







写在前面
文本转语音(TTS)技术,作为连接数字世界与人类听觉的桥梁,其发展目标始终围绕着两个核心追求:合成语音的自然度与真实感,以及合成过程的高效性与实时性。传统的 TTS 系统,如级联式(文本分析 -> 声学模型 -> 声码器)或两阶段模型,虽然在音质上取得了不错的进展,但往往面临着训练流程复杂、错误累积、推理速度慢等问题。
本篇博客我们回顾一下端到端 TTS 领域的标杆之作,VITS (Variational Inference with adversarial learning for end-to-end Text-to-Speech)
VITS 的核心魅力在于它优雅地融合了多种先进的深度学习技术:
- 变分自编码器 (VAE):用于连接文本表示和语音波形,并引入隐变量来建模语音的自然变化。
- 归一化流 (Normalizing Flows):增强 VAE 先验分布的表达能力,提升生成样本的真实感。
- 生成对抗网络 (GAN):通过对抗学习进一步提升合成语音的感知质量。
- 随机时长预测器 (Stochastic Duration Predictor):赋予合成语音更自然的、多样化的韵律。
- 端到端训练与并行采样:简化训练流程,并实现快速的并行语音生成。
本文将作为 VITS 的深度技术解读,带你深入剖析其模型架构、核心组件、损失函数设计、训练策略、推理机制,特别是其如何实现高质量、高效率、多样性的语音合成,以及对流式推理的潜在支持。
一、 VITS 模型架构:三大核心模块的协同
VITS 的整体架构可以概括为三个核心模块,它们协同工作,共同完成从文本到语音波形的端到端转换。
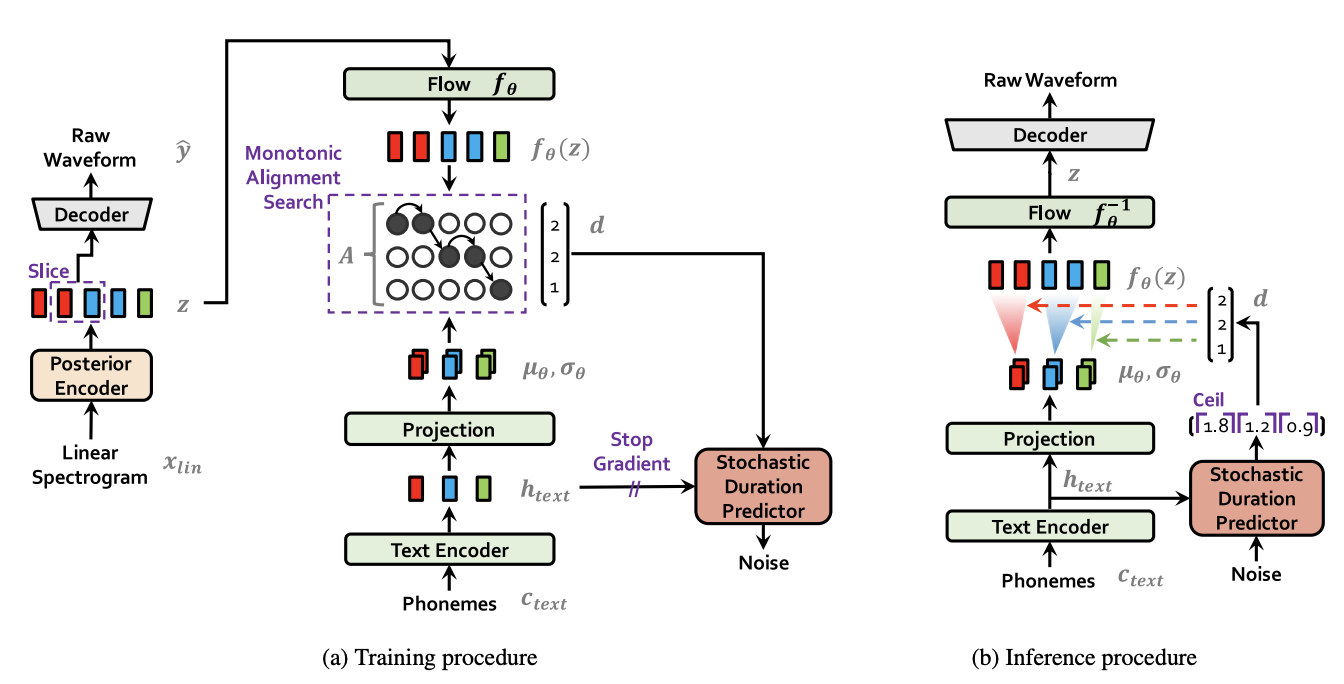
图注:VITS 系统框图,(a) 为训练流程,(b) 为推理流程。绿色模块代表条件 VAE 的核心组件。
1. 先验编码器 (Prior Encoder)
-
功能:将输入的文本音素序列转换为隐变量
z的先验分布p(z|c_text, A)。这个先验分布捕捉了给定文本内容下,语音应该具有的声学特征的统计规律。 -
核心组件:
- 文本编码器 (Text Encoder):通常是一个 Transformer Encoder,负责将输入的音素序列
c_text编码为隐层表示h_text。采用相对位置编码。 - 对齐模块 (Alignment Module - MAS):VITS 的一个关键创新是引入了单调对齐搜索 (Monotonic Alignment Search, MAS) 算法。由于文本音素序列和声学特征序列(或隐变量序列)的长度通常不一致,需要一个对齐机制来确定每个音素对应多少帧声学特征。MAS 能够在训练过程中,动态地搜索出最大化 VAE 证据下界 (ELBO) 的单调对齐关系
A。这避免了传统 TTS 中依赖外部对齐器或复杂的注意力机制。 - 归一化流 (Normalizing Flow):在文本编码器输出的均值和方差之上,叠加一个归一化流模块(例如基于 WaveNet 残差块的仿射耦合层)。这个流模型将简单的因子正态分布(由文本编码器预测)转换为更复杂、更具表达能力的先验分布。这是提升 VITS 生成样本真实感和多样性的关键。流模型被设计为体积保持 (volume-preserving) 的,即雅可比行列式为 1,简化了计算。
- 多说话人支持:通过全局条件 (Global Conditioning) 将说话人嵌入 (Speaker Embedding) 输入到文本编码器和归一化流的残差块中。
