2 将收集的日志信息保存到HDFS上,每天的日志保存到以该天命名的目录下面,如2014-7-25号的日志,保存到/flume/events/14-07-25目录下面。
i2为timestamp,在header中添加了一个timestamp的key,然后我们修改了sink1.hdfs.path在后面加上了/%y-%m-%d这一串字符,这一串字符要求event的header中必须有timestamp这个key,这就是为什么我们需要添加一个timestamp拦截器的原因,如果不添加这个拦截器,无法使用这样的占位符,会报错。还有很多占位符,请参考官方文档。
概述
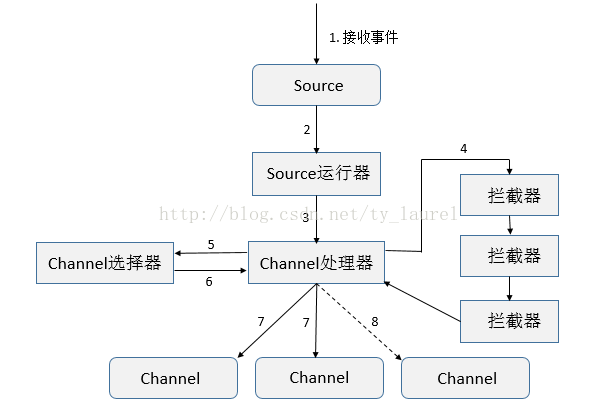
Flume 除了主要的三大组件 Source、Channel和 Sink,还有一些其他灵活的组件,如拦截器、SourceRunner运行器、Channel选择器和Sink处理器等。
组件框架图
今天主要来看看拦截器,先看下组件框架流程图,熟悉了大致框架流程学习起来必然会更加轻松:
- 接收事件
- 根据配置选择对应的Source运行器(EventDrivenSourceRunner 和 PollableSourceRunner)
- 处理器处理事件(Load-Balancing Sink 和 Failover Sink 处理器)
- 将事件传递给拦截器链
- 将每个事件传递给Channel选择器
- 返回写入事件的Channel列表
- 将所有事件写入每个必需的Channel,只有一个事务被打开
- 可选Channel(配置可选Channel后不管其是否写入成功)
拦截器
拦截器(Interceptor)是简单插件式组件,设置在Source和Channel之间,Source接收到event在写入到对应的Channel之前,可以通过调用的拦截器转换或者删除过滤掉一部分event。通过拦截器后返回的event数不能大于原本的数量。在一个Flume 事件流程中,可以添加任意数量的拦截器转换或者删除从单个Source中来的事件,Source将同一个事务的所有事件event传递给Channel处理器,进而依次可以传递给多个拦截器,直至从最后一个拦截器中返回的最终事件event写入到对应的Channel中。
flume-1.7版本支持的拦截器:
编写自定义拦截器
自定义的拦截器编写,我们只需要实现一个Interceptor接口即可,该接口的定义如下:
public interface Interceptor { /* 任何需要拦截器初始化或者启动的操作就可以定义在此,无则为空即可 */ public void initialize(); /* 每次只处理一个Event */ public Event intercept(Event event); /* 量处理Event */ public List<Event> intercept(List<Event> events); /*需要拦截器执行的任何closing/shutdown操作,一般为空 */ public void close(); /* 获取配置文件中的信息,必须要有一个无参的构造方法 */ public interface Builder extends Configurable { public Interceptor build(); }}
接口中的几个方法或者内部接口含义代码中已经标注,需要留意的地方就是考虑到多线程运行Source时,需要保证编写的代码是线程安全的。这里就不展示自定义拦截器代码了,仿照已有的拦截器,可以很容易的编写一个简单功能的自定义拦截器的。
实际使用及问题
问题:
目前环境中使用的都是tailSource、hdfsSink,在sink时根据时间对日志分割成不同的目录,但是实际过程中存在一些延迟,导致sink写入hdfs时的时间和日志文件中记录的时间存在一些差异;并且不能保留原有的日志文件名。
需求:
- 根据日志中记录的时间对文件进行分目录存储
- 将source端读取的日志名字符串添加至hdfsSink写入hdfs的文件名中(在hdfs文件中可以根据文件名区分日志)
日志格式如下:
2017/01/13 13:30:00 ip:123.178.46.252 message:[{"s":"bbceif1484117100097","u":"354910072847819","id":"2x1kfBk63z","e":2017/01/13 14:50:00 ip:123.178.46.252 message:[{"s":"bbceif1484117100097","u":"354910072847819","id":"2x1kfBk63z","e":2017/01/13 15:52:00 ip:123.178.46.252 message:[{"s":"bbceif1484117100097","u":"354910072847819","id":"2x1kfBk63z","e":2017/01/13 16:53:00 ip:123.178.46.252 message:[{"s":"bbceif1484117100097","u":"354910072847819","id":"2x1kfBk63z","e":2017/01/14 13:50:00 ip:123.178.46.252 message:[{"s":"bbceif1484117100097","u":"354910072847819","id":"2x1kfBk63z","e":2017/01/14 13:50:00 ip:123.178.46.252 message:[{"s":"bbceif1484117100097","u":"354910072847819","id":"2x1kfBk63z","e":2017/01/14 14:50:00 ip:123.178.46.252 message:[{"s":"bbceif1484117100097","u":"354910072847819","id":"2x1kfBk63z","e":2017/01/14 14:56:00 ip:123.178.46.252 message:[{"s":"bbceif1484117100097","u":"354910072847819","id":"2x1kfBk63z","e":
如何实现以上需求?
- 要了解TaildirSource如何读取日志文件,按行读取还是按数据量大小?
分析代码可知,无论单个事件操作还是批量操作均是按行读取 - hdfsSink如何对文件进行分目录?
若定义了hdfs.useLocalTimeStamp = true ,则是根据本地时间戳分目录,否则是从事件的header中获取时间戳。
明白了这两个问题,就可以继续往前走了。
实现需求1
Source端:
经过调研查阅资料发现,有拦截器就可以直接实现该目标功能。使用RegexExtractorInterceptor正则抽取拦截器,匹配日志中的时间字符串,将其添加至Event的header中(header的key值为timestamp),写入header时序列化只能使用org.apache.flume.interceptor.RegexExtractorInterceptorMillisSerializer(该序列化器内部根据配置传入的pattern将时间转换为时间戳格式):
agent1.sources.r1.interceptors = interagent1.sources.r1.interceptors.inter.type = regex_extractoragent1.sources.r1.interceptors.inter.regex = ^(\\d\\d\\d\\d/\\d\\d/\\d\\d\\s\\d\\d:\\d\\d:\\d\\d).*agent1.sources.r1.interceptors.inter.serializers = s1#agent1.sources.r1.interceptors.inter.serializers.s1.type = org.apache.flume.interceptor.RegexExtractorInterceptorPassThroughSerializer //该序列化内部只是将传入的匹配项直接返回returnagent1.sources.r1.interceptors.inter.serializers.s1.type = org.apache.flume.interceptor.RegexExtractorInterceptorMillisSerializeragent1.sources.r1.interceptors.inter.serializers.s1.name = timestampagent1.sources.r1.interceptors.inter.serializers.s1.pattern = yyyy/MM/dd HH:mm:ss
Sink端:
Sink端只需要注意不要设置hdfs.useLocalTimeStamp 为 true,也就是不使用本地时间,默认为false即可。
agent1.sinks.k1.type = hdfsagent1.sinks.k1.channel = c2agent1.sinks.k1.hdfs.path = /user/portal/tmp/syx/test2/%Y%m%d/%Y%m%d%Hagent1.sinks.k1.hdfs.filePrefix = events-%[localhost]-%{timestamp} //%[localhost] 获取主机名,%{timestamp} 获取事件header中key为timestamp的值value#agent1.sinks.k1.hdfs.useLocalTimeStamp = true //注意此处直接使用Event header中的timestamp,不适用本地时间戳agent1.sinks.k1.hdfs.callTimeout = 100000
