







一、进程概述 --- 百度百科
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
二、线程概述 --- 百度百科
线程,有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元。一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组成。另外,线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。由于线程之间的相互制约,致使线程在运行中呈现出间断性。线程也有就绪、阻塞和运行三种基本状态。就绪状态是指线程具备运行的所有条件,逻辑上可以运行,在等待处理机;运行状态是指线程占有处理机正在运行;阻塞状态是指线程在等待一个事件(如某个信号量),逻辑上不可执行。每一个程序都至少有一个线程,若程序只有一个线程,那就是程序本身。
线程是程序中一个单一的顺序控制流程。进程内有一个相对独立的、可调度的执行单元,是系统独立调度和分派CPU的基本单位指令运行时的程序的调度单位。在单个程序中同时运行多个线程完成不同的工作,称为多线程。
三、进程与线程的区别
(1)进程是资源的分配和调度的一个独立单元,而线程是CPU调度的基本单元
(2)同一个进程中可以包括多个线程,并且线程共享整个进程的资源(寄存器、堆栈、上下文),一个进程至少包括一个线程。
(3)进程的创建调用fork或者vfork,而线程的创建调用pthread_create,进程结束后它拥有的所有线程都将销毁,而线程的结束不会影响同个进程中的其他线程的结束
(4)线程是轻两级的进程,它的创建和销毁所需要的时间比进程小很多,所有操作系统中的执行功能都是创建线程去完成的
(5)线程中执行时一般都要进行同步和互斥,因为他们共享同一进程的所有资源
(6)线程有自己的私有属性TCB,线程id,寄存器、硬件上下文,而进程也有自己的私有属性进程控制块PCB,这些私有属性是不被共享的,用来标示一个进程或一个线程的标志
进程的几种状态:
(1)run(运行状态):正在运行的进程或在等待队列中对待的进程,等待的进程只要以得到cpu就可以运行(2)Sleep(可中断休眠状态):相当于阻塞或在等待的状态
(3)D(不可中断休眠状态):在磁盘上的进程
(4)T(停止状态):这中状态无法直观的看见,因为是进程停止后就释放了资源,所以不会留在linux中
(5)Z(僵尸状态):子进程先与父进程结束,但父进程没有调用wait或waitpid来回收子进程的资源,所以子进程就成了僵尸进程,如果父进程结束后任然没有回收子进程的资源,那么1号进程将回收
四、Python3进程的创建方式
4.1、fork()
Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
子进程永远返回0,而父进程返回子进程的ID。这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getpid()就可以拿到父进程的ID。
Python的os模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
import os rpid = os.fork() if rpid<0: print("fork调用失败。") elif rpid == 0: print("我是子进程(%s),我的父进程是(%s)"%(os.getpid(),os.getppid())) x+=1 else: print("我是父进程(%s),我的子进程是(%s)"%(os.getpid(),rpid)) print("父子进程都可以执行这里的代码")
注:
(1)由于Windows没有fork调用,上面的代码在Windows上无法运行。
(2)有了fork调用,一个进程在接到新任务时就可以复制出一个子进程来处理新任务,常见的Apache服务器就是由父进程监听端口,每当有新的http请求时,就fork出子进程来处理新的http请求。
多次调用fork()的问题,代码如下:
import os import time # 注意,fork函数,只在Unix/Linux/Mac上运行,windows不可以 pid = os.fork() if pid == 0: print('fork1子进程') else: print('fork1父进程') pid = os.fork() if pid == 0: print('fork2子进程') else: print('fork2父进程') time.sleep(1)
输出如下:
fork1父进程 fork2子进程 fork2父进程 fork1子进程 fork2父进程 fork2子进程
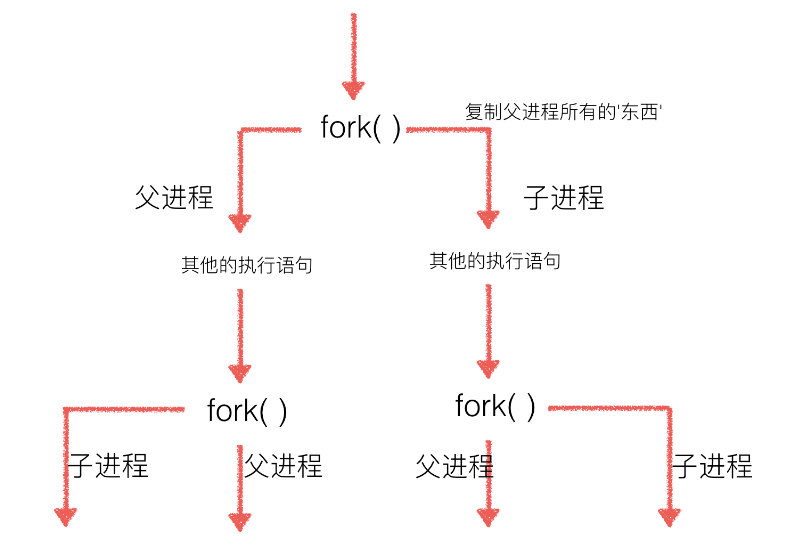
从上输出可以看出第二次通过fork()创建进程时,生产了4个进程,这是由于在第二次fork()时,是基于第一次的fork()创建出来的父进程、子进程再次独立创建父进程、子进程,如图:
4.2、multiprocessing
multiprocessing是一个使用类似于threading模块的API来支持多进程。该multiprocessing软件包提供本地和远程并发,通过使用子进程来充分利用服务器上的多个处理器,它可以在Unix和Windows上运行。
multiprocessing模块提供了一个Process类来代表一个进程对象,示例如下:
from multiprocessing import Process def proce(pn): print('hello',pn) if __name__ == '__main__': for i in range(10): #启动10个进程 p1 = Process(target=proce,args=(i,),name=str(i)) #创建进程 p1.start() #启动进程 p1.join() #等待进程结束 print('exit project')
Process语法结构如下:
Process([group [, target [, name [, args [, kwargs]]]]])
- target:表示这个进程实例所调用对象;
- args:表示调用对象的位置参数元组;
- kwargs:表示调用对象的关键字参数字典;
- name:为当前进程实例的别名;
- group:大多数情况下用不到;
Process类常用方法:
- is_alive():判断进程实例是否还在执行;
- join([timeout]):是否等待进程实例执行结束,或等待多少秒;
- start():启动进程实例(创建子进程);
- run():如果没有给定target参数,对这个对象调用start()方法时,就将执行对象中的run()方法;
- terminate():不管任务是否完成,立即终止;
Process类常用属性:
- name:当前进程实例别名,默认为Process-N,N为从1开始递增的整数;
- pid:当前进程实例的PID值;
4.3、Pool --- 进程池
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来执行,请看下面的实例:
from multiprocessing import Pool import os,time,random def worker(msg): t_start = time.time() print("%s开始执行,进程号为%d"%(msg,os.getpid())) #random.random()随机生成0~1之间的浮点数 time.sleep(random.random()*2) t_stop = time.time() print(msg,"执行完毕,耗时%0.2f"%(t_stop-t_start)) po=Pool(3) #定义一个进程池,最大进程数3 for i in range(0,10): #Pool.apply_async(要调用的目标,(传递给目标的参数元祖,)) #每次循环将会用空闲出来的子进程去调用目标 po.apply_async(worker,(i,)) print("----start----") po.close() #关闭进程池,关闭后po不再接收新的请求 po.join() #等待po中所有子进程执行完成,必须放在close语句之后 print("-----end-----")
运行结果:
----start---- 0开始执行,进程号为21466 1开始执行,进程号为21468 2开始执行,进程号为21467 0 执行完毕,耗时1.01 3开始执行,进程号为21466 2 执行完毕,耗时1.24 4开始执行,进程号为21467 3 执行完毕,耗时0.56 5开始执行,进程号为21466 1 执行完毕,耗时1.68 6开始执行,进程号为21468 4 执行完毕,耗时0.67 7开始执行,进程号为21467 5 执行完毕,耗时0.83 8开始执行,进程号为21466 6 执行完毕,耗时0.75 9开始执行,进程号为21468 7 执行完毕,耗时1.03 8 执行完毕,耗时1.05 9 执行完毕,耗时1.69 -----end-----
multiprocessing.Pool常用函数解析:
- apply_async(func[, args[, kwds]]) :使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键字参数列表;
- apply(func[, args[, kwds]]):使用阻塞方式调用func
- close():关闭Pool,使其不再接受新的任务;
- terminate():不管任务是否完成,立即终止;
- join():主进程阻塞,等待子进程的退出, 必须在close或terminate之后使用;
apply堵塞式
from multiprocessing import Pool import os,time,random def worker(msg): t_start = time.time() print("%s开始执行,进程号为%d"%(msg,os.getpid())) #random.random()随机生成0~1之间的浮点数 time.sleep(random.random()*2) t_stop = time.time() print(msg,"执行完毕,耗时%0.2f"%(t_stop-t_start)) po=Pool(3) #定义一个进程池,最大进程数3 for i in range(0,10): po.apply(worker,(i,)) print("----start----") po.close() #关闭进程池,关闭后po不再接收新的请求 po.join() #等待po中所有子进程执行完成,必须放在close语句之后 print("-----end-----")
运行结果:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3006
3006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









