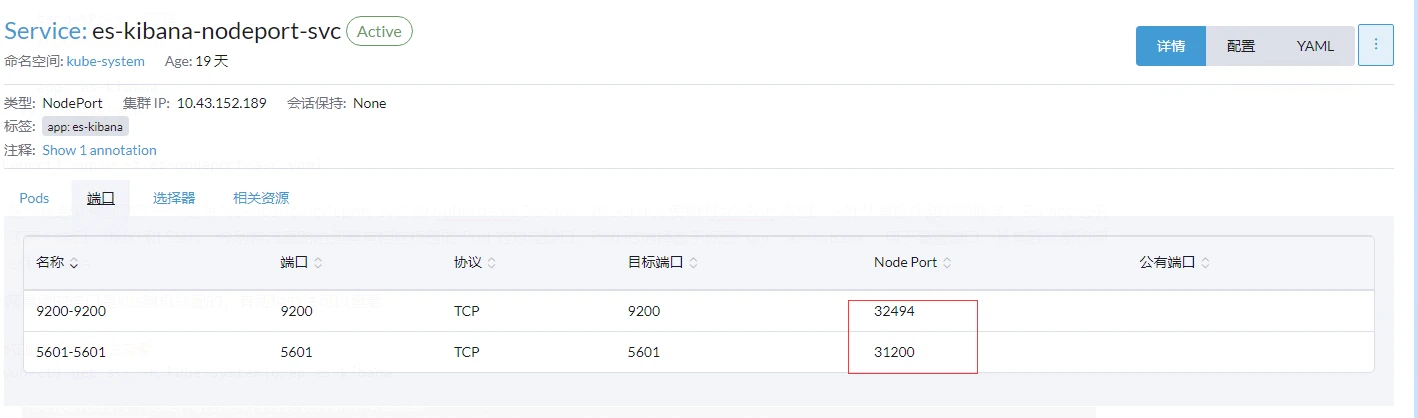
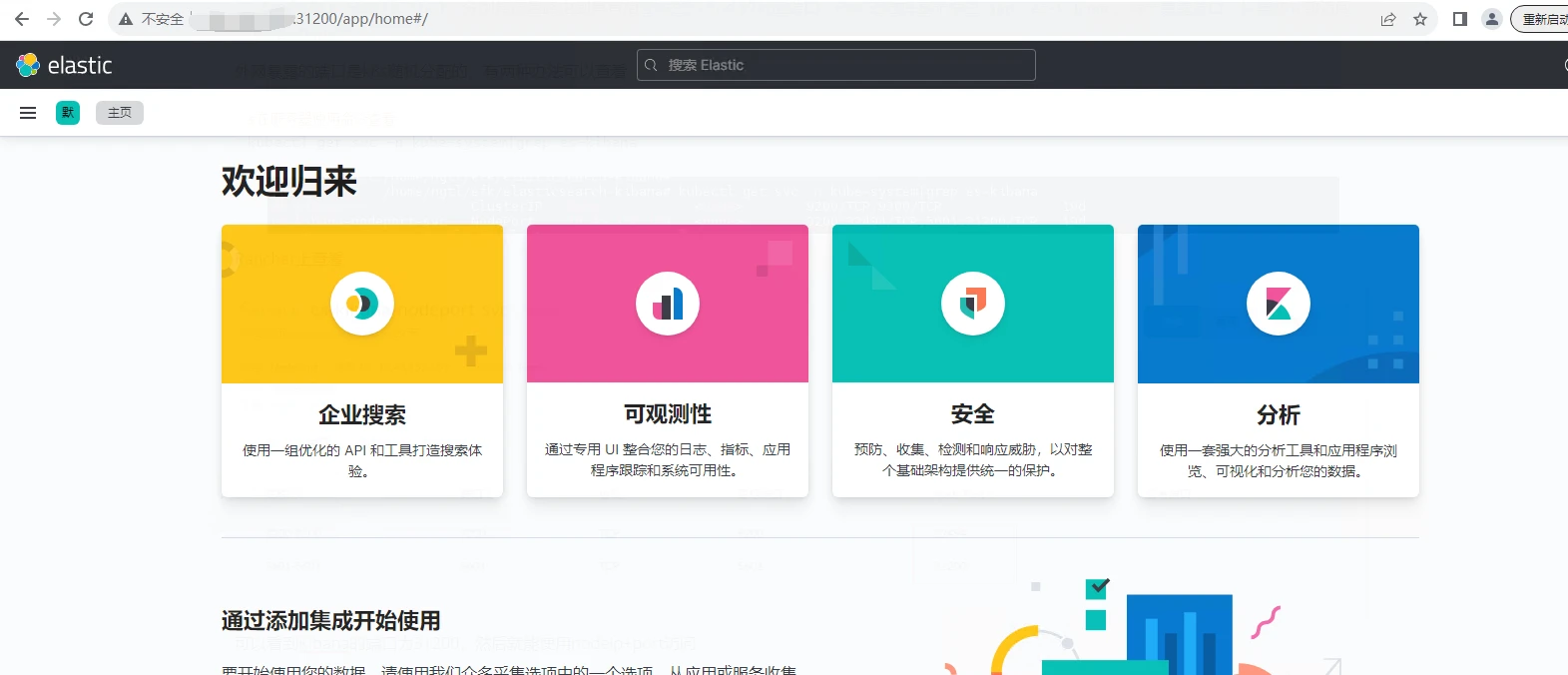
可以看到Kibana的端口为31200,然后就能使用nodeip+port访问
检查es是否注册上Kibana,点击侧边栏找到堆栈检测,然后点Nodes
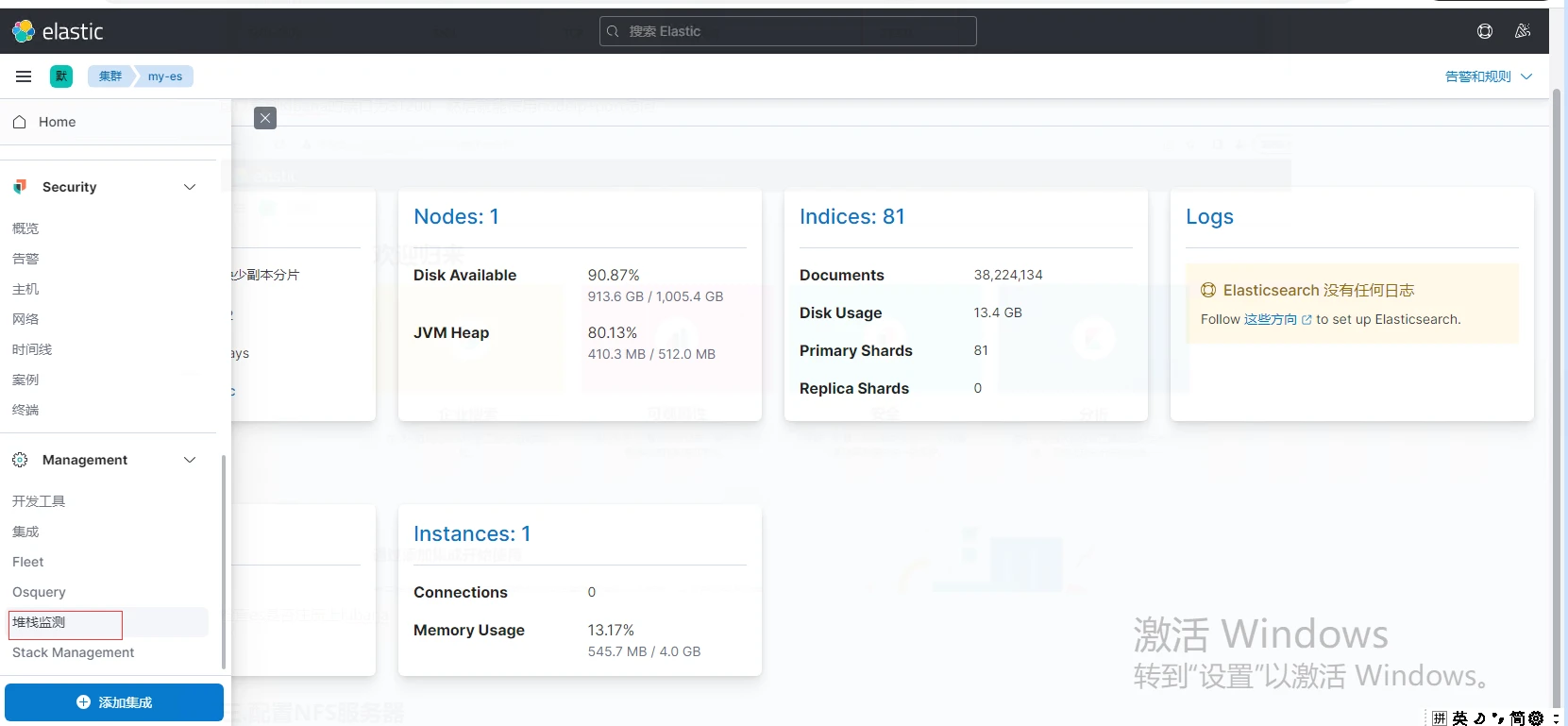
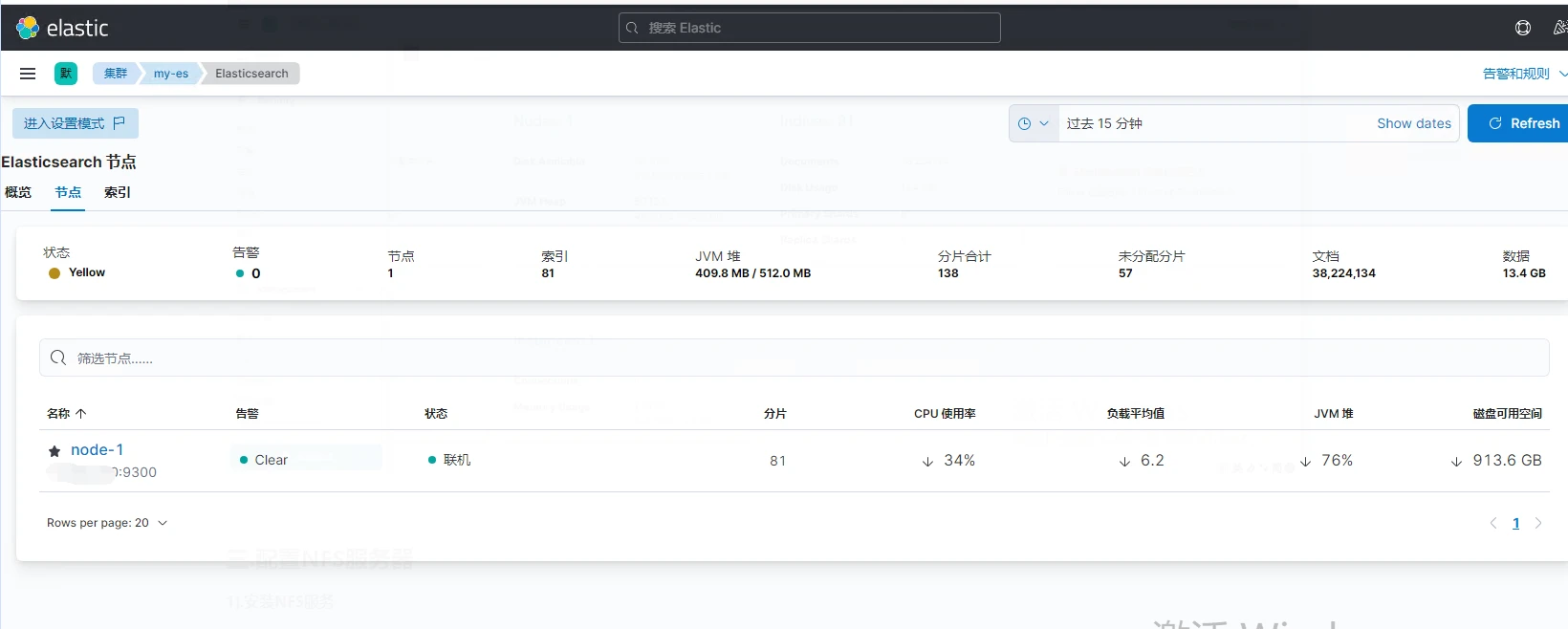
至此,Elasticsearch + kibana已经搭建完成,可以进行第四步。
---
#### 三.配置NFS服务器
###### 1).安装NFS服务
Ubuntu:
sudo apt update
sudo apt install nfs-kernel-server
Centos:
yum update
yum -y install nfs-utils
创建或使用用已有的文件夹作为nfs文件存储点
mkdir -p /home/data/nfs/share
vi /etc/exports
写入如下内容
>
> /home/data/nfs/share \*(rw,no\_root\_squash,sync,no\_subtree\_check)
>
>
>

配置生效并查看是否生效
exportfs -r
exportfs

启动rpcbind、nfs服务
#Centos
systemctl restart rpcbind && systemctl enable rpcbind
systemctl restart nfs && systemctl enable nfs
#Ubuntu
systemctl restart rpcbind && systemctl enable rpcbind
systemctl start nfs-kernel-server && systemctl enable nfs-kernel-server
查看 RPC 服务的注册状况
rpcinfo -p localhost
showmount测试
showmount -e localhost

以上都没有问题则说明安装成功
###### 2).k8s注册nfs服务
新建storageclass-nfs.yaml文件,粘贴如下内容:
创建了一个存储类
apiVersion: storage.k8s.io/v1
kind: StorageClass #存储类的资源名称
metadata:
name: nfs-storage #存储类的名称,自定义
annotations:
storageclass.kubernetes.io/is-default-class: “true” #注解,是否是默认的存储,注意:KubeSphere默认就需要个默认存储,因此这里注解要设置为“默认”的存储系统,表示为"true",代表默认。
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner #存储分配器的名字,自定义
parameters:
archiveOnDelete: “true” ## 删除pv的时候,pv的内容是否要备份
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
replace with namespace where provisioner is deployed
namespace: default
spec:
replicas: 1 #只运行一个副本应用
strategy: #描述了如何用新的POD替换现有的POD