实现需求2
tailDirSource端使用参数:
| fileHeader | false | Whether to add a header storing the absolute path filename. |
| fileHeaderKey | file | Header key to use when appending absolute path filename to event header. |
fileHeader 设置为 true ,可以将日志文件的绝对路径存储在事件的header中;
fileHeaderKey 目前来说不需要设置,它指定了存储在header中路径的key 名(header中是以key-value对存储),默认为 file。如下:
Event: { headers:{timestamp=1452581700000, file=/home/hadoop_portal/tiany/test.log} body: 32 30 31 36 2F 30 31 2F 31 32 20 31 34 3A 35 35 2016/01/12 14:55 }
因为hdfsSink可以直接从事件的header中读取字串作为hdfs文件名的一部分,可以通过将日志文件名添加至header中来实现。现在看起来实现上述需求就很简单了,只需要将绝对路径名修改为文件名就行了,这就可以修改tailDirSource中往 Event 中添加header时的代码了,如下:
//ReliableTaildirEventReader.java中的readEvents方法Map<String, String> headers = currentFile.getHeaders(); if (annotateFileName || (headers != null && !headers.isEmpty())) { for (Event event : events) { if (headers != null && !headers.isEmpty()) { event.getHeaders().putAll(headers); } if (annotateFileName) { //判断是否需要设置日志文件路径名至header中,为boolean类型 int lastIndex = currentFile.getPath().lastIndexOf('/'); //获取绝对路径中最后一次出现'/'的索引,根据索引获取路径中的文件名字串即可 event.getHeaders().put(fileNameHeader, currentFile.getPath().substring(lastIndex+1)); } } }
按以上方法操作,两个需求可以算就是完成了,flume测试跑了一天,很符合需求,以为这样任务就完成了吗? NO,隔了一晚上悲催的事就发生了,flume狂报错,日志显示无法从事件header中获取到时间戳timestamp,很纳闷,不是明明就将timestamp写入到header中了吗?
为了检测header中是否真的没有timestamp,将Sink修改为logger Sink(因为该方式可以将事件的header和body以日志形式打印出来,方便查看),修改之后测试跑了几个小时,接下来就是分析log,发现确实如报错,Source过来的日志有一些确实是没有时间字段的。
这种问题该如何解决呢?其实也是很简单的,研究RegexExtractorInterceptor拦截器的源代码,发现其中只是对匹配到指定格式时做了相应的处理,但是对于未匹配到的日志行时不做任何处理,因而修改源代码,在未匹配到指定字串时,添加默认的时间戳即可,但是不能为空,因为hdfsSink分目录时必须要从事件header中获取到timestamp的,否则就会报错,修改后代码如下:
public Event intercept(Event event) { Matcher matcher = regex.matcher( new String(event.getBody(), Charsets.UTF_8)); Map<String, String> headers = event.getHeaders(); if (matcher.find()) { //匹配到执行if语句中代码 for (int group = 0, count = matcher.groupCount(); group < count; group++) { int groupIndex = group + 1; if (groupIndex > serializers.size()) { if (logger.isDebugEnabled()) { logger.debug("Skipping group {} to {} due to missing serializer", group, count); } break; } NameAndSerializer serializer = serializers.get(group); if (logger.isDebugEnabled()) { logger.debug("Serializing {} using {}", serializer.headerName, serializer.serializer); } headers.put(serializer.headerName, serializer.serializer.serialize(matcher.group(groupIndex))); } //日志中没匹配到指定时间格式,添加当前时间为时间戳 } else { long now = System.currentTimeMillis(); headers.put("timestamp", Long.toString(now)); } return event; }
maven重新打包,替换掉原先的flume-ng-core.jar包即可,重新运行问题解决。
注意:若使用了KafkaChannel,parseAsFlumeEvent 应该使用默认值true,因为在Sink时需要读取Event中的header内容。
总结
flume的拦截器还是很有用的,可以在写入Channel之前先对日志做一次清洗,根据实际的需求编写自定义拦截器或者使用已有的拦截器,可以很方便的完成一些需求。对于这次的问题,虽然解决了,但是还是感觉很尴尬(日志提供方给出的日志格式每条日志都有时间字段,怪他们?no),其实主要还是由于自己没有考虑全面,只需要几行代码的事。因此在今后的学习工作生活中,无论干神马事,都得方方面面考虑,对于开发人员来说特别是故障处理、应急处理,很重要的。
3.http://blog.csdn.net/xiao_jun_0820/article/details/38333171
还是针对学习八中的那个需求,我们现在换一种实现方式,采用拦截器来实现。
先回想一下,spooldir source可以将文件名作为header中的key:basename写入到event的header当中去。试想一下,如果有一个拦截器可以拦截这个event,然后抽取header中这个key的值,将其拆分成3段,每一段都放入到header中,这样就可以实现那个需求了。
遗憾的是,flume没有提供可以拦截header的拦截器。不过有一个抽取body内容的拦截器:RegexExtractorInterceptor,看起来也很强大,以下是一个官方文档的示例:
If the Flume event body contained 1:2:3.4foobar5 and the following configuration was used
a1.sources.r1.interceptors.i1.regex = (\\d):(\\d):(\\d)
a1.sources.r1.interceptors.i1.serializers = s1 s2 s3
a1.sources.r1.interceptors.i1.serializers.s1.name = one
a1.sources.r1.interceptors.i1.serializers.s2.name = two
a1.sources.r1.interceptors.i1.serializers.s3.name = three
The extracted event will contain the same body but the following headers will have been added one=>1, two=>2, three=>3
大概意思就是,通过这样的配置,event body中如果有1:2:3.4foobar5 这样的内容,这会通过正则的规则抽取具体部分的内容,然后设置到header当中去。
于是决定打这个拦截器的主义,觉得只要把代码稍微改改,从拦截body改为拦截header中的具体key,就OK了。翻开源码,哎呀,很工整,改起来没难度,以下是我新增的一个拦截器:RegexExtractorExtInterceptor:
- package com.besttone.flume;
-
- import java.util.List;
- import java.util.Map;
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
-
- import org.apache.commons.lang.StringUtils;
- import org.apache.flume.Context;
- import org.apache.flume.Event;
- import org.apache.flume.interceptor.Interceptor;