- 文本编码器 (Text Encoder):通常是一个 Transformer Encoder,负责将输入的音素序列
-
输出:隐变量
z的先验分布的参数(通常是均值和方差)。
2. 后验编码器 (Posterior Encoder)
-
功能:在训练阶段,将目标语音波形 (ground truth waveform) 转换为隐变量
z的后验分布q(z|x_lin)。这个后验分布用于指导先验编码器的学习,并作为 VAE 重建损失的一部分。 -
核心组件:
- 频谱转换:首先将原始语音波形
x通过短时傅里叶变换 (STFT) 转换为线性频谱图 (linear spectrogram)x_lin。论文指出,使用线性频谱图(相比梅尔频谱图)作为后验编码器的输入,可以为模型提供更高分辨率的信息,从而提升合成质量。 - 非因果 WaveNet 残差块:后验编码器的主体结构,由一系列非因果的 WaveNet 残差块组成。这些块包含带门控激活单元的空洞卷积,能够有效地从线性频谱图中提取隐变量
z。 - 多说话人支持:同样通过全局条件将说话人嵌入输入到残差块中。
- 频谱转换:首先将原始语音波形
-
输出:隐变量
z的后验分布的参数(均值和方差)。 -
注意:后验编码器仅在训练时使用,推理时直接从先验编码器采样的
z进行解码。
3. 解码器 (Decoder)
-
功能:将从先验分布(推理时)或后验分布(训练时,通常不直接用,而是用先验采样的 z)中采样的隐变量
z,解码为最终的原始语音波形。 -
核心组件:本质上是一个高质量的声码器。VITS 采用了 HiFi-GAN V1 的生成器作为其解码器。HiFi-GAN 的生成器由一系列转置卷积层组成,每个转置卷积后跟着一个多感受野融合模块 (Multi-Receptive Field Fusion, MRF)。
-
多说话人支持:将说话人嵌入作为条件输入到解码器的每一层。
-
输出:合成的语音波形
ŷ。
4. 判别器 (Discriminator) - 用于对抗学习
- 功能:在训练阶段,区分解码器生成的语音和真实的语音,从而通过对抗学习提升解码器生成语音的感知质量。
- 核心组件:VITS 采用了 HiFi-GAN 的多周期判别器 (Multi-Period Discriminator, MPD)。MPD 包含多个子判别器,每个子判别器在不同周期的语音信号上进行操作,能够捕捉不同时间尺度的声学伪影。论文中提到,为了提高训练效率,VITS 仅保留了 MPD 的第一个子判别器(在原始波形上操作),并移除了多尺度判别器。
5. 随机时长预测器 (Stochastic Duration Predictor)
- 功能:从文本的隐层表示
h_text预测每个音素的时长d。与传统的确定性时长预测器不同,VITS 引入了随机性,使得即使是相同的文本,每次合成的语音在韵律节奏上也可能有所不同,更接近人类说话的自然变化。 - 核心组件:一个基于流的生成模型,用于建模音素时长的分布。
- 条件输入:
h_text(来自文本编码器)。 - 目标:每个音素的真实时长(通过 MAS 对齐得到)。
- 技术细节:
- 变分去量化 (Variational Dequantization):将离散的整数时长转换为连续的实数,以便使用连续的归一化流。
- 变分数据增强 (Variational Data Augmentation):将时长和另一个随机变量
