







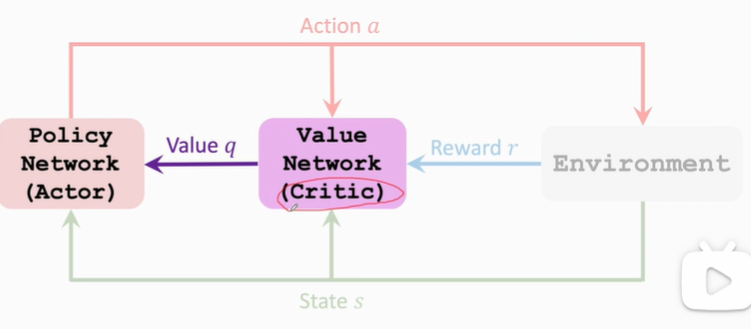
1. Value Network and Policy Network
-
State-Value Function Approximation V π = ∑ a π ( a ∣ s ) ⋅ Q π ( s , a ) V_\pi=\sum_a\pi(a|s)·Q_\pi(s,a) Vπ=∑aπ(a∣s)⋅Qπ(s,a)
Policy network(actor): π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ)
Value network(critic): q ( s , a ; w ) q(s,a;w) q(s,a;w)
V π = ∑ a π ( a ∣ s ) ⋅ Q π ( s , a ) ≈ ∑ a π ( a ∣ s ; θ ) ⋅ q ( s , a ; w ) V_\pi=\sum_a\pi(a|s)·Q_\pi(s,a)\approx\sum_a\pi(a|s;\theta)·q(s,a;w) Vπ=a∑π(a∣s)⋅Qπ(s,a)≈a∑π(a∣s;θ)⋅q(s,a;w) -
Policy Network (Actor): π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ)

-
Value Network (Critic): q ( s , a ; w ) q(s,a;w) q(s,a;w)

-
Actor-Critic Method
2.Train the Neural Network
V ( s ; θ , w ) = ∑ a π ( a ∣ s ; θ ) ⋅ q ( s , a ; w ) V(s;\theta,w)=\sum_a\pi(a|s;\theta)·q(s,a;w) V(s;θ,w)=a∑π(a∣s;θ)⋅q(s,a;w)
-
模型训练:更新参数 θ , w \theta,w θ,w
-
更新 π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ)以提升 V ( s ; θ , w ) V(s;\theta,w) V(s;θ,w)
-
更新 q ( s , a ; w ) q(s,a;w) q(s,a;w)以使其打分更加精确
-
-
算法步骤:
-
观测得到状态 s t s_t st
-
以概率 π ( ⋅ ∣ s t ; θ t ) \pi(·|s_t;\theta_t) π(⋅∣st;θt)随机采样得到动作 a t a_t at
-
通过动作 a t a_t at,得到新的状态 s t + 1 s_{t+1} st+1和回报reward r t r_t rt
-
通过TD-Learning更新参数 w w w
-
通过Policy Gradient更新参数 θ \theta θ
-
-
Update value network q q q using TD
- compute q ( s t , a t ; w t ) q(s_t,a_t;w_t) q(st,at;wt) and q ( s t + 1 , a t + 1 ; w t ) q(s_{t+1},a_{t+1};w_t) q(st+1,at+1;wt)
- TD target: y t = r t + γ ⋅ q ( s t + 1 , a t + 1 ; w t ) y_t=r_t+\gamma·q(s_{t+1},a_{t+1};w_t) yt=rt+γ⋅q(st+1,at+1;wt)
- Loss: L ( w ) = 1 2 [ q ( s t , a t ; w t ) − y t ] 2 L(w)=\frac{1}{2}[q(s_t,a_t;w_t)-y_t]^2 L(w)=21[q(st,at;wt)−yt]2
- Gradient descent: w t + 1 = w t − α ⋅ ∂ L ( w ) ∂ w ∣ w = w t w_{t+1}=w_t-\alpha ·\frac{\partial L(w)}{\partial w}|_{w=w_t} wt+1=wt−α⋅∂w∂L(w)∣w=wt
-
Update policy network π \pi π using policy gradient
- Let g ( a , θ ) = ∂ log π ( a ∣ s ; θ ) ∂ θ ⋅ q ( s t , a ; w ) g(a,\theta)=\frac{\partial \log \pi(a|s;\theta)}{\partial \theta}·q(s_t,a;w) g(a,θ)=∂θ∂logπ(a∣s;θ)⋅q(st,a;w)
- ∂ V ( s ; θ , w t ) ∂ θ = E A [ g ( A , θ ) ] \frac{\partial V(s;\theta,w_t)}{\partial \theta}=E_A[g(A,\theta)] ∂θ∂V(s;θ,wt)=EA[g(A,θ)]
- 以概率 π ( ⋅ ∣ s t ; θ t ) \pi(·|s_t;\theta_t) π(⋅∣st;θt)随机抽样得到动作 a a a,计算 g ( a , θ ) g(a,\theta) g(a,θ)作为 ∂ V ( s ; θ , w t ) ∂ θ \frac{\partial V(s;\theta,w_t)}{\partial \theta} ∂θ∂V(s;θ,wt)的无偏估计(unbiased)
- Stochastic gradient ascent: θ t + 1 = θ t + β ⋅ g ( a , θ t ) \theta_{t+1}=\theta_t+\beta·g(a,\theta_t) θt+1=θt+β⋅g(a,θt)
3.算法步骤总结
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DIbeLTxH-1672473251173)(null)]](https://img-blog.csdnimg.cn/91d02dc56c0940c2a243e83115cc30ef.png)
在第9步中,使用 q t q_t qt进行计算为标准算法,如将 q t q_t qt替换为第5步得到的 δ t \delta_t δt,则为Policy Gradient with Baseline方法。二者对期望没有影响,但是使用好的Baseline可以降低方差,使方差收敛更快。
Baseline:任何接近 q t q_t qt的数都可以作为Baseline,但是不可以为动作 a t a_t at的函数。如果使用第5步的 δ t \delta_t δt,则Baseline为 r t + γ ⋅ q t + 1 r_t+\gamma·q_{t+1} rt+γ⋅qt+1
作 a t a_t at的函数。如果使用第5步的 δ t \delta_t δt,则Baseline为 r t + γ ⋅ q t + 1 r_t+\gamma·q_{t+1} rt+γ⋅qt+1
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