- import org.apache.flume.interceptor.RegexExtractorInterceptorPassThroughSerializer;
- import org.apache.flume.interceptor.RegexExtractorInterceptorSerializer;
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
-
- import com.google.common.base.Charsets;
- import com.google.common.base.Preconditions;
- import com.google.common.base.Throwables;
- import com.google.common.collect.Lists;
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- public class RegexExtractorExtInterceptor implements Interceptor {
-
- static final String REGEX = "regex";
- static final String SERIALIZERS = "serializers";
-
-
-
- static final String EXTRACTOR_HEADER = "extractorHeader";
- static final boolean DEFAULT_EXTRACTOR_HEADER = false;
- static final String EXTRACTOR_HEADER_KEY = "extractorHeaderKey";
-
-
-
- private static final Logger logger = LoggerFactory
- .getLogger(RegexExtractorExtInterceptor.class);
-
- private final Pattern regex;
- private final List<NameAndSerializer> serializers;
-
-
-
- private final boolean extractorHeader;
- private final String extractorHeaderKey;
-
-
-
- private RegexExtractorExtInterceptor(Pattern regex,
- List<NameAndSerializer> serializers, boolean extractorHeader,
- String extractorHeaderKey) {
- this.regex = regex;
- this.serializers = serializers;
- this.extractorHeader = extractorHeader;
- this.extractorHeaderKey = extractorHeaderKey;
- }
-
- @Override
- public void initialize() {
-
- }
-
- @Override
- public void close() {
-
- }
-
- @Override
- public Event intercept(Event event) {
- String tmpStr;
- if(extractorHeader)
- {
- tmpStr = event.getHeaders().get(extractorHeaderKey);
- }
- else
- {
- tmpStr=new String(event.getBody(),
- Charsets.UTF_8);
- }
-
- Matcher matcher = regex.matcher(tmpStr);
- Map<String, String> headers = event.getHeaders();
- if (matcher.find()) {
- for (int group = 0, count = matcher.groupCount(); group < count; group++) {
- int groupIndex = group + 1;
- if (groupIndex > serializers.size()) {
- if (logger.isDebugEnabled()) {
- logger.debug(
- "Skipping group {} to {} due to missing serializer",
- group, count);
- }
- break;
- }
- NameAndSerializer serializer = serializers.get(group);
- if (logger.isDebugEnabled()) {
- logger.debug("Serializing {} using {}",
- serializer.headerName, serializer.serializer);
- }
- headers.put(serializer.headerName, serializer.serializer
- .serialize(matcher.group(groupIndex)));
- }
- }
- return event;
- }
-
- @Override
- public List<Event> intercept(List<Event> events) {
- List<Event> intercepted = Lists.newArrayListWithCapacity(events.size());
- for (Event event : events) {
- Event interceptedEvent = intercept(event);
- if (interceptedEvent != null) {
- intercepted.add(interceptedEvent);
- }
- }
- return intercepted;
- }
-
- public static class Builder implements Interceptor.Builder {
-
- private Pattern regex;
- private List<NameAndSerializer> serializerList;
-
-
-
- private boolean extractorHeader;
- private String extractorHeaderKey;
-
-
-
- private final RegexExtractorInterceptorSerializer defaultSerializer = new RegexExtractorInterceptorPassThroughSerializer();
-
- @Override
- public void configure(Context context) {
- String regexString = context.getString(REGEX);
- Preconditions.checkArgument(!StringUtils.isEmpty(regexString),
- "Must supply a valid regex string");
-
- regex = Pattern.compile(regexString);
- regex.pattern();
- regex.matcher("").groupCount();
- configureSerializers(context);
-
-
- extractorHeader = context.getBoolean(EXTRACTOR_HEADER,
- DEFAULT_EXTRACTOR_HEADER);
-
- if (extractorHeader) {
- extractorHeaderKey = context.getString(EXTRACTOR_HEADER_KEY);
- Preconditions.checkArgument(
- !StringUtils.isEmpty(extractorHeaderKey),
- "必须指定要抽取内容的header key");
- }
-
- }
-
- private void configureSerializers(Context context) {
- String serializerListStr = context.getString(SERIALIZERS);
- Preconditions.checkArgument(
- !StringUtils.isEmpty(serializerListStr),
- "Must supply at least one name and serializer");
-
- String[] serializerNames = serializerListStr.split("\\s+");
-
- Context serializerContexts = new Context(
- context.getSubProperties(SERIALIZERS + "."));
-
- serializerList = Lists
- .newArrayListWithCapacity(serializerNames.length);
- for (String serializerName : serializerNames) {
- Context serializerContext = new Context(
