










前言
StarRocks 存算分离模式架构中,数据导入后,会被写入远端对象存储。而对象存储由于其访问延迟较高特性,如果没有任何优化,每次查询直接访问后端对象存储,那么性能就会变得非常差,也就失去了 StarRocks 的性能优势。一般而言,在存算分离架构下需要在计算节点上使用本地磁盘来缓存系统经常访问的热点数据,这样,当查询访问到这些数据时,直接访问本地磁盘中的缓存即可,可以提供与存算一体架构同等的查询性能。
StarRocks 存算分离架构从 3.0 版本推出时便支持基于本地磁盘的 Data Cache 机制,不过我们也在不断优化和迭代我们的 Cache 实现,效率和稳定性越来越高。本文章旨在梳理 StarRocks 存算分离形态下的 Cache 演变历史,帮助用户们对 Cache 有更深入的理解,以更好的使用 StarRocks 存算分离。
这里需要强调的是,我们这里所说的 Cache 指的是基于本地持久化存储介质(如磁盘)构建的数据缓存系统。基于内存的 Page Cache 不在本文讨论范围。关于内存数据缓存的 Page Cache,存算分离和存算一体有着同样实现。
Data Cache 初体验
CREATE TABLE IF NOT EXISTS detail_demo ( recruit_date DATE NOT NULL COMMENT "YYYY-MM-DD", region_num TINYINT COMMENT "range [-128, 127]", num_plate SMALLINT COMMENT "range [-32768, 32767] ", tel INT COMMENT "range [-2147483648, 2147483647]", id BIGINT COMMENT "range [-2^63 + 1 ~ 2^63 - 1]", password LARGEINT COMMENT "range [-2^127 + 1 ~ 2^127 - 1]", name CHAR(20) NOT NULL COMMENT "range char(m),m in (1-255) ", profile VARCHAR(500) NOT NULL COMMENT "upper limit value 65533 bytes", ispass BOOLEAN COMMENT "true/false") DUPLICATE KEY(recruit_date, region_num) DISTRIBUTED BY HASH(recruit_date, region_num) PROPERTIES ( "datacache.enable" = "true", "datacache.partition_duration" = "1 MONTH", );
上面是一个典型的 StarRocks 存算分离建表语句,该语句中有两个参数用来控制 Cache 行为:
- datacache.enable: 该参数控制是否启用本地磁盘缓存。默认值:true,数据会同时导入对象存储(或 HDFS)和本地磁盘(作为查询加速的缓存)。false:数据仅导入到对象存储中。
- datacache.partition_duration: 热数据的有效期。当启用本地磁盘缓存时,所有数据都会导入至本地磁盘缓存中。当缓存满时,StarRocks 会从缓存中删除最近较少使用的数据。当有查询需要扫描已删除的数据时,StarRocks 会从当前时间开始,检查该数据是否在有效期内。如果数据在有效期内,StarRocks 会再次将数据导入至缓存中。如果数据不在有效期内,Cache 加载后并不会将其加载至缓存中。该属性为字符串,您可以使用以下单位指定:YEAR、MONTH、DAY 和 HOUR,例如,7 DAY 和 12 HOUR。如果不指定,StarRocks 将所有数据都作为热数据进行缓存。
可以看到,StarRocks 存算分离可以精准控制每个表的 Cache 行为。当前,StarRocks 外表也可以开启 Cache,但这个不在本文范围,其使用方式也有所不一样。本文只讨论存算分离内表的 Cache 行为。
