






目录
-
一、插值法
-
二、最小二乘线性拟合
-
三、 非线性曲线拟合


数值计算主要研究如何利用计算机更好地解决各种数学问题,包括连续系统离散化和离散型方程求解,并考虑误差、稳定性和收敛性等问题。
一、插值法
插值问题是数值分析的基本问题之一,其原理就是在离散数据的基础上通过插补得到连续函数,使得这条连续曲线通过全部给定的离散数据点。利用插值法可以通过函数在有限个点处的取值状况估计出该函数在其他点处的值。1.1拉格朗日插值法-适合给出插值节点的情况SciPy库的interpolate模块提供了lagrange函数来进行Lagrange插值计算,其语法格式如下。
scipy.interpolate.lagrange(x,w)# x:接受 array,表示插值节点的x坐标。无默认值# w:接受 array,表示插值节点的y坐标,数目需要与x对应。无默认值假设有一个每年生产240吨产品的食品加工厂,需要统计生产费用,但由于该厂的各项资料不全,无法统计。这种情况下,统计部门收集了设备、生产能力和与该厂大致相同的5个食品加工厂的相关产量和生产费用的资料,如下表所示,请参考数据估计生产费用。
1.1拉格朗日插值法-适合给出插值节点的情况
数值计算主要研究如何利用计算机更好地解决各种数学问题,包括连续系统离散化和离散型方程求解,并考虑误差、稳定性和收敛性等问题。
SciPy库的interpolate模块提供了lagrange函数来进行Lagrange插值计算,其语法格式如下。
scipy.interpolate.lagrange(x,w)
# x:接受 array,表示插值节点的x坐标。无默认值
# w:接受 array,表示插值节点的y坐标,数目需要与x对应。无默认值假设有一个每年生产240吨产品的食品加工厂,需要统计生产费用,但由于该厂的各项资料不全,无法统计。这种情况下,统计部门收集了设备、生产能力和与该厂大致相同的5个食品加工厂的相关产量和生产费用的资料,如下表所示,请参考数据估计生产费用。

from scipy import interpolate #导入库SciPy的interpolate模块
import numpy as np
x = np.array([200,220,250,270,280])
y = np.array([4,4.5,4.7,4.8,5.2])
la = interpolate.lagrange(x,y)
print('产量为240吨时,费用为:',la(240))输出结果:
产量为240吨时,费用为:4.7142857142827665v
产量为240吨时,费用为:4.7142857142827665v1.2牛顿插值法-适合给出插值节点的情况
# 自定义一阶跳跃差分函数
def diff_self (xi,k):
'''
xi:接收array。表示自变量x。无默认,不可省略。
k:接收int。表示差分的次数,无默认,不可省略
'''
diffValue = []
for i in range(len(xi)-k):
diffValue.append(xi[i+k]-xi[i])
return diffValue
# 自定义求取差商函数
def diff_quot(xi,yi):
'''
xi:接收array。表示自变量x。无默认,不可省略。
yi:接收array。表示因变量y。无默认,不可省略。
'''
length = len(xi)
quot = []
temp = yi
for i in range(1,length):
tem = np.diff(temp,1)/diff_self(xi,i) # 此处需要numpy广播特性支持
quot.append(tem[0])
temp = tem
return(quot)
# 自定义求取(x-x0)*(x-x1).....*(x-x0)
def get_Wi(k = 0, xi = []):
'''
xi:接收array。表示自变量x。无默认,不可省略。
yi:接收array。表示因变量y。无默认,不可省略。
'''
def Wi(x):
'''
x:接收int,float,ndarray。表示插值节点。无默认。
'''
result = 1.0
for each in range(k):
result *= (x - xi[each])
return result
return Wi
# 自定义牛顿插值公式
def get_Newton_inter(xi,yi):
'''
xi:接收array。表示自变量x。无默认,不可省略。
yi:接收array。表示因变量y。无默认,不可省略。
'''
diffQuot = diff_quot(xi,yi)
def Newton_inter(x):
'''
x:接收int,float,ndarray。表示插值节点。无默认。
'''
result = yi[0]
for i in range(0, len(xi)-1):
result += get_Wi(i+1,xi)(x)*diffQuot[i]
return result
return Newton_inter
print('产量为240吨时,费用为:',get_Newton_inter(x,y)(240))结果输出:
产量为240吨时,费用为:4.714285714285715产量为240吨时,费用为:4.7142857142857151.2样条插值
样条插值则是分段给出多个低次多项式通过的所有数据点。
SciPy库中的interpolate模块提供了UnivariateSpline类来进行一般的样条插值计算,其语法格式如下。
class scipy.interpolate.UnivariateSpline(x,y,w=None,bbox=[None,None],k=3,s=None,ext=0,check_finite=False)
# x:接受 array,表示插值节点的x坐标。无默认值
# y:接受 array,表示插值节点的y坐标,数目需要与x对应。无默认值
# w:接受 array,表示样条的拟合权重。默认为None
# k:接受 int,表示样条曲线的平滑程度,必须小于或等于5。默认为3
1.2样条插值