- serializerContexts.getSubProperties(serializerName
- + "."));
- String type = serializerContext.getString("type", "DEFAULT");
- String name = serializerContext.getString("name");
- Preconditions.checkArgument(!StringUtils.isEmpty(name),
- "Supplied name cannot be empty.");
-
- if ("DEFAULT".equals(type)) {
- serializerList.add(new NameAndSerializer(name,
- defaultSerializer));
- } else {
- serializerList.add(new NameAndSerializer(name,
- getCustomSerializer(type, serializerContext)));
- }
- }
- }
-
- private RegexExtractorInterceptorSerializer getCustomSerializer(
- String clazzName, Context context) {
- try {
- RegexExtractorInterceptorSerializer serializer = (RegexExtractorInterceptorSerializer) Class
- .forName(clazzName).newInstance();
- serializer.configure(context);
- return serializer;
- } catch (Exception e) {
- logger.error("Could not instantiate event serializer.", e);
- Throwables.propagate(e);
- }
- return defaultSerializer;
- }
-
- @Override
- public Interceptor build() {
- Preconditions.checkArgument(regex != null,
- "Regex pattern was misconfigured");
- Preconditions.checkArgument(serializerList.size() > 0,
- "Must supply a valid group match id list");
- return new RegexExtractorExtInterceptor(regex, serializerList,
- extractorHeader, extractorHeaderKey);
- }
- }
-
- static class NameAndSerializer {
- private final String headerName;
- private final RegexExtractorInterceptorSerializer serializer;
-
- public NameAndSerializer(String headerName,
- RegexExtractorInterceptorSerializer serializer) {
- this.headerName = headerName;
- this.serializer = serializer;
- }
- }
- }
简单说明一下改动的内容:
增加了两个配置参数:
extractorHeader 是否抽取的是header部分,默认为false,即和原始的拦截器功能一致,抽取的是event body的内容
extractorHeaderKey 抽取的header的指定的key的内容,当extractorHeader为true时,必须指定该参数。
按照第八讲的方法,我们将该类打成jar包,作为flume的插件放到了/var/lib/flume-ng/plugins.d/RegexExtractorExtInterceptor/lib目录下,重新启动flume,将该拦截器加载到classpath中。
最终的flume.conf如下:
- tier1.sources=source1
- tier1.channels=channel1
- tier1.sinks=sink1
- tier1.sources.source1.type=spooldir
- tier1.sources.source1.spoolDir=/opt/logs
- tier1.sources.source1.fileHeader=true
- tier1.sources.source1.basenameHeader=true
- tier1.sources.source1.interceptors=i1
- tier1.sources.source1.interceptors.i1.type=com.besttone.flume.RegexExtractorExtInterceptor$Builder
- tier1.sources.source1.interceptors.i1.regex=(.*)\\.(.*)\\.(.*)
- tier1.sources.source1.interceptors.i1.extractorHeader=true
- tier1.sources.source1.interceptors.i1.extractorHeaderKey=basename
- tier1.sources.source1.interceptors.i1.serializers=s1 s2 s3
- tier1.sources.source1.interceptors.i1.serializers.s1.name=one
- tier1.sources.source1.interceptors.i1.serializers.s2.name=two
- tier1.sources.source1.interceptors.i1.serializers.s3.name=three
- tier1.sources.source1.channels=channel1
- tier1.sinks.sink1.type=hdfs
- tier1.sinks.sink1.channel=channel1
- tier1.sinks.sink1.hdfs.path=hdfs://master68:8020/flume/events/%{one}/%{three}
- tier1.sinks.sink1.hdfs.round=true
- tier1.sinks.sink1.hdfs.roundValue=10
- tier1.sinks.sink1.hdfs.roundUnit=minute
- tier1.sinks.sink1.hdfs.fileType=DataStream
- tier1.sinks.sink1.hdfs.writeFormat=Text
- tier1.sinks.sink1.hdfs.rollInterval=0
- tier1.sinks.sink1.hdfs.rollSize=10240
- tier1.sinks.sink1.hdfs.rollCount=0
- tier1.sinks.sink1.hdfs.idleTimeout=60
- tier1.channels.channel1.type=memory
- tier1.channels.channel1.capacity=10000
- tier1.channels.channel1.transactionCapacity=1000
- tier1.channels.channel1.keep-alive=30
我把source type改回了内置的spooldir,而不是上一讲自定义的source,然后添加了一个拦截器i1,type是自定义的拦截器:com.besttone.flume.RegexExtractorExtInterceptor$Builder,正则表达式按“.”分隔抽取三部分,分别放到header中的key:one,two,three当中去,即a.log.2014-07-31,通过拦截器后,在header当中就会增加三个key: one=a,two=log,three=2014-07-31。这时候我们在tier1.sinks.sink1.hdfs.path=hdfs://master68:8020/flume/events/%{one}/%{three}。
就实现了和前面第八讲一模一样的需求。
也可以看到,自定义拦截器的改动成本非常小,比自定义source小多了,我们这就增加了一个类,就实现了该功能。
4.http://lxw1234.com/archives/2015/11/547.htm
我们目前的业务场景如下:前端的5台日志收集服务器产生网站日志,使用Flume实时收集日志,并将日志发送至Kafka,然后Kafka中的日志一方面可以导入到HDFS,另一方面供实时计算模块使用。
前面的文章《Kafka分区机制介绍与示例》介绍过Kafka的分区机制。我们对Kafka中存储日志的Topic指定了多个分区,默认情况下,Kafka Sink在收到events之后,将会随机选择一个该Topic的分区来存储数据,但我们不想这么做,我们需要根据网站日志中的cookieid来决定events存储到哪个分区中,简单来说,就是对cookieid计算hashcode,取绝对值,然后和Topic的分区数做模运算,这样,即实现了多分区的负载均衡,又确保相同的cookieid会写入同一个分区中,这样的处理,对后续的实时计算模块大有好处(后续再介绍)。
