







概述:现实生活中,语音信号一般都带有噪声,在进一步处理信号前(如语音识别,语音编码),往往要对信号进行降噪,本文介绍几种简单的降噪算法:自适应滤波器/谱减法/维纳滤波法。随着信噪比的减小,降噪方法处理的效果也随之变差,也经常使得语音丢字或者波形失真。如何在低信噪比情况下,达到不错的降噪效果,是一个值得探究的问题。
一. LMS自适应滤波器降噪
1.1. 基本原理
LMS自适应滤波器,利用前一刻已获得的滤波器参数,自动调节当前滤波器参数,以适应信号和噪声未知的或随机变化的统计特性,从而实现最优滤波。
1.2. 原理概述
输入信号序列xi(n),期望输出信号d(n),定义误差信号为:
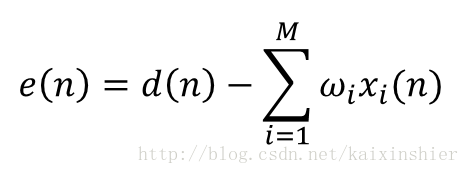
其中wi为权系数。
LMS算法的本质就是寻找最优的权系数wi,使得误差信号e(n)最小。
经过一系列推导,得到权系数的迭代公式:
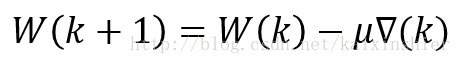
使用最陡下降法,那么LMS算法的关键问题就变为收敛因子 μ 和梯度因子的求解。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2930
2930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