样条插值则是分段给出多个低次多项式通过的所有数据点。
SciPy库中的interpolate模块提供了UnivariateSpline类来进行一般的样条插值计算,其语法格式如下。
class scipy.interpolate.UnivariateSpline(x,y,w=None,bbox=[None,None],k=3,s=None,ext=0,check_finite=False)
# x:接受 array,表示插值节点的x坐标。无默认值
# y:接受 array,表示插值节点的y坐标,数目需要与x对应。无默认值
# w:接受 array,表示样条的拟合权重。默认为None
# k:接受 int,表示样条曲线的平滑程度,必须小于或等于5。默认为3使用样条插值求解上例问题
from scipy import interpolate #导入库SciPy的interpolate模块
import numpy as np
x = np.array([200,220,250,270,280])
y = np.array([4,4.5,4.7,4.8,5.2])
sp1 = interpolate.UnivariateSpline(x,y,k=4)
print('产量为240吨时,费用为:',sp1(240))输出结果:
产量为240吨时,费用为:4.714285714285714
产量为240吨时,费用为:4.714285714285714
通过对比结果可以发现,在整体插值效果上,样条插值和Lagrange插值、Newton插值相差不大,但是根据其原理,样条插值计算量更少,并且在计算机上的实现难度更低。但同时也需要注意,样条插值只能保证在各段小区间点上的连续性,无法保证整条曲线在整个大区间内绝对连续且光滑。
二、最小二乘线性拟合
数据拟合与插值相比,数据拟合不要求近似函数通过所有的数据点,而要求它反映原函数整体的变化趋势,而插值法在节点处取函数值。数据拟合最常用的方法是最小二乘法。
SciPy库中optimize模块的least_squares函数提供了利用最小二乘法求解方程的功能,其语法格式如下。
scipy.optimize.least_squares(func,x0,jac='2-point',bounds=(-inf,inf),
method='trf',ftol=1e-08,xtol=1e-08,gtol=1e-08,x_scale=1.0,loss='linear',
f_scale=1.0,,diff_step=None,tr_solver=None,tr_options={},jac_sparsity=None,
max_nfev=None,verbose=0,args=(),kwargs={})
# func:接受function,表示需要求解的函数。无默认值
# x0:接受 array,表示求取的函数参数的初始值。无默认值
# jac:接受特殊str,表示计算jacobi矩阵的方法。默认为2-point
# bounds:接受tuple,表示函数参数的取值范围。默认为(-inf,inf)
# args:接受tuple,表示函数或者jacobi矩阵的额外参数。无默认值使用最小二乘法求解纤维拉抻倍数与强度的线性拟合方程
import matplotlib.pyplot as plt
from scipy import optimize #导入库SciPy的interpolate模块
import numpy as np
# 拉伸倍数
x = np.array([1.9,2,2.1,2.5,2.7,2.7,3.5,3.5,4,4,4.5,4.6,5,5.2,6,6.3,6.5,7.1,8,8,8.9,9,9.5,10])
# 强度
y = np.array([1.4,1.3,1.8,2.5,2.8,2.5,3,2.7,4,3.5,4.2,3.5,5.5,5,5.5,6.4,6,5.3,6.5,7,8.5,8,8.1,8.1])
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
#定义误差
def regula(p):
'''
p:接收tuple、list,表示函数的系数,如ax+b中的a、b。无默认值
'''
a,b = p
return y - a*x-b
# 使用最小二乘法确定a和b
result = optimize.least_squares(regula,[1,0])
a,b = result.x #a,b存储在result的x下
print('线性拟合的结果:a为%s,b为%s'%(a,b))
print('线性拟合的结果展示:')
plt.figure(figsize=(6,4))
plt.scatter(x,y,label='真实值') #绘制原来的点
plt.plot(x,a*x+b,'r',label='拟合直线') #拟合直线
plt.legend()plt.title('纤维线性拟合')
plt.xlabel('拉伸倍数')
plt.ylabel('强度')
plt.xlim(0,11)
plt.ylim(0,9)
plt.savefig('D:/data/纤维线性拟合.png')
plt.show()
输出结果:
线性拟合的结果:a为0.8587342891022356,b为0.15047408914437352
线性拟合的结果展示:
import matplotlib.pyplot as plt
from scipy import optimize #导入库SciPy的interpolate模块
import numpy as np
# 拉伸倍数
x = np.array([1.9,2,2.1,2.5,2.7,2.7,3.5,3.5,4,4,4.5,4.6,5,5.2,6,6.3,6.5,7.1,8,8,8.9,9,9.5,10])
