







概述
本篇博客中我们主要描述nginx的hash表的实现原理。hash表在nginx内的应用非常广泛,比如,nginx通过hash表来组织所有的虚拟主机的域名,当请求到来时根据域名查找hash表来决定交由哪个虚拟主机来处理。除了普通的hash表之外,nginx还实现了带通配符匹配的hash表,其具体实现会在下一篇博客中阐述。本篇博客我们会以虚拟主机的域名构成的hash表为例来阐述nginx的hash表的主要实现原理。我们先来看看nginx http模块的一个典型配置:
server {
listen 9091;
server_name localhost example.org www.example.org *.example.org;
location /hello_string {
hello_string hello;
hello_counter on;
root html;
index index.html index.htm;
}
hello_string hehe;
}
server {
listen 9091;
server_name www.hello.org www.hello.com;
}数据结构
在描述nginx的hash内部实现之前,很有必要描述下与之相关的一些基础数据结构,主要有:ngx_hash_t、ngx_hash_init_t、ngx_hash_elt_t等,我们不妨一一咀嚼之。
typedef struct {
void *value;
u_short len;
u_char name[1];
} ngx_hash_elt_t;typedef struct {
ngx_hash_elt_t **buckets;
ngx_uint_t size;
} ngx_hash_t;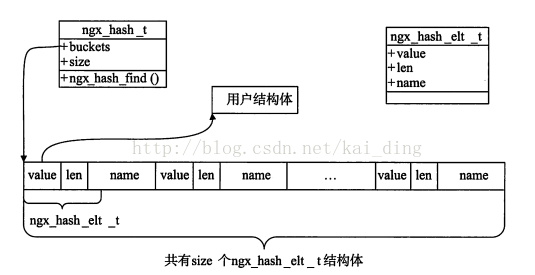
typedef struct {
ngx_hash_t *hash;
ngx_hash_key_pt key;
ngx_uint_t max_size;
ngx_uint_t bucket_size;
char *name;
ngx_pool_t *pool;
ngx_pool_t *temp_pool;
} ngx_hash_init_t;- hash:hash表的存储之地
- key:该hash表的hash方法
- max_size:hash表中桶的最大数量
- bucket_size:hash表中每个桶的最大容量
- name:hash表名称
- pool、temp_pool:hash表初始化过程中使用的内存池,暂时略过
简单了解了上面的几个数据结构之后,我们下面看看nginx如何根据需求构造出符合条件的hash表。还记得我们的例子嘛,将上面的配置中的所有域名作为hash映射的key,而该域名所在的虚拟主机(其实是由ngx_http_core_srv_conf_t来代表)作为value。在内存中构造一个hash表。
构造hash表
不妨让我们从hash表构造的调用者开始说起,nginx在解析完成上面的虚拟主机配置后,会调用ngx_http_server_names来构造这个hash表,我们抛开开始的一大段准备逻辑不谈,直接进入主题:
hash.key = ngx_hash_key_lc;
hash.max_size = cmcf->server_names_hash_max_size;
hash.bucket_size = cmcf->server_names_hash_bucket_size;
hash.name = "server_names_hash";
hash.pool = cf->pool;
if (ha.keys.nelts) {
hash.hash = &addr->hash;
hash.temp_pool = NULL;
if (ngx_hash_init(&hash, ha.keys.elts, ha.keys.nelts) != NGX_OK) {
goto failed;
}
}
接下来要进入今天的主题:创建需要的hash表,这个过程看起来会很复杂,但是我们只要把握一个核心思想就不会显得那么一头雾水:如何最大化的节约内存。希望大家在后续看的时候一定牢记这点。
为了避免看起来很费劲,我会将整个初始化过程分成几段来描述,好在整个初始化过程每段的逻辑相对清晰:
ngx_int_t
ngx_hash_init(ngx_hash_init_t *hinit, ngx_hash_key_t *names, ngx_uint_t nelts)
{
u_char *elts;
size_t len;
u_short *test;
ngx_uint_t i, n, key, size, start, bucket_size;
ngx_hash_elt_t *elt, **buckets;
// 首先作bucket_size有效性检查:bucket_size可配置
// 主要是检查配置的bucket_size的大小能否容纳每个ngx_hash_elt_t
for (n = 0; n < nelts; n++) {
if (hinit->bucket_size < NGX_HASH_ELT_SIZE(&names[n]) + sizeof(void *))
{
ngx_log_error(NGX_LOG_EMERG, hinit->pool->log, 0,
"could not build the %s, you should "
"increase %s_bucket_size: %i",
hinit->name, hinit->name, hinit->bucket_size);
return NGX_ERROR;
}
} // 这个test到底是什么作用呢
// 现在只是知道test数组中的每项填充的都是u_short
// 而且数组的总大小为hinit->max_size
test = ngx_alloc(hinit->max_size * sizeof(u_short), hinit->pool->log);
if (test == NULL) {
return NGX_ERROR;
}
// 为什么这里的bucket_size要减去sizeof(void *)
// 据说这个void *里面存储的是一个magic number
bucket_size = hinit->bucket_size - sizeof(void *);
// 这个start到底是什么意思呢
// 这里需要探测出要使用多少个bucket
start = nelts / (bucket_size / (2 * sizeof(void *)));
start = start ? start : 1;
if (hinit->max_size > 10000 && nelts && hinit->max_size / nelts < 100) {
start = hinit->max_size - 1000;
}
// 这里应该是看看size到哪就足够了
// 可能没必要分配max_size那么大,作者可真够变态的
for (size = start; size < hinit->max_size; size++) {
ngx_memzero(test, size * sizeof(u_short));
// 检测每个元素,看看当前桶的数量能否满足需求
for (n = 0; n < nelts; n++) {
if (names[n].key.data == NULL) {
continue;
}
key = names[n].key_hash % size;
test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names[n]));
#if 0
ngx_log_error(NGX_LOG_ALERT, hinit->pool->log, 0,
"%ui: %ui %ui \"%V\"",
size, key, test[key], &names[n].key);
#endif
if (test[key] > (u_short) bucket_size) {
goto next;
}
}
// 如果找到了满足需求的桶数量
// 那么下面就开始分配并初始化
goto found;
next:
continue;
}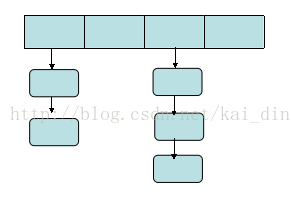
我们再来看看nginx的hash表高级在哪。其实基本思想是一样的,一个固定数组来模拟桶的数量,然后每个数组记录的又是另外一个数组B的头指针:数组B是为了解决冲突,类似我搓比做法中的链表:之所以采用数组B而非链表,是因为nginx实现的是一个静态hash表,无需在运行过程中去动态增加映射项。它的结构如下图所示:

好了,说完这些,我们再来看看上面那段代码吧。在我们的搓比实现中,第一个数组大小一般是自己定义的,其实这个值是不好确定的。但是nginx由于只用实现静态hash表,它可以根据自己的需要计算出数组的大小到底是多少即可。最大的为max_size,但实际可能用不上这么多,于是函数中从start开始检测每个size,看看当前size能否满足所有的key的需求,如果满足了,那么数组的大小为这么多其实就足够了,没必要再扩大。
找到了需要分配的数组大小后,就开始来计算所需的总的内存大小:
found:
// test[i]里面存储需要分配的内存大小
// 填充一个sizeof(void *)作为初始值是因为接下来会以这个作为标准判断该数组是否需要分配空间
for (i = 0; i < size; i++) {
test[i] = sizeof(void *);
}
// 计算每个key对应的映射项需要的总的大小,将其保存在key所属的数组项test[key]中
for (n = 0; n < nelts; n++) {
if (names[n].key.data == NULL) {
continue;
}
key = names[n].key_hash % size;
test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names[n]));
}
len = 0;
// 这里开始计算所有key对应的映射项需要分配的总空间大小
for (i = 0; i < size; i++) {
if (test[i] == sizeof(void *)) {
continue;
}
// 按照cache_line对齐
test[i] = (u_short) (ngx_align(test[i], ngx_cacheline_size));
len += test[i];
}
if (hinit->hash == NULL) {
// 为什么hash之前还要放一个ngx_hash_wildcard_t结构呢
hinit->hash = ngx_pcalloc(hinit->pool, sizeof(ngx_hash_wildcard_t)
+ size * sizeof(ngx_hash_elt_t *));
if (hinit->hash == NULL) {
ngx_free(test);
return NGX_ERROR;
}
buckets = (ngx_hash_elt_t **)
((u_char *) hinit->hash + sizeof(ngx_hash_wildcard_t));
} else {
buckets = ngx_pcalloc(hinit->pool, size * sizeof(ngx_hash_elt_t *));
if (buckets == NULL) {
ngx_free(test);
return NGX_ERROR;
}
}
接下来,我们就要分配内存并对每个key建立映射关系:
elts = ngx_align_ptr(elts, ngx_cacheline_size);
// 如果test[i]是sizeof(void *),那么说明数组的该项是无需分配空间的
for (i = 0; i < size; i++) {
if (test[i] == sizeof(void *)) {
continue;
}
// 桶数组的第i项指向其所属的内存
// 这里初始化了每一个需要存储在hash表中的elt
buckets[i] = (ngx_hash_elt_t *) elts;
elts += test[i];
}
// test[]接下来又其他用途,使用之前必须清0
for (i = 0; i < size; i++) {
test[i] = 0;
}
// 对每个key,计算其对应的ngx_hash_elt_t应指向的内存位置
for (n = 0; n < nelts; n++) {
if (names[n].key.data == NULL) {
continue;
}
// 首先计算落在哪个桶
// 然后计算落在桶里的哪个位置
// 每个桶里面分配的空间是连续的
key = names[n].key_hash % size;
elt = (ngx_hash_elt_t *) ((u_char *) buckets[key] + test[key]);
elt->value = names[n].value;
elt->len = (u_short) names[n].key.len;
ngx_strlow(elt->name, names[n].key.data, names[n].key.len);
test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names[n]));
}
// 这个还没弄清楚是干什么的
for (i = 0; i < size; i++) {
if (buckets[i] == NULL) {
continue;
}
elt = (ngx_hash_elt_t *) ((u_char *) buckets[i] + test[i]);
elt->value = NULL;
}
ngx_free(test);
hinit->hash->buckets = buckets;
hinit->hash->size = size;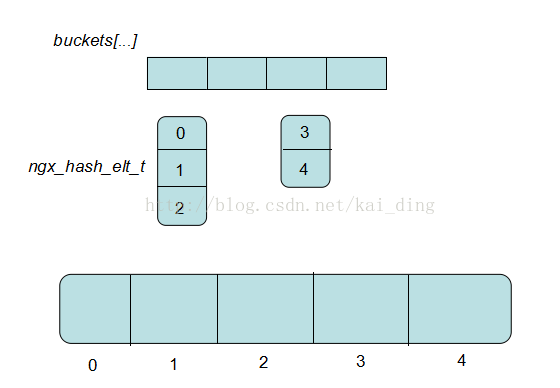
其中最下方是为所有的key的映射项ngx_hash_elt_t分配的连续内存空间,而每个ngx_hash_elt_t根据其key的hash结果找到其对应的内存起始地址。

















 1975
1975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