而这样的需求,利用Flume的拦截器即可实现。前面有两篇文章
《Flume中的拦截器(Interceptor)介绍与使用(一)》和
《Flume中的拦截器(Interceptor)介绍与使用(二)》
介绍了Flume的拦截器和使用示例,这里我们使用的拦截器是Regex Extractor Interceptor。
即从原始events中抽取出cookieid,放入到header中,而Kafka Sink在写入Kafka的时候,会从header中获取指定的key,然后根据分区规则确定该条events写入哪个分区中。
网站日志格式
假设原始网站日志有三个字段,分别为 时间|cookieid|ip,中间以单竖线分隔,比如:
- 2015-10-30 16:00:00| 967837DE00026C55D8DB2E|127.0.0.1
- 2015-10-30 16:05:00| 967837DE00026C55D8DB2E|127.0.0.1
- 2015-10-30 17:10:00| AC19BBDC0002A955A4A48F|127.0.0.1
- 2015-10-30 17:15:00| AC19BBDC0002A955A4A48F|127.0.0.1
Flume Source的配置
- agent_lxw1234.sources = sources1
- agent_lxw1234.channels = fileChannel
- agent_lxw1234.sinks = sink1
- ##source 配置
- agent_lxw1234.sources.sources1.type = com.lxw1234.flume17.TaildirSource
- agent_lxw1234.sources.sources1.positionFile = /tmp/flume/agent_lxw1234_position.json
- agent_lxw1234.sources.sources1.filegroups = f1
- agent_lxw1234.sources.sources1.filegroups.f1 = /tmp/lxw1234_.*.log
- agent_lxw1234.sources.sources1.batchSize = 100
- agent_lxw1234.sources.sources1.backoffSleepIncrement = 1000
- agent_lxw1234.sources.sources1.maxBackoffSleep = 5000
- agent_lxw1234.sources.sources1.channels = fileChannel
-
该source用于监控/tmp/lxw1234_.*.log命名格式的文件。
Flume Source拦截器配置
- ## source 拦截器
- agent_lxw1234.sources.sources1.interceptors = i1
- agent_lxw1234.sources.sources1.interceptors.i1.type = regex_extractor
- agent_lxw1234.sources.sources1.interceptors.i1.regex = .*?\\|(.*?)\\|.*
- agent_lxw1234.sources.sources1.interceptors.i1.serializers = s1
- agent_lxw1234.sources.sources1.interceptors.i1.serializers.s1.name = key
该拦截器(Regex Extractor Interceptor)用于从原始日志中抽取cookieid,访问到events header中,header名字为key。
Flume Kafka Sink配置
- # sink 1 配置
- agent_lxw1234.sinks.sink1.type = org.apache.flume.sink.kafka.KafkaSink
- agent_lxw1234.sinks.sink1.brokerList = developnode1:9091,developnode1:9092,developnode2:9091,developnode2:9092
- agent_lxw1234.sinks.sink1.topic = lxw1234
- agent_lxw1234.sinks.sink1.channel = fileChannel
- agent_lxw1234.sinks.sink1.batch-size = 100
- agent_lxw1234.sinks.sink1.requiredAcks = -1
- agent_lxw1234.sinks.sink1.kafka.partitioner.class = com.lxw1234.flume17.SimplePartitioner
该Sink配置为Kafka Sink,将接收到的events发送至kafka集群的topic:lxw1234中。
其中topic:lxw1234创建时候指定了4个分区,Kafka Sink使用的分区规则为
com.lxw1234.flume17.SimplePartitioner,它会读取events header中的key值(即cookieid),然后对cookieid应用于分区规则,以便确定该条events发送至哪个分区中。
关于com.lxw1234.flume17.SimplePartitioner的介绍和代码,见:
《Kafka分区机制介绍与示例》。
Kafka消费者
使用下面的Java程序从Kafka中消费数据,打印出每条events所在的分区。
并从events中抽取cookieid,然后根据com.lxw1234.flume17.SimplePartitioner中的分区规则(Math.abs(cookieid.hashCode()) % 4)测试分区,看是否和获取到的分区一致。
- package com.lxw1234.kafka;
-
- import java.util.HashMap;
- import java.util.List;
- import java.util.Map;
- import java.util.Properties;
-
- import kafka.consumer.Consumer;
- import kafka.consumer.ConsumerConfig;
- import kafka.consumer.ConsumerIterator;
- import kafka.consumer.KafkaStream;
- import kafka.javaapi.consumer.ConsumerConnector;
- import kafka.message.MessageAndMetadata;
-
- public class MyConsumer {
- public static void main(String[] args) {
- String topic = "lxw1234";
- ConsumerConnector consumer = Consumer.createJavaConsumerConnector(createConsumerConfig());
- Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
- topicCountMap.put(topic, new Integer(1));
- Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
- KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
- ConsumerIterator<byte[], byte[]> it = stream.iterator();
- while(it.hasNext()) {
- MessageAndMetadata<byte[], byte[]> mam = it.next();
- String msg = new String(mam.message());
- String cookieid = msg.split("\\|")[1];
- int testPartition = Math.abs(cookieid.hashCode()) % 4;
- System.out.println("consume: Partition [" + mam.partition() + "] testPartition [" + testPartition + "] Message: [" + new String(mam.message()) + "] ..");
- }
-
- }
-
- private static ConsumerConfig createConsumerConfig() {
- Properties props = new Properties();
- props.put("group.id","group_lxw_test");
- props.put("zookeeper.connect","127.0.0.133:2182");
- props.put("zookeeper.session.timeout.ms", "4000");
- props.put("zookeeper.sync.time.ms", "200");
- props.put("auto.commit.interval.ms", "1000");
- props.put("auto.offset.reset", "smallest");
- return new ConsumerConfig(props);
- }
- }
运行结果

