







一,概述
- Elasticsearch是一个基于Lucene开发的一个分布式、可扩展、实时的搜索与数据分析引擎。
- Cluster:集群。
- Node:节点,一个节点就是Elasticsearch的一个实例。
- Shard:分片(主分片),es数据存储的最小单元,创建索引的时候指定,不可更改,路由算法:shard = hash(routing) % number_of_primary_shards。Routing默认是文档id。
- Replica:副本,一个副本就是一个主分片的拷贝,可以动态扩展,提高容灾能力,分担主分片查询压力。
- Index:Elasticsearch的Index相当于数据库的Table。
- Type:这个在新的7.X版本已经废除。
- Document:Document相当于数据库的一行记录。
- Field:相当于数据库的Column的概念。
- Mapping:索引的数据结构,定义索引里字段的名称,类型,是否分词等。相当于数据库的Schema的概念,描述数据库的组织和结构。
二,数据类型
- 常见类型: keyword,text,boolean,integer,long,double,date
- 复杂类型: object(JSON对象)、join(嵌套类型)
- 特殊类型: geo_point(经纬度"location": { "lat": 41.12, "lon": -71.34})
- keyword:
- 1,作为整体不被分词,直接建立索引
- 2,支持模糊查询(使用wildcard query 类似mysql的like *小*)和精准匹配
- 3,这个类型的字段通常用于排序,聚合,
- text:
- 1,会进行分词,分词后建立索引(对分词建立索引而不是整个文本)
- 2,支持模糊,支持精准匹配
- 3,不支持聚合查询。
三,分词器
- standard: ES的默认分词器,会去除符号,并将大写转换为小写,然后根据空格进行分词。
- simple: 按照非字母切分(符号被过滤),小写处理,会去除数字
- whitespace:分词器只根据空格进行分词,保留符号
- stop:与standard相似,只是会过滤掉the,a,is等修饰词
- keyword: 不分词,将内容当成一个整体
- ik_smart: 最粗粒度的分词
- Ik_max_word: 最细粒度的分词
四,Node节点类型
- Master Node:主节点的主要职责是负责集群层面的相关操作,创建或删除索引,创建Mapping,或者增加、删除节点。单一职责Master节点只需要较低配置CPU、较低配置内存和磁盘。
- Data Node:数据节点,主要是存储数据的节点。需要存储数据并计算结果,所以需要高速大容量磁盘、高CPU、高RAM内存。
- Ingest Node:数据预处理的节点,对索引请求进行预处理,比如doc写入文件前执行一条ingest pipeline(一个预处理管道),比如改变某个field的值,添加一两个field等 ,还支持painless脚本对数据进行复杂加工(类似于Java中的过滤器)。每个节点默认都是Ingest Node
- Coordinating Node:协调节点, 接收到客户端请求之后将创建(删除)索引的请求转发给Master节点,查询数据的请求转发给Data节点,对Data节点返回的数据进行缩减合并返回用户。需要高CPU和中等大小内存。