type: Recreate #Recreate表示重新创建Pod
selector: #选择后端Pod
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner #创建账户
containers:
- name: nfs-client-provisioner
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nfs-subdir-external-provisioner:v4.0.2 #使用NFS存储分配器的镜像
volumeMounts:
- name: nfs-client-root #定义个存储卷,
mountPath: /persistentvolumes #表示挂载容器内部的路径
env:
- name: PROVISIONER_NAME #定义存储分配器的名称
value: k8s-sigs.io/nfs-subdir-external-provisioner #需要和上面定义的保持名称一致
- name: NFS_SERVER #指定NFS服务器的地址,你需要改成你的NFS服务器的IP地址
value: 192.168.0.0 ## 指定自己nfs服务器地址
- name: NFS_PATH
value: /home/data/nfs/share ## nfs服务器共享的目录 #指定NFS服务器共享的目录
volumes:
- name: nfs-client-root #存储卷的名称,和前面定义的保持一致
nfs:
server: 192.168.0.0 #NFS服务器的地址,和上面保持一致,这里需要改为你的IP地址
path: /home/data/nfs/share #NFS共享的存储目录,和上面保持一致
apiVersion: v1
kind: ServiceAccount #创建个SA账号
metadata:
name: nfs-client-provisioner #和上面的SA账号保持一致
replace with namespace where provisioner is deployed
namespace: default
#以下就是ClusterRole,ClusterRoleBinding,Role,RoleBinding都是权限绑定配置,不在解释。直接复制即可。
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [ “” ]
resources: [ “nodes” ]
verbs: [ “get”, “list”, “watch” ] - apiGroups: [ “” ]
resources: [ “persistentvolumes” ]
verbs: [ “get”, “list”, “watch”, “create”, “delete” ] - apiGroups: [ “” ]
resources: [ “persistentvolumeclaims” ]
verbs: [ “get”, “list”, “watch”, “update” ] - apiGroups: [ “storage.k8s.io” ]
resources: [ “storageclasses” ]
verbs: [ “get”, “list”, “watch” ] - apiGroups: [ “” ]
resources: [ “events” ]
verbs: [ “create”, “update”, “patch” ]