如图中红框所示,实际events所在的分区和期望分区(testPartition)的结果完全一致,由此可见,所有的events已经按照既定的规则写入Kafka分区中。
相关阅读:
Flume中的拦截器(interceptor),用户Source读取events发送到Sink的时候,在events header中加入一些有用的信息,或者对events的内容进行过滤,完成初步的数据清洗。这在实际业务场景中非常有用,Flume-ng 1.6中目前提供了以下拦截器:
Timestamp Interceptor;
Host Interceptor;
Static Interceptor;
UUID Interceptor;
Morphline Interceptor;
Search and Replace Interceptor;
Regex Filtering Interceptor;
Regex Extractor Interceptor;
本文对常用的几种拦截器进行学习和介绍,并附上使用示例。
本文中使用的Source为TaildirSource,就是监控一个文件的变化,将内容发送给Sink,具体可参考《Flume中的TaildirSource》,Source配置如下:
- #-->设置sources名称
- agent_lxw1234.sources = sources1
- #--> 设置channel名称
- agent_lxw1234.channels = fileChannel
- #--> 设置sink 名称
- agent_lxw1234.sinks = sink1
-
- # source 配置
- agent_lxw1234.sources.sources1.type = com.lxw1234.flume17.TaildirSource
- agent_lxw1234.sources.sources1.positionFile = /tmp/flume/agent_lxw1234_position.json
- agent_lxw1234.sources.sources1.filegroups = f1
- agent_lxw1234.sources.sources1.filegroups.f1 = /tmp/lxw1234_.*.log
- agent_lxw1234.sources.sources1.batchSize = 100
- agent_lxw1234.sources.sources1.backoffSleepIncrement = 1000
- agent_lxw1234.sources.sources1.maxBackoffSleep = 5000
- agent_lxw1234.sources.sources1.channels = fileChannel
Flume Source中使用拦截器的相关配置如下:
- ## source 拦截器
- agent_lxw1234.sources.sources1.interceptors = i1 i2
- agent_lxw1234.sources.sources1.interceptors.i1.type = host
- agent_lxw1234.sources.sources1.interceptors.i1.useIP = false
- agent_lxw1234.sources.sources1.interceptors.i1.hostHeader = agentHost
- agent_lxw1234.sources.sources1.interceptors.i2.type = timestamp
-
对一个Source可以使用多个拦截器。
Timestamp Interceptor
时间戳拦截器,将当前时间戳(毫秒)加入到events header中,key名字为:timestamp,值为当前时间戳。用的不是很多。比如在使用HDFS Sink时候,根据events的时间戳生成结果文件,hdfs.path = hdfs://cdh5/tmp/dap/%Y%m%d
hdfs.filePrefix = log_%Y%m%d_%H
会根据时间戳将数据写入相应的文件中。
但可以用其他方式代替(设置useLocalTimeStamp = true)。
Host Interceptor
主机名拦截器。将运行Flume agent的主机名或者IP地址加入到events header中,key名字为:host(也可自定义)。
根据上面的Source,拦截器的配置如下:
- ## source 拦截器
- agent_lxw1234.sources.sources1.interceptors = i1
- agent_lxw1234.sources.sources1.interceptors.i1.type = host
- agent_lxw1234.sources.sources1.interceptors.i1.useIP = false
- agent_lxw1234.sources.sources1.interceptors.i1.hostHeader = agentHost
-
- # sink 1 配置
- agent_lxw1234.sinks.sink1.type = hdfs
- agent_lxw1234.sinks.sink1.hdfs.path = hdfs://cdh5/tmp/lxw1234/%Y%m%d
- agent_lxw1234.sinks.sink1.hdfs.filePrefix = lxw1234_%{agentHost}
- agent_lxw1234.sinks.sink1.hdfs.fileSuffix = .log
- agent_lxw1234.sinks.sink1.hdfs.fileType = DataStream
- agent_lxw1234.sinks.sink1.hdfs.useLocalTimeStamp = true
- agent_lxw1234.sinks.sink1.hdfs.writeFormat = Text
- agent_lxw1234.sinks.sink1.hdfs.rollCount = 0
- agent_lxw1234.sinks.sink1.hdfs.rollSize = 0
- agent_lxw1234.sinks.sink1.hdfs.rollInterval = 600
- agent_lxw1234.sinks.sink1.hdfs.batchSize = 500
- agent_lxw1234.sinks.sink1.hdfs.threadsPoolSize = 10
- agent_lxw1234.sinks.sink1.hdfs.idleTimeout = 0
- agent_lxw1234.sinks.sink1.hdfs.minBlockReplicas = 1
- agent_lxw1234.sinks.sink1.channel = fileChannel
-
该配置用于将source的events保存到HDFS上hdfs://cdh5/tmp/lxw1234的目录下,文件名为lxw1234_<主机名>.log
Static Interceptor
静态拦截器,用于在events header中加入一组静态的key和value。
根据上面的Source,拦截器的配置如下:
- ## source 拦截器
- agent_lxw1234.sources.sources1.interceptors = i1
- agent_lxw1234.sources.sources1.interceptors.i1.type = static
- agent_lxw1234.sources.sources1.interceptors.i1.preserveExisting = true
- agent_lxw1234.sources.sources1.interceptors.i1.key = static_key
- agent_lxw1234.sources.sources1.interceptors.i1.value = static_value
-
- # sink 1 配置
- agent_lxw1234.sinks.sink1.type = hdfs
- agent_lxw1234.sinks.sink1.hdfs.path = hdfs://cdh5/tmp/lxw1234
- agent_lxw1234.sinks.sink1.hdfs.filePrefix = lxw1234_%{static_key}
- agent_lxw1234.sinks.sink1.hdfs.fileSuffix = .log
- agent_lxw1234.sinks.sink1.hdfs.fileType = DataStream
- agent_lxw1234.sinks.sink1.hdfs.useLocalTimeStamp = true
- agent_lxw1234.sinks.sink1.hdfs.writeFormat = Text
- agent_lxw1234.sinks.sink1.hdfs.rollCount = 0
- agent_lxw1234.sinks.sink1.hdfs.rollSize = 0
- agent_lxw1234.sinks.sink1.hdfs.rollInterval = 600
- agent_lxw1234.sinks.sink1.hdfs.batchSize = 500
- agent_lxw1234.sinks.sink1.hdfs.threadsPoolSize = 10
- agent_lxw1234.sinks.sink1.hdfs.idleTimeout = 0
- agent_lxw1234.sinks.sink1.hdfs.minBlockReplicas = 1
- agent_lxw1234.sinks.sink1.channel = fileChannel
看看最终Sink在HDFS上生成的文件结构:

UUID Interceptor
UUID拦截器,用于在每个events header中生成一个UUID字符串,例如:b5755073-77a9-43c1-8fad-b7a586fc1b97。生成的UUID可以在sink中读取并使用。根据上面的source,拦截器的配置如下:
- ## source 拦截器
- agent_lxw1234.sources.sources1.interceptors = i1
- agent_lxw1234.sources.sources1.interceptors.i1.type = org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder
- agent_lxw1234.sources.sources1.interceptors.i1.headerName = uuid
- agent_lxw1234.sources.sources1.interceptors.i1.preserveExisting = true
- agent_lxw1234.sources.sources1.interceptors.i1.prefix = UUID_
-
- # sink 1 配置
- agent_lxw1234.sinks.sink1.type = logger
- agent_lxw1234.sinks.sink1.channel = fileChannel
运行后在日志中查看header信息:

Morphline Interceptor
Morphline拦截器,该拦截器使用Morphline对每个events数据做相应的转换。关于Morphline的使用,可参考
http://kitesdk.org/docs/current/morphlines/morphlines-reference-guide.html
后续再研究这块。
Flume中的拦截器(interceptor),用户Source读取events发送到Sink的时候,在events header中加入一些有用的信息,或者对events的内容进行过滤,完成初步的数据清洗。这在实际业务场景中非常有用,Flume-ng 1.6中目前提供了以下拦截器:
Timestamp Interceptor;
Host Interceptor;
Static Interceptor;
UUID Interceptor;
Morphline Interceptor;
Search and Replace Interceptor;
Regex Filtering Interceptor;
Regex Extractor Interceptor;
本文接上一篇《Flume中的拦截器(Interceptor)介绍与使用(一)》,继续对剩下几种拦截器进行学习和介绍,并附上使用示例。
Search and Replace Interceptor
该拦截器用于将events中的正则匹配到的内容做相应的替换。
具体配置示例如下:
- ## source 拦截器
- agent_lxw1234.sources.sources1.interceptors = i1
- agent_lxw1234.sources.sources1.interceptors.i1.type = search_replace
- agent_lxw1234.sources.sources1.interceptors.i1.searchPattern = [0-9]+
- agent_lxw1234.sources.sources1.interceptors.i1.replaceString = lxw1234
- agent_lxw1234.sources.sources1.interceptors.i1.charset = UTF-8
-
- # sink 1 配置
- ##agent_lxw1234.sinks.sink1.type = com.lxw1234.sink.MySink
- agent_lxw1234.sinks.sink1.type = logger
- agent_lxw1234.sinks.sink1.channel = fileChannel
-
该配置将events中的数字替换为lxw1234。
原始的events内容为:

实际的events内容为:

Regex Filtering Interceptor
该拦截器使用正则表达式过滤原始events中的内容。
配置示例如下:
- ## source 拦截器
- agent_lxw1234.sources.sources1.interceptors = i1
- agent_lxw1234.sources.sources1.interceptors.i1.type = regex_filter
- agent_lxw1234.sources.sources1.interceptors.i1.regex = ^lxw1234.*
- agent_lxw1234.sources.sources1.interceptors.i1.excludeEvents = false
-
- # sink 1 配置
- ##agent_lxw1234.sinks.sink1.type = com.lxw1234.sink.MySink
- agent_lxw1234.sinks.sink1.type = logger
- agent_lxw1234.sinks.sink1.channel = fileChannel
-
该配置表示过滤掉不是以lxw1234开头的events。
如果excludeEvents设为true,则表示过滤掉以lxw1234开头的events。
原始events内容为:

拦截后的events内容为:

Regex Extractor Interceptor
该拦截器使用正则表达式抽取原始events中的内容,并将该内容加入events header中。
配置示例如下:
- ## source 拦截器
- agent_lxw1234.sources.sources1.interceptors = i1
- agent_lxw1234.sources.sources1.interceptors.i1.type = regex_extractor
- agent_lxw1234.sources.sources1.interceptors.i1.regex = cookieid is (.*?) and ip is (.*?)
- agent_lxw1234.sources.sources1.interceptors.i1.serializers = s1 s2
- agent_lxw1234.sources.sources1.interceptors.i1.serializers.s1.type = default
- agent_lxw1234.sources.sources1.interceptors.i1.serializers.s1.name = cookieid
- agent_lxw1234.sources.sources1.interceptors.i1.serializers.s2.type = default
- agent_lxw1234.sources.sources1.interceptors.i1.serializers.s2.name = ip
-
- # sink 1 配置
- ##agent_lxw1234.sinks.sink1.type = com.lxw1234.sink.MySink
- agent_lxw1234.sinks.sink1.type = logger
- agent_lxw1234.sinks.sink1.channel = fileChannel
-
该配置从原始events中抽取出cookieid和ip,加入到events header中。
原始的events内容为:

events header中的内容为:

Flume的拦截器可以配合Sink完成许多业务场景需要的功能,
比如:按照时间及主机生成目标文件目录及文件名;
配合Kafka Sink完成多分区的写入等等。
关键字:Flume、TaildirSource、TailFile、Source
在通过Flume收集日志的业务场景中,一般都会遇到下面的情况,在日志收集服务器的某个目录下,会按照一段时间生成一个日志文件,并且日志会不断的追加到这个文件中,比如,每小时一个命名规则为log_20151015_10.log的日志文件,所有10点产生的日志都会追加到这个文件中,到了11点,就会生成另一个log_20151015_11.log的文件。
这种场景如果通过flume(1.6)收集,当前提供的Spooling Directory Source和Exec Source均不能满足动态实时收集的需求,在当前正在开发的flume1.7版本中,提供了一个非常好用的TaildirSource,使用这个source,可以监控一个目录,并且使用正则表达式匹配该目录中的文件名进行实时收集。
我将TaildirSource的相关源码下载下来(需要做简单修改),然后集成到Flume1.6中,满足了上面提到的需求,获得了良好的效果。
源码下载地址: 点击下载
将源码单独编译,打成jar包,上传到$FLUME_HOME/lib/目录下。
下面的例子中,通过flume监控/tmp/lxw1234-flume/目录下,命名规则为log_.*.log的文件,并将文件内容实时的写入/tmp/flumefiles/目录下,即:source为TaildirSource,sink为file_roll;
Agent配置
agent_lxw1234的配置文件如下($FLUME_HOME/conf/agent_lxw1234_conf.properties):
- #-->设置sources名称
- agent_lxw1234.sources = sources1
- #--> 设置channel名称
- agent_lxw1234.channels = fileChannel
- #--> 设置sink 名称
- agent_lxw1234.sinks = sink1
-
- # source 配置
- agent_lxw1234.sources.sources1.type = com.lxw1234.flume17.TaildirSource
- agent_lxw1234.sources.sources1.positionFile = /tmp/flume/taildir_position.json
- agent_lxw1234.sources.sources1.filegroups = f1
- agent_lxw1234.sources.sources1.filegroups.f1 = /tmp/lxw1234-flume/log_.*.log
- agent_lxw1234.sources.sources1.batchSize = 100
- agent_lxw1234.sources.sources1.backoffSleepIncrement = 1000
- agent_lxw1234.sources.sources1.maxBackoffSleep = 5000
- agent_lxw1234.sources.sources1.channels = fileChannel
-
- # sink1 配置
- agent_lxw1234.sinks.sink1.type = file_roll
- agent_lxw1234.sinks.sink1.sink.directory = /tmp/flumefiles
- agent_lxw1234.sinks.sink1.sink.rollInterval = 0
- agent_lxw1234.sinks.sink1.channel = fileChannel
-
- # fileChannel 配置
- agent_lxw1234.channels.fileChannel.type = file
- #-->检测点文件所存储的目录
- agent_lxw1234.channels.fileChannel.checkpointDir = /opt/flume/checkpoint/lxw1234/
- #-->数据存储所在的目录设置
- agent_lxw1234.channels.fileChannel.dataDirs = /opt/flume/data/lxw1234/
- #-->隧道的最大容量
- agent_lxw1234.channels.fileChannel.capacity = 10000
- #-->事务容量的最大值设置
- agent_lxw1234.channels.fileChannel.transactionCapacity = 200
-
TaildirSource的配置说明(带*的为必须配置)
**channels**
**type**
**filegroups** 指定filegroups,可以有多个,以空格分隔;(TailSource可以同时监控tail多个目录中的文件)
**filegroups.<filegroupName>** 配置每个filegroup的文件绝对路径,文件名可以用正则表达式匹配
positionFile 配置检查点文件的路径,检查点文件会以json格式保存已经tail文件的位置
启动Agent
cd $FLUME_HOME/conf/
flume-ng agent -n agent_lxw1234 –conf . -f agent_lxw1234_conf.properties
运行结果
启动之后,在sink所指的/tmp/flumefiles目录下,生成了一个大小为0的目标文件,命令为时间戳-1,如:

接着往监控的目录中生成log_20151015_10.log的文件:

此时,在上面tail –f目标文件的控制台中,已经可以看到写入的内容了:

再模拟生成一个新的文件(log_20151015_11.log):

同样,目标文件中也正常写入:

如果在监控的目录/tmp/lxw1234-flume/中,产生和所配置的文件名正则表达式不匹配的文件,则不会被tail。
另外,如果将所监控目录/tmp/lxw1234-flume/中已经过期的文件移除,也不会影响agent的运行。
检查点文件positionFile
看一下该文件的内容:
该文件中记录了所监控的每个文件的当前位置,如图中红圈圈出的pos的值,因为两个文件都已经读到了最后,因此每个pos的值就是该文件的大小。
TailSource使用了RandomAccessFile来根据positionFile中保存的文件位置来读取文件的,在agent重启之后,亦会先从positionFile中找到上次读取的文件位置,保证内容不会重复发送。























 3350
3350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