- ES的默认值:node.master=true,node.data=true, node.ingest=true。如果三项都设置为false,那这个节点将只作为协调节点使用。
五,分片 Shard
- 一个索引的数据可以分为多个主分片,每个主分片又可以设置多个副本分片冗余数据。
- 主分片(primary shard)和副本分片(replica shard)
- 一个索引的主分片数量是在创建索引的时候固定的,不可变更,副本分片是可以动态修改的。主分片故障时副本分片会选出主分片,由此做到冗余数据,容灾。
- 主副分片都会处理查询请求,协调节点会随机选取主副分片其中一个发送请求。新增修改删除请求只能主分片处理,然后通过主从同步到副本分片。
- 同一个索引的primary shard、replica shard不能分配到同一个节点上。主要目的是防止节点挂掉导致备份不可用,
- 写操作时由协调节点发给主分片primary shard,主分片需要将所有操作发送给副本分片执行,全部执行完之后主分片返回给协调节点结果响应给客户端。
六,节点分片示意图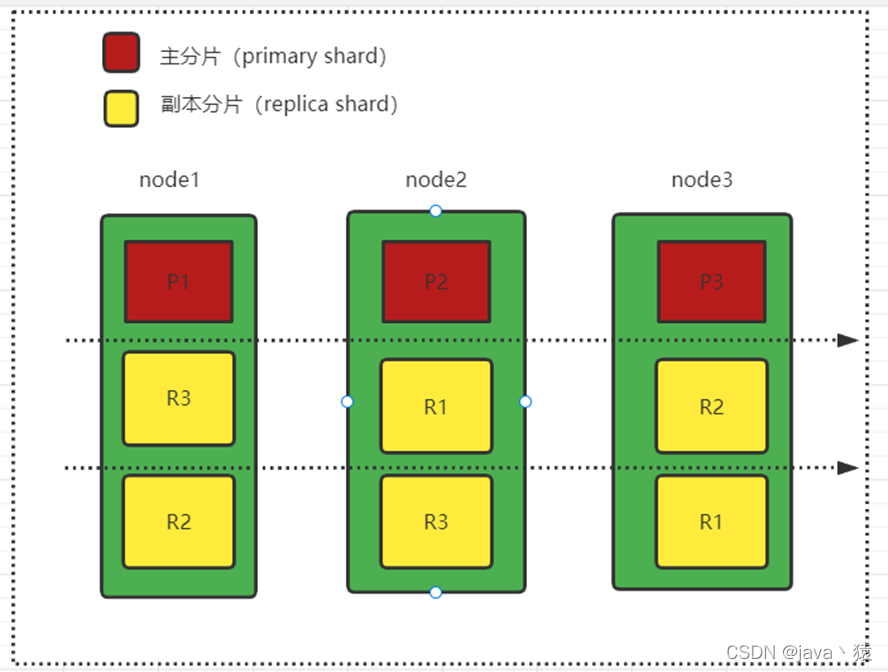
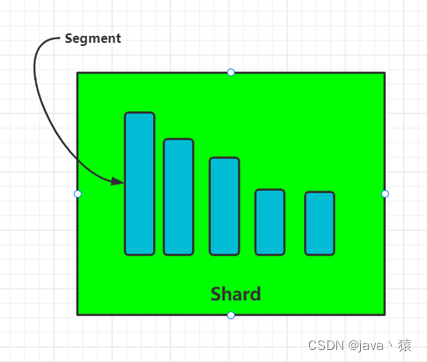
七,分段 Segment
- Elasticsearch 中的一个 Shard 是一个 Lucene 索引,一个 Lucene 索引被分解成段。段是存储索引数据的索引中的内部存储元素。
- segment是不可变的,物理上你并不能从中删除信息,所以在删除文档的时候,是在文档上面打上一个删除的标记,然后在执行段合并的时候,进行删除
- 索引segment段的个数越多,搜索性能越低且消耗内存更多
八,基于Segment数据读写,更新过程
- 新增:当有新的数据需要创建索引时,由于段不变性,所以选择新建一个段来存储新增的数据。
- 删除:当需要删除数据时,由于数据所在的段只可读,不可写,所以Lucene在索引文件新增一个.del的文件,用来专门存储被删除的数据id。当查询时,被删除的数据还是可以被查到的,只是在进行文档链表合并时,才把已经删除的数据过滤掉。被删除的数据在进行段合并时才会被真正被移除。索引segment段的个数越多,搜索性能越低且消耗内存更多
- 更新:更新的操作其实就是删除和新增的组合,先在.del文件中记录旧数据,再在新段中添加一条更新后的数据。
九,倒排索引数据结构
- Term(单词):一段文本经过分析器分析以后就会输出一串单词,这一个一个的就叫做Term(直译为:单词)
- Term Dictionary(单词字典):可以理解为Term的集合,ES为了快速找到term,会将所有term排序,然后二分查找。
- Term Index(单词索引):为了更快的找到某个单词,我们为单词建立索引,结构类似“Trie 树”(前缀树/字典树)
- Posting List(倒排列表):倒排列表存储的是单词对应的文档id,还可以保存单词在某个文档中出现的次数,单词在文档中出现的位置
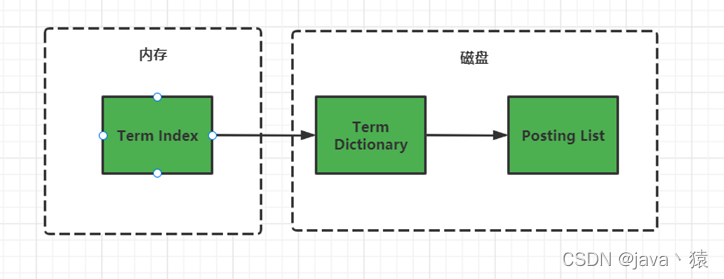
十,倒排索引
- 单词的倒排索引如下图
- 文档频率:该单词在多少文档中出现过
- DocId:单词出现的文档ID
- TF:表示单词在该文档中出现次数
- <POS>:表示单词出现的位置信息