Cache V1: File Cache
StarRocks 存算分离版本在 V3.0.0 推出时,我们内部实现了最初版本的 Cache,我们也称之为 File Cache。这也是 Cache 的创世版本,也较为简单,按照数据文件为单位来操作 Cache,并辅以 LRU 来进行缓存淘汰。具体来说:
- 数据文件写入时,会同时写入对象存储和本地 Cache,只有当两者都写入成功,整个写入才会成功给用户返回
- 读取时,如果发现需要读取的内容在本地 Data Cache 未能命中,会启动后台线程将内容所在的数据文件整个从后端对象存储下载至本地磁盘缓存,需要注意的是,这里是启动后台线程下载(为了提高效率,会多线程并发下载),但并不会阻塞前面的读取请求
- 当本地磁盘使用空间达到一定阈值时(可配置),内部的淘汰线程会启动,进行 LRU 淘汰,直到磁盘空间低于一定水位(可配置)
可以看到,File Cache 的核心在于任何的读写淘汰都是以文件为基本单位。因而内部机制较为简单,但也支撑起了大量的用户线上服务,时至今日,相信还有不少用户依然使用这套机制运行。
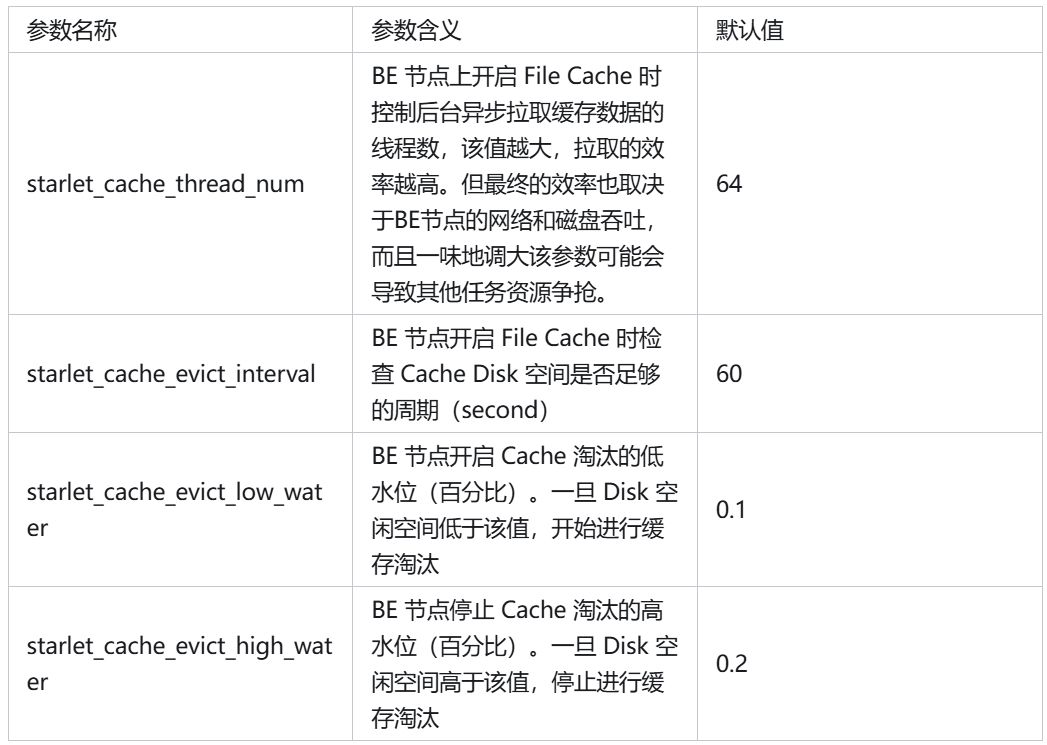
在 File Cache 机制中,存在如下参数来控制 Cache 行为:
对于使用 File Cache 的用户来说,可以在自己配置的缓存目录下观察到如下的子目录结构:
Cache V2: Block Cache
基于 File Cache 的 V1 版本虽然简单,但也存在一些问题,主要有:
- 空间效率低:用户实际可能经常访问的只有部分列数据,但 File Cache 必须将整个文件缓存在本地,造成缓存空间的极大浪费
- Cache Miss 时代价大:由于 Cache Miss 时需要拉取整个数据文件,造成缓存拉取时效率低下,拉取耗时,反映在用户侧的体感是,即使第一次已经访问过的数据,第二次再次访问还是会 Cache Miss,难以理解。而且也会占用大量的系统资源(拉取更多的数据会消耗更多的网络带宽、磁盘 IO、CPU 资源等)
- 淘汰效率低:如果用户的本地磁盘足够大,Cached File 足够多,实际测试发现每一轮 LRU 淘汰耗时太长(考虑到在本地文件系统上 list 上百万甚至千万的文件的效率)
- Cache Disk 不均衡:由于使用了 File Cache,而且设计上只能将某个分区映射到特定的磁盘上,因此,如果系统中存在多块磁盘,且存在一些数据量特别大的分区,那么可能会观察到磁盘使用的不均衡。
基于上述种种问题,我们设计并实现了新的 Local Disk Data Cache 系统 Cache V2,我们内部称之 StarCache,比较好地解决了 File Cache 中存在的种种问题。
区别于 File Cache,StarCache 是一种以特定大小 Block (典型大小如 1MB)为缓存单位的新型 Cache 系统。正是由于可以以更细粒度来管理缓存数据,因而,StarCache 具备更高的效率。
在内部实现中,StarCache 将用户提供的缓存磁盘创建一系列大文件(典型文件大小为 10G),这些大文件未来便是缓存用户热点数据的载体。
使用 StarCache 后,用户数据写入流程同 File Cache 基本保持一致。当用户进行数据导入时,数据文件依然同时写入对象存储和本地 Cache,只有当两者都写入成功,整个写入才会成功给用户返回。只是这里写入的是 StarCache,并且数据文件也会被按照 Block 为单位切割,按照 Block 逐个写入前面创建好的 Big File,同时 StarCache 也维护了 Block ID 至 Big File 中位置的映射。
读取时,StarRocks 内部会将要读取的内容映射至特定 Block,然后尝试从 StarCache 中读取该 Block 内容。如果未能命中,那么会同步发起一次对象存储的访问,将该 Block 对应的内容从对象存储下载回来,存入 StarCache 中后返回给用户。