ν拼接起来,输入到流模型中,增加模型的表达能力。 - 流模型:采用神经网络样条流 (Neural Spline Flows) 来建模时长分布。
- 停止梯度 (Stop Gradient):在训练时长预测器时,对输入的
h_text施加停止梯度,使其训练不影响文本编码器。
- 条件输入:
- 输出:在推理时,从学习到的分布中采样得到每个音素的时长。
小结:VITS 的架构通过 VAE 连接了文本和语音,通过归一化流增强了先验的表达能力,通过 GAN 提升了波形的感知质量,并通过随机时长预测器引入了自然的韵律变化。MAS 对齐算法是其实现端到端训练的关键。
二、 损失函数:多目标协同优化
VITS 的训练涉及多个损失函数,共同优化模型的各个部分:
-
重构损失 (Reconstruction Loss -
L_recon):- 目标:使解码器生成的语音在声学特征上接近目标语音。
- 计算:在梅尔频谱图域计算生成语音
ŷ和目标语音y之间的 L1 损失。L_recon = || mel(y) - mel(ŷ) ||_1 - 原因:梅尔频谱图更符合人类的听觉感知特性。
-
KL 散度损失 (KL Divergence Loss -
L_kl):- 目标:使后验分布
q(z|x_lin)逼近先验分布p(z|c_text, A)。这是 VAE 的核心损失之一。L_kl = KL(q(z|x_lin) || p(z|c_text, A)) - 作用:正则化隐空间,使得从先验中采样得到的
z能够生成合理的语音。
- 目标:使后验分布
-
时长预测损失 (Duration Prediction Loss -
L_dur):- 目标:训练随机时长预测器准确地预测音素时长。
- 计算:负的变分下界 (negative variational lower bound),类似于
L_kl,但针对的是时长d而不是声学特征z。log p(d|h_text) >= E_q(u,ν|d,h_text) [log (p(d-u, ν|h_text) / q(u,ν|d,h_text))] L_dur = - VLB_duration
-
对抗学习损失 (Adversarial Learning Losses):
- 生成器损失 (
L_adv(G)): 鼓励解码器(生成器 G)生成能够骗过判别器 D 的语音。L_adv(G) = E_z [(D(G(z)) - 1)^2] - 判别器损失 (
L_adv(D)): 训练判别器 D 准确区分真实语音和生成语音。L_adv(D) = E_(y,z) [(D(y) - 1)^2 + (D(G(z)))^2] - 特征匹配损失 (
L_fm(G)): 鼓励生成器 G 生成的语音在判别器 D 的中间层特征上与真实语音相似。这有助于稳定 GAN 训练并提高样本质量。
其中L_fm(G) = E_(y,z) [Σ_l (1/N_l) * || D_l(y) - D_l(G(z)) ||_1]D_l表示判别器的第l层特征图,N_l是特征数量。
- 生成器损失 (
-
最终总损失 (Final Loss -
L_vae):- 将上述损失加权组合:
L_total = L_recon + L_kl + L_dur + L_adv(G) + L_fm(G) - (判别器有其独立的
L_adv(D)损失)
- 将上述损失加权组合:
关键点:VITS 通过精心设计的复合损失函数,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