十一,整体结构示意图

十二,单词查找过程
通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找,确定term的在磁盘中的位置,找到单词对应的倒排项。
注:term index是通过FST (Finite State Transducer)的压缩技术进行压缩,保证term index可以被缓存到内存中,减少磁盘IO,提高效率。
FST有两个优点:1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;2)查询速度快。O(len(str))的查询时间复杂度。

十三,ES数据写入过程
- 客户端向 Node 1 发送新建、索引或者删除请求。
- 节点使用文档的 _id 确定文档属于分片 0 。请求会被转发到 Node 3,因为分片 0 的主分片目前被分配在 Node 3 上。
- Node 3 在主分片上面执行请求。如果成功了,它将请求并行转发到 Node 1 和 Node 2 的副本分片上。一旦所有的副本分片都报告成功, Node 3 将向协调节点报告成功,协调节点向客户端报告成功。

十四,ES数据读取数据过程-查询阶段
- 客户端发送查询请求到node3,node3此时作为协调节点。
- node3以广播请求的方式请求索引中每一个节点的分片(可以是主分片也可以是副本分片)
- 每个分片将构造一个本地优先队列。如果客户端要求返回的是from,size分页数据,则每个分片都会得到一个form+size大小的结果集,将轻量级的结果返回给协调节点,由node3进行合并排序。

十五,ES数据读取数据过程-取回阶段
- 协调节点node3,根据合并后的结果集,确定需要向那些分片发起请求。
- 向各个分片发起请求,获取到文档完整数据返回给协调节点。
- 协调节点返回给客户端
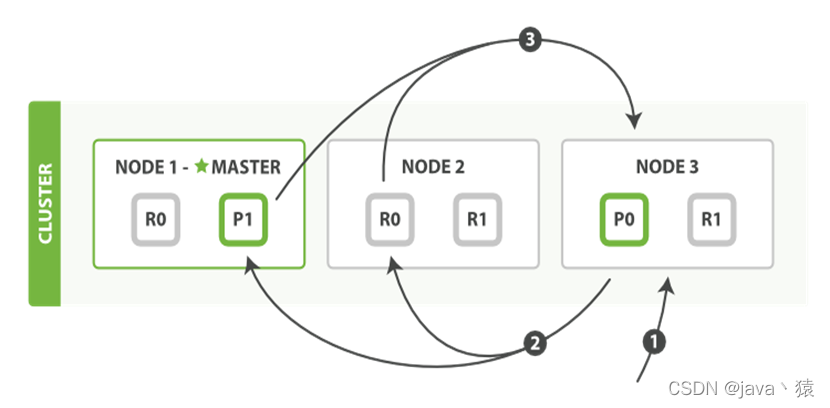
十六,ES数据存储过程
1,一个文档被索引之后,就会被添加到内存缓冲区,并且 追加到了 translog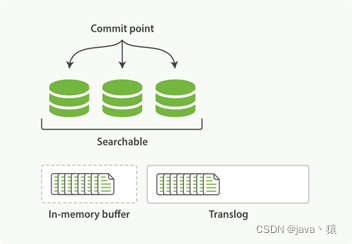
2,分片每秒执行一次refersh,这些在内存缓冲区的文档被写入到一个新的segment中,
segment被打开,文档可被索引到,同时清空内存buffer
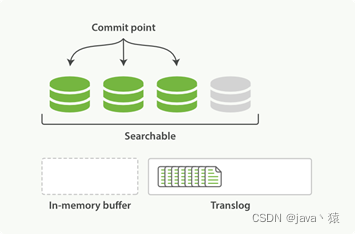
3,这个进程继续工作,更多的文档被添加到内存缓冲区和追加到translog
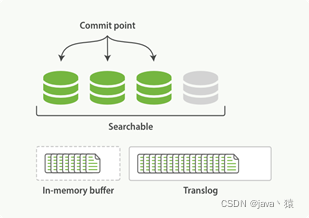
4,每间隔一段时间,或translog变得越来越大索引将被flush
1)内存缓冲区的数据被写入新的segment
2)缓冲区被清空
3)文件系统缓存被刷入磁盘(flush操作)
4)清空translog