可以看到,一个典型的区别在于读取时,StarCache 无需再启动后台线程异步地拉取整个数据文件,只需要将缺失的 Block 下载回来即可,很好地解决了之前 File Cache 的种种问题。而且,由于提前创建好了若干大文件,也无需了 File Cache 下 LRU 淘汰时 list 文件系统上的数据文件导致的效率低下问题,用户也无需担心淘汰不及时导致磁盘空间写满问题再次发生。
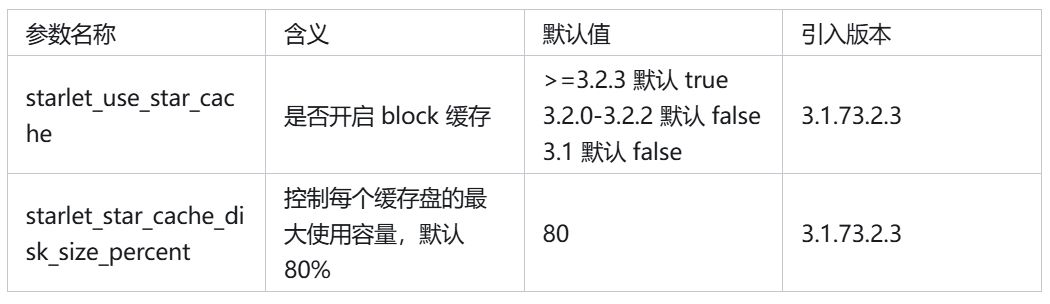
在 StarCache 中,BE or CN 上存在如下参数来控制 Cache 行为:
使用基于 StarCache 的 Cache V2 后,用户可以在自己配置的缓存目录下观察到类似如下的子目录结构:
Cache 最佳实践
对于 Cache,我们给出以下最佳实践仅供参考:
- 如果可以,为所有的表开启 Data Cache(建表时默认行为)
- 建议使用最新的版本,并确认开启 Block Cache
- 关注缓存磁盘的容量,并配置监控报警应对异常
- 如果计算节点使用多块缓存磁盘,建议关注缓存磁盘使用是否均衡
Cache 监控
在实际使用中,我们也建议用户密切关注 Cache 相关的监控指标,核心的诸如 Cache 命中率等,相关的部署可参考官方文档
https://docs.starrocks.io/zh/docs/administration/management/monitoring/Monitor_and_Alert/
Cache 常见问题
- 为什么我通过 du、ls 命令看到的 block cache 目录占用的空间远大于我实际的数据量?
block cache 的磁盘占用空间代表的是历史上的最高水位,和当前实际缓存的数据量并没有关系,假设导入了100G的数据,之后进行了 compaction,数据量变成了200G,然后之后进行了数据 GC,数据量变成了100G,那么 block cache 的磁盘占用空间仍然会保持在最高水位200G,但是 block cache 内部的实际缓存数据量会是100G。
- block cache 是否会自动淘汰?
会。目前策略是达到磁盘使用上限(参数可控制,默认80%)才会开始淘汰。但淘汰不会实际删除数据,只是将缓存的磁盘位置标记为空,后面的新缓存写入时会覆盖老缓存。所以即使发生淘汰,磁盘占用空间也不会下降,不会影响实际使用。
- 为什么我的磁盘水位一直维持在配置的最高点,不下降?
参考问题 2。
- 为什么我 drop 了表,远程存储也显示表文件已删除,但是我的 block cache 实际存储的数据量没有下降?
drop 表数据不会进行 block cache 缓存的删除,已经不存在的表的缓存会随着时间的推移,通过 block cache 的内部 LRU 逻辑淘汰(删除),不影响实际使用。
- 为什么我配置了 80%的磁盘容量,结果磁盘实际使用到了90% 甚至更多?
Block Cache 占用的磁盘容量是精确的,一定不会超过配置中设置的容量。一般是磁盘上其他东西,比如说: 1. 日志文件(http://be.INFO 等);
2. BE/CN Crash 产生的 Core 文件;
3. PK 表的持久化索引(${storage_root_path}/persist/ 目录)
4. 多个 BE/CN/FE 混部到了一个盘上
5. 外表的缓存(${STARROCKS_HOME}/block_cache/目录)
6. 其他
等等方面都可能占用了空间,可以在盘的根目录或各个子目录执行 du -h . -d 1查看具体是哪个目录占用了额外的空间。最后可以删除意外的占用部分,或者调小 block cache 使用的磁盘容量。
- 为什么我各个节点之间的缓存占用差异很大?
各个节点之间的节点缓存占用是无法保证在相邻水位的,这是单机缓存天然的限制,只要对查询延迟没有影响就行。占用差异受很多因素影响:
1. 不同节点加入集群的时间先后;
2. 不同节点服务的 tablet 数量差异;
3. 不同 tablet 内数据量差异;
4. 不同节点的 compaction、GC 情况差异;
5. 个别曾经 Crash、OOM 等等;















 1633
1633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