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisionerreplace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
replace with namespace where provisioner is deployed
namespace: default
rules:
- apiGroups: [ “” ]
resources: [ “endpoints” ]
verbs: [ “get”, “list”, “watch”, “create”, “update”, “patch” ]
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
replace with namespace where provisioner is deployed
namespace: default
subjects:
- kind: ServiceAccount
name: nfs-client-provisionerreplace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
需要修改的就只有服务器地址和共享的目录
创建StorageClass
kubectl apply -f storageclass-nfs.yaml
查看是否存在
kubectl get sc

---
#### 四.创建filebeat服务
###### 1.创建filebeat主配置文件filebeat.settings.configmap.yml
vi filebeat.settings.configmap.yml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: kube-system
name: filebeat-config
labels:
app: filebeat
data:
filebeat.yml: |-
filebeat.inputs:
- type: container
enabled: true
paths:
- /var/log/containers/*.log
include_lines: [‘ERROR’, ‘WARN’]
multiline:
pattern: ^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}
negate: true
match: after
processors:
- add_kubernetes_metadata:
in_cluster: true
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: “/var/log/containers/”
- add\_cloud\_metadata:
- add\_kubernetes\_metadata:
matchers:
- logs\_path:
logs\_path: "/var/log/containers/"
- add\_docker\_metadata:
output.elasticsearch:
hosts: ["http://[k8s节点ip]:32494"]
index: "filebeat-demo-%{[agent.version]}-%{+yyyy.MM.dd}"
setup.template.name: "filebeat-demo"
setup.template.pattern: "filebeat-demo-\*"
setup.ilm.rollover\_alias: "filebeat-demo"