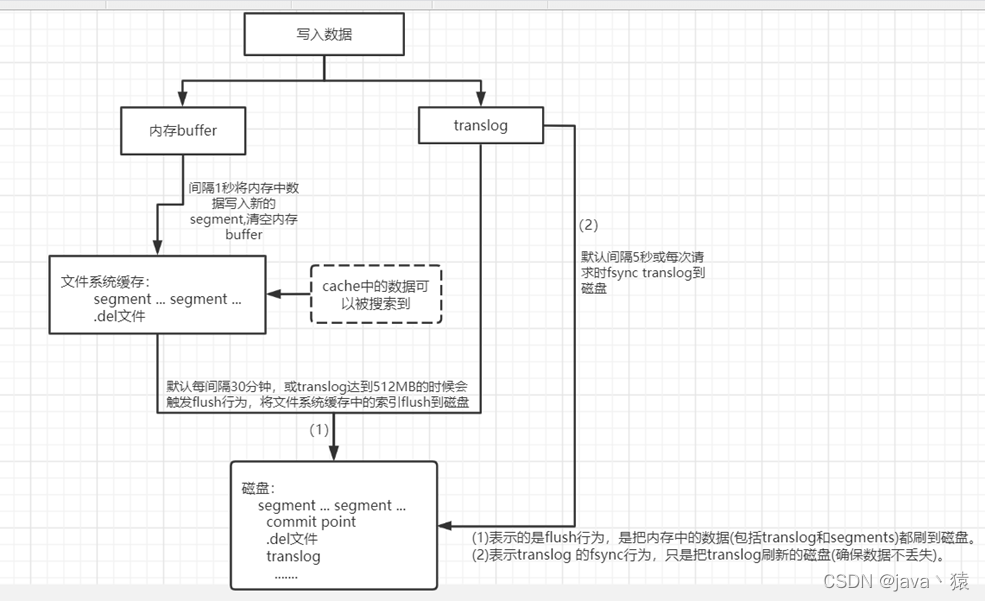
十七,ES数据存储原理
十八,基本语法
查看索引信息:GET /_cat/indices?v
查看集群节点信息:GET /_cat/nodes
删除索引:DELETE /my_index
创建索引: PUT /my_index?pretty
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
}
}设置索引信息:PUT /my_index/_mappings
keyword 类型 ignore_above 指的是长度超过指定字符后,不会被索引,但是会被存储
text 类型的 ignore_above 指超过长度不能被整体索引,不会精确匹配到
{
"properties": {
"content_type": {
"type": "integer"
},
"content_id": {
"type": "long"
},
"user_name": {
"type": "keyword",
"ignore_above": 5
},
"title": {
"type": "text",
"fields": {
"key": {
"type": "keyword",
"ignore_above": 15
}
},
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"desc": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"create_time": {
"type": "date"
}
}
}查看索引结构信息:GET /my_index
查看索引结构信息:GET /my_index/_mappings
删除文档:DELETE /my_index/_doc/1
创建文档:PUT /my_index/_doc/1001
{
"content_id": 1001,
"content_type": 1,
"user_name": "小明",
"create_time": "2020-11-01",
"title": "一则小明的花边新闻",
"desc": "小明昨天表白失败"
}
{
"content_id": 1002,
"content_type": 1,
"user_name": "小红",
"create_time": "2020-11-01",
"title": "小红花边新闻",
"desc": "小红昨天拒绝了小明的表白"
}
{
"content_id": 1003,
"content_type": 2,
"user_name": "小胡",
"create_time": "2020-11-02",
"title": "小红和小胡的感情纠葛",
"desc": "小红因为暗恋小胡拒绝了小明的追求"
}
{
"content_id": 1004,
"content_type": 2,
"user_name": "小红小明小胡",
"create_time": "2020-11-02",
"title": "小红小明小胡的生死三角恋导致的诸多问题引发社会关心",
"desc": "小红因为暗恋老王拒绝了小明的追求"
}term 对搜索词不做分词,会将输入作为一个整体,在倒排索引中查找准确的词项:GET /my_index/_search
{
"query": {
"term": {
"user_name": "小胡"
}
}
}
{
"query": {
"term": {
"title": "小红"
}
}
}match 用在一个分词字段上,他会分词去匹配。用在一个精确匹配的字段上或者数字、日期类型字段上他会精确查找:GET /my_index/_search
{
"query": {
"match": {
"user_name": "小红"
}
}
}
加上分页
{
"query": {
"match": {
"title": "小红和"
}
},
"from":0,
"size":"1"
}range 范围查询:GET /my_index/_search
{
"query": {
"range": {
"content_id": {
"gte":1002,
"lte":1004
}
}
}
}bool 多条件组合查询:GET /my_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "小胡"
}
},
{
"range": {
"content_id": {
"gte": 1002,
"lte": 1004
}
}
}
]
}
}
}














 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









