







Linux内核综述
内核是什么?它的任务是什么呢?对这些问题的回答有很多,简单的概括一下吧,内核是位于上层应用与硬件之间的一个软件中间层,能为上层应用提供服务(例如提供的系统调用),并且对其进行管理(例如何时分配给进程CPU、内存等资源),同时能够驱动硬件完成功能动作。
如今对内核的实现有2种基本的理念,一种是微内核(microkernel)、另外一种则是一体化内核(Monolithic kernel):
- Microkernels:微内核仅实现了最基本的必要的内核功能(比如:内存管理、任务、线程、进程间通信等),其余的所有服务(包括设备驱动)在用户模式下运行,而处理这些服务同处理其他的任何一个程序一样。因为每个服务只是在自己的地址空间运行。所以这些服务之间彼此之间都受到了保护。另外的技术优势还包括:可扩展性好等等,劣势在于会带来额外的通信时间。

- Monolithic kernels:内核的所有的子系统都被打包进一个单一文件。Linux就属于这样的内核,但Linux实现了Modules,可以实现Modules的动态插入与删除
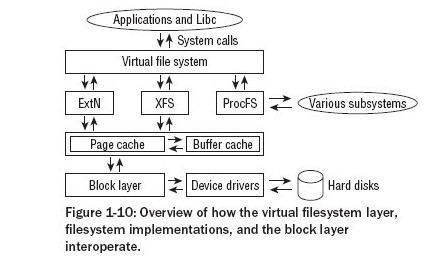
下图是Linux系统的一个基本视图:
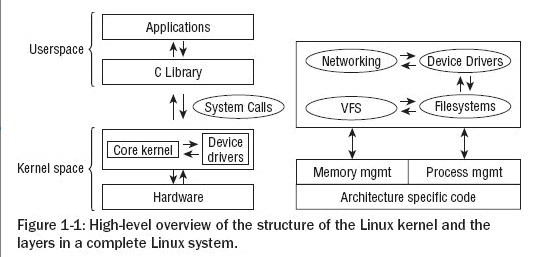
- 进程(process)、任务切换(Task switch)和任务调度(Task Schedule):每个进程都在自己运行的CPU的虚拟内存中分配有地址空间,互相之间是隔离的,通信需要调用内核服务。
- 任务切换:内核在CPU硬件的帮助之下,完成任务状态的保护及恢复
- 任务调度:内核必须决定何时调度那个进程并分配给它多长的运行时间
- Unix Processes:
- Linux实现了一个分级体系:进程必须来源于一个parent进程,init进程可以说是系统中其他所有进程的祖先进程,用pstree打印出的显示比较类似的显示了这个过程,为实现这个分级体系,Linux使用了fork和exec。
- fork:执行对parent进程的一个几乎完全的拷贝(PID不同),采用Copy on Write技术在parent或child进程写操作时才区分parent和child的内容。
- exec:在原空间中加载一新的程序并执行,old content被覆盖。
- 线程(Threads):在Linux中也存在两种叫法,进程(a heavy process)和线程(a light thread),一个进程中可以包含多个线程,这些线程共享进程空间的数据和资源,但是代码执行路径不同,可以并行执行。Linux使用clone方法来产生线程,该方法类似fork,但是clone方法却要严格区分与父进程共享的资源和线程独享的资源。
- 命名空间(Namespace):利用命名空间,可以让不同的processes拥有不同的系统视图,例如,传统Linux使用大量全局实体,如PID,利用命令空间,一些全局量可以划分组,每个组拥有一个PID集合或者每个组提供不同的文件系统视图,卷不能同时挂载到不同视图。当然,并不是内核的所有组成都使用了命名空间。
- Linux实现了一个分级体系:进程必须来源于一个parent进程,init进程可以说是系统中其他所有进程的祖先进程,用pstree打印出的显示比较类似的显示了这个过程,为实现这个分级体系,Linux使用了fork和exec。
- 地址空间(Address Space)和优先级(Privilege level):
- 系统CPU的位数决定了可以管理的地址空间位数,这里得到的地址空间是指虚拟地址空间(virtual address space),虚拟地址空间被划分为内核地址空间(TASK_SIZE之上部分)和用户地址空间(0~TASK_SIZE)两部分。TASK_SIZE是一个与架构相关的值,例如IA-32架构,其值为3GiB,运行在用户空间的各个进程认为自己独享该空间,而内核地址空间则为各用户空间进程所”共享”但不能访问,64位架构则更加复杂。
- 优先级:CPU硬件定义了执行的不同优先级,但Linux只使用2个:内核模式和用户模式,用户模式下运行的进程不能访问内核地址空间。
- 系统调用:发生系统调用时,为完成任务,进程依然运行在本进程上下文,可访问用户空间
- 中断:进程运行在中断上下文,不可访问用户空间、不能睡眠
- 内核线程:一般也不访问用户空间,但可以睡眠,也可被调度,可用ps查看,名字类似[kthreadd],带[]即是。
- 虚拟地址空间和物理地址空间:转换使用页表。但是大多数情况下,虚拟地址空间的大多数区域没有使用,也没有映射到物理内存。
- 页表(Page Tables):
如上文所述,由于大多数情况下虚拟地址空间的大多数区域没有使用,也没用映射到物理内存,因为为节省页表所占用空间,使用分级 页表,如下图所示:
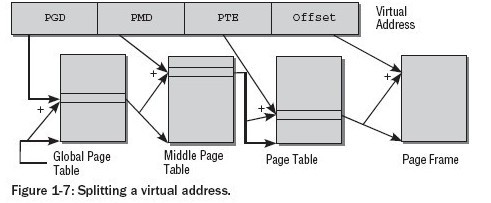
几个术语:
PGD:Page Global Directory
PMD:Page Middle Directory
PTE: Page Table Entry
这种方式节约了内存空间,但是每次访问内存就需要顺着这个链走一遍,为加速,CPU采用了MMU(Memory Management Unit) 技术和TLB(Translation Lookaside Buffer)技术(Cache缓存转换地址),注意缓存内容的更新。
-
- CPU架构不同,页表级数不同(IA-32的2级页表,64位架构的3或4级页表),但是架构无关代码却采用的是四级页表。
- 内存映射(Memory Mapping):内存映射是指任意来源的数据映射进进程的虚拟地址空间,可以用处理通常内存的方法处理发生内存映射的地址空间,任意的改变都会自动改变源数据。如读写文件时,来自硬盘的文件映射进内存,内核自动把改变写回该文件。
- 物理内存分配
内核只能分配整个页框,对内存的更小划分交给了库,库将内核返回的页框划分成更小的部分,然后分配给进程。
-
- The Buddy System
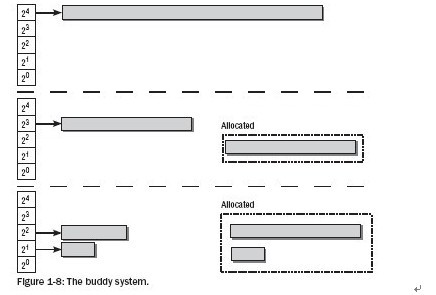
所有大小(1,2,4,8,16…)的buddies都在内核的一个特定表中。当分配内存时,大的buddy分裂成小的buddies,小 的buddies也可以合成大的buddy以提供所需的内存。内存的频繁分配也会带来内存碎片问题
-
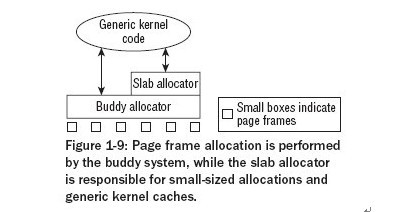
- The Slab Cache
内核也经常需要小于page frame的块,但由于内核不能使用标准库提供的功能,所以它需要定义自己的、附加的内存管理层 次,这个层次建立在buddy系统之上并对buddy系统提供的页框进行分割。它建立了一个对small objects使用的通用池, 即slab cache:
-
-
- 对常用对象,内核建立自己的cache,仅存放特定类型的对象,池中对象按需移出及返还。slab cache自动与buddy系统交互,索要所需页框。
- 对普通的small memory blocks的分配,内核建立了一系列不同对象大小的池,可使用同一函数访问,即kmalloc和kfree。
-
标准workload,slab分配器可以很好工作,但是对于大型机或嵌入式系统并不行,linux针对这些用例提供了不同 的allocator,但仍向其他模块提供相同的接口
-
- Swapping and Page reclaim:
Swapping通过利用硬盘可以虚拟的扩大可用内存,不常用的内存页被swap out到硬盘上,并在页表中使用特殊标记的项标 记,应用需要使用时则内核产生page fault将该页swap in 内存。
Page reclaim(页回收):需要将数据写回到磁盘,然后回收页框使用。
- Timing
内核必须能够衡量时间及各时间点的不同,通常使用时钟中断来计时,每秒钟的滴答数就是jiffies,用全局变量jiffies_64或其32位 的jiffies来表示,依赖于硬件架构,jiffies按HZ增加,一般是每秒增加1000~100,这个值是很粗粒度的,如今的高性能的timer,依 赖硬件,内核提供了额外的附加方法来提供更高的精度。这个周期性的tick应该是动态的,当没有什么任务时,它对周期性的时钟中断 可不反应。
- 系统调用
系统调用由内核实现,执行系统调用时,处理器必须从用户模式进入内核模式,系统调用的实现随CPU架构甚至CPU不同而不同,一 般IA-32是利用软中断方式,但系统调用是用户自主从用户模式进入内核模式的唯一方法
- 设备驱动
方便用户程序利用/dev/下的设备文件驱动设备,大致分成字符设备(顺序读写、禁止随机读写、按字节/字符读写)和块设备(随机读 写、块读写,禁止按字节读写)
- 网络
网卡依然由驱动控制,但/dev/没有网络设备文件。linux利用socket接口
- 文件系统
利用VFS支持多种文件系统。
- 模块和热插拔
模块支持内核运行时动态加载和卸载。Modules仅在内核空间执行,与静态编译进内核的模块拥有同等的权限。
- Caching
分为page cache和buffer cache,页cache用于加速对磁盘等慢速设备的访问,而buffer cache很久前多用于system cache,但 如今多被page cache代替
- List处理
在<list.h>中存在:
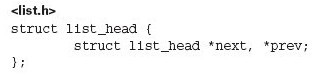
其他结构体要使用它时,可以包含它:

双向循环链表的头也是list_head类型,并且常用LIST_HEAD(list_name)宏初始化。
- 对象管理和引用计数
- 通用内核对象Generic Kernel objects:
如下数据结构可作为basis内嵌到其他数据结构中:

内嵌:

k_name: 是通过sysfs返回给用户空间的对象名
kref : 用于引用管理
entry : 把kobject联成一个链表
parent :用于kobjects之间组成分层架构
kset : 指向该kobject所在的kset
ktype : 提供kobject嵌入的对象的更详细的信息

原子性的引用计数,当其值为0时,该对象就可以从内存中删除了。

-
- 有时需要将kobjects组合成一个集合,这就需要:

ktype :指向引发the behaviors of kset的远程对象
list :指向组合成该set的kobject对象链表
uevent_ops:指向操作集合,用于将该set的信息传递到用户空间
kset只是管理自身的特性,对所包含的kobjects不做任何操作。

kobj_type提供了与sysfs的接口。
-
- 引用计数

原子性使得即使在多核处理器中也可以,相应的辅助函数有kret_init()、kret_get()、kret_put()
- 数据类型
- 类型定义
内核使用typedef来定义各种新的类型,以独立于架构,这种定义是放在架构相关代码中的,有时内核也需要精确bit位数的 类型。
-
- 字节序
根据系统架构的不同,存储多字节数据使用big-endian或little-endian来存储多位数据,区别如下:
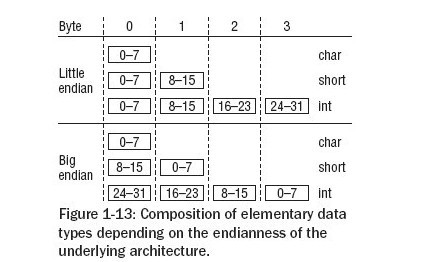
内核提供了大量的函数/宏来在CPU使用的格式和存储在内存中的格式之间的转换
-
- Per-CPU Variables
使用DEFINE_PER_CPU(name,type)来为系统中每个CPU创建一个该类型变量对象,使用时需要使 用get_cpu(name,cpu)来获取指定cpu上的该变量,smp_processor_id()来返回当前active的cpu
-
- 访问用户空间
一些代码中有用__user标记的指针,用于标记这些指向用户空间区域的指针
应用程序错误一般会导致段错误或者core dump,但是内核错误会导致系统宕机,所有的内核代码都必须保护,以防止并 发,但由于对多核的支持,内核代码必须是可重入的和线程安全的,即程序可以并行执行,但数据必须防止并行访问。内核必 须在大小端机器上都能运行。从2.6.23内核开始,IA-32和AMD64都统一到x86目录下了,但仍区分。















 933
933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