setup.ilm:
policy\_file: /etc/indice-lifecycle.json
#执行
kubectl apply -f filebeat.settings.configmap.yml
>
> `filebeat.inputs`: 定义输入配置,这里配置了从容器日志中收集数据。
>
>
> * `type`: 定义输入类型为 container,表示从容器日志中收集数据。
> * `enabled`: 启用该输入配置。
> * `paths`: 指定要监视的日志文件路径,这里是容器日志路径。k8s容器的日志默认是保存在在服务器的/var/log/containers/下的。
> * `multiline`: 多行日志配置,用于将多行日志合并为单个事件。正则表示如果前面几个数字不是4个数字开头,那么就会合并到一行,解决Java堆栈错误日志收集问题
> * `processors`: 定义处理器,用于添加元数据。add\_kubernetes\_metadata:为日志事件添加 Kubernetes 相关的元数据信息,例如 Pod 名称、命名空间、标签等。
>
>
> `output.elasticsearch`: 定义输出配置,将收集到的日志发送到 Elasticsearch。
>
>
> * `hosts`: 指定 Elasticsearch 节点的地址和端口。端口号为第二步安装es时,nodeport暴露的端口号。
> * `indices`: 定义索引模式,这里以日期为后缀,创建每日索引。
>
>
> `setup.ilm`: 配置索引生命周期管理 (ILM),用于管理索引的生命周期。
>
>
> * policy\_file:后面定义的是生命周期配置文件的地址
>
>
>
>
> 此处禁用了filebeat默认的索引格式。默认的索引格式为filebeat-%{[agent.version]}-%{+yyyy.MM.dd},在Kibana上呈现的就是filebeat-2023.10.21-000001这样的索引命名格式,而且默认的索引模板和索引生命周期都与index中设置的filebeat-demo-%{[agent.version]}-%{+yyyy.MM.dd}无关。故出现的问题就是我们所需的日志内容在索引filebeat-demo-%{[agent.version]}-%{+yyyy.MM.dd}中,但是并不能被准确分片和使用索引生命周期管理。
>
>
> **#相关模板字段意义**
>
>
> setup.template.name: “filebeat-demo” # 设置一个新的模板,模板的名称为filebeat-demo
>
>
> setup.template.pattern: “filebeat-demo-\*” # 模板匹配那些索引,这里表示以filebeat-demo开头的所有的索引
>
>
> setup.ilm.rollover\_alias: “filebeat-demo” #索引生命周期写别名。默认值为 `filebeat-%{[agent.version]}`。设置此选项将更改别名为filebeat-demo。用以滚动更新大索引文件的分片
>
>
>
>
> 同时该配置过滤了其他info级别的日志,只收集了’ERROR’, 'WARN’级别的日志,相关配置:
>
>
> include\_lines: [‘ERROR’, ‘WARN’] 该配置可根据实际使用情况进行删改
>
>
>
下图为,索引格式配置正确的示范截图:



###### 2.创建Filebeat索引生命周期策略配置文件
为了防止大量的数据存储,可以利用 indice 的生命周期来配置数据保留。 如下所示的文件中,配置成每天或每次超过5GB的时候就对 indice 进行轮转,并删除所有超过30天的 indice 文件。
vi filebeat.indice-lifecycle.configmap.yml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: kube-system
name: filebeat-indice-lifecycle
labels:
app: filebeat
data:
indice-lifecycle.json: |-
{
“policy”: {
“phases”: {
“hot”: {
“actions”: {
“rollover”: {
“max_size”: “5GB” ,
“max_age”: “1d”
}
}
},
“delete”: {
“min_age”: “30d”,
“actions”: {
“delete”: {}
}
}
}
}
}
#执行
kubectl apply -f filebeat.indice-lifecycle.configmap.yml
###### 3.Filebeat操作权限
vi filebeat.permission.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat
rules:
- apiGroups: [ “” ]
resources:- namespaces
- pods
- nodes
verbs: - get
- watch
- list
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
apiVersion: v1
kind: ServiceAccount
metadata:
namespace: kube-system
name: filebeat
#执行
kubectl apply -f filebeat.permission.yml
>
> 1. **ClusterRole**:
> * **作用**:定义了一个 ClusterRole,它是一种权限集合,指定了 Filebeat 在集群范围内可以执行的操作,如获取(get)、监视(watch)、列出(list)等。
> * 权限:
> + 可以对命名空间执行 get、watch、list 操作。
> + 可以对 Pod 执行 get、watch、list 操作。
> + 可以对节点执行 get、watch、list 操作。
> 2. **ClusterRoleBinding**:
> * **作用**:定义了一个 ClusterRoleBinding,将 ClusterRole (`filebeat`) 绑定到特定的 ServiceAccount (`filebeat`)。
> * **意义**:将 ClusterRole 与 ServiceAccount 绑定,以使 Filebeat 具有在 Kubernetes 中执行相应操作的权限。
> 3. **ServiceAccount**:
> * **作用**:定义了一个 ServiceAccount (`filebeat`),它是 Kubernetes 中用于身份验证和授权的实体。
> * **意义**:创建了一个用于 Filebeat 的身份实体,使得 Filebeat 在 Kubernetes 中能够以其身份运行。
>
>
>
###### 4.Filebeat Daemonset配置文件
vi filebeat.daemonset.yml
apiVersion: apps/v1
kind: DaemonSet
metadata:
namespace: kube-system
name: filebeat
labels:
app: filebeat
spec:
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
containers:
- name: filebeat
image: [ Harbor私服地址 ]/filebeat:7.17.2
args: [
“-c”, “/etc/filebeat.yml”,
“-e”,
]
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
runAsUser: 0
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: filebeat-indice-lifecycle
mountPath: /etc/indice-lifecycle.json
readOnly: true
subPath: indice-lifecycle.json
- name: data
mountPath: /usr/share/filebeat/data
- name: varlog
mountPath: /var/log
readOnly: true
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: dockersock
mountPath: /var/run/docker.sock
volumes:
- name: config
configMap:
defaultMode: 0600
name: filebeat-config
- name: filebeat-indice-lifecycle
configMap:
defaultMode: 0600
name: filebeat-indice-lifecycle
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: dockersock
hostPath:
path: /var/run/docker.sock
- name: data
hostPath:
path: /var/lib/filebeat-data
type: DirectoryOrCreate
#执行
kubectl apply -f filebeat.daemonset.yml
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
dice-lifecycle
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: dockersock
hostPath:
path: /var/run/docker.sock
- name: data
hostPath:
path: /var/lib/filebeat-data
type: DirectoryOrCreate
#执行
kubectl apply -f filebeat.daemonset.yml
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-ctiRInqh-1713304600905)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 659
659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