# 强度
y = np.array([1.4,1.3,1.8,2.5,2.8,2.5,3,2.7,4,3.5,4.2,3.5,5.5,5,5.5,6.4,6,5.3,6.5,7,8.5,8,8.1,8.1])
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
#定义误差
def regula(p):
'''
p:接收tuple、list,表示函数的系数,如ax+b中的a、b。无默认值
'''
a,b = p
return y - a*x-b
# 使用最小二乘法确定a和b
result = optimize.least_squares(regula,[1,0])
a,b = result.x #a,b存储在result的x下
print('线性拟合的结果:a为%s,b为%s'%(a,b))
print('线性拟合的结果展示:')
plt.figure(figsize=(6,4))
plt.scatter(x,y,label='真实值') #绘制原来的点
plt.plot(x,a*x+b,'r',label='拟合直线') #拟合直线
plt.legend()
plt.title('纤维线性拟合')
plt.xlabel('拉伸倍数')
plt.ylabel('强度')
plt.xlim(0,11)
plt.ylim(0,9)
plt.savefig('D:/data/纤维线性拟合.png')
plt.show()输出结果:
线性拟合的结果:a为0.8587342891022356,b为0.15047408914437352
线性拟合的结果展示: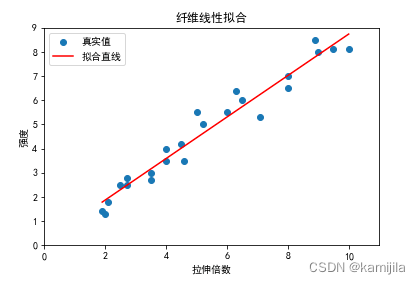
三、 非线性曲线拟合
常见的非线性方程(组)求解问题有如下两种。
(1)求取给定范围内的某个解,而解的粗略位置事先已从问题的物理背景或其他方法得知。
(2)求取方程(组)的全部解,或者求取给定区域内的所有解,而解的个数和位置事先并不知道。这在超越方程的情形下是比较困难的。
例子:现有A、B两辆车,其中,B车在A车前方100m处;A车的初始速度为0,加速度为6m/s2;B车的速度为15m/s,加速度为1m/s2。试问,A车在哪个时间能够追上B车?
3.1、二分法求解非线性方程
针对上述第一种问题,二分法是最简单的一种方法。二分法也称为对分法(或逐次半分法),其基本思想是先确定方程f(x)=0含根的区间[a,b],再把区间逐次二等分。
import numpy as np
# 定义求解函数
def f1(x):
'''
x:表示函数的未知数x。
'''
return(2.5*x**2-15*x-100)
# 定义二分法函数
def dichotomy(a,b,preci_ratio = 10**-2):
'''
a,b :接收数值,表示二分法的区间。无默认。
preci_ratio:接收数值,表示精确率。默认为10**-2
'''
# 判定方程在区间内是否至少一个解
if (f1(a) != 0) & (f1(b) != 0) & (f1(a) * f1(b) < 0):
result = []
# 判定是否已经满足精确率
while (np.abs((b - a))/2) >= preci_ratio:
c = (a+b)/2.0
pre = []
pre.extend([a,b,c])
if f1(a)*f1((c))>0:
a=c
elif f1(a)*f1((c)) < 0:
b = c
else:
a = b = c
pre.append(f1(c))
result.append(pre)
print(' a b (a+b)/2 f(x)')
# 将返回值变为array,方便查看
return(np.array(result))
print(dichotomy(4,14,0.01))结果输出:

3.2、迭代法求解非线性方程
迭代法是数值计算中最常用的一种方法,是一种逐次逼近的方法,其基本思想是先给出方程的一个近似值,然后反复利用某种迭代公式校正根的近似值,使近似根逐步精确化,直到得到满足精度要求的近似根为止。
解:取初始点为1,取最大迭代次数为100,精度要求为10−2,迭代公式为:
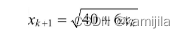
import numpy as np
# 定义求解函数
def f1(x):
return(2.5*x**2-15*x-100)
# 定义迭代函数
def iter(x):
return((x**2 -40)/6)
# 定义迭代求解函数的根
def iteration(start_num,max_iter,preci_ratio):
'''
start_num:接收数值,表示初始值,无默认。
max_iter:接收数值,表示最大迭代次数,无默认。
preci_ratio:接收数值,表示精确度,无默认
'''
result = []
a = start_num
for i in range(max_iter+1):
fx= f1(a)
b = iter(a)
if np.abs(b-a) > preci_ratio:
proc = [i,a,fx]
a = b
else:
proc = [i,a,fx]
result.append(proc)
break
result.append(proc)
print('k x fx')
return(np.array(result))
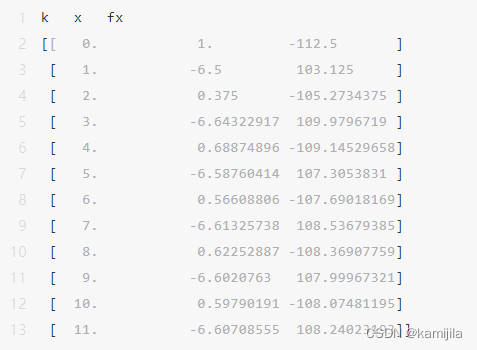
print(iteration(1,11,0.001))结果输出:
3.3、Newton法求解非线性方程
Newton(牛顿)法是求解非线性方程最有效的方法之一。对于非线性方程f(x)=0,求解它的困难之处在于f(x)是非线性函数,故应考虑f(x)的线性展开。
SciPy库的optimeize模块提供了newton函数用于求解非线性方程,其语法格式如下。
scipy.optimize.newton(func,x0,fprime=None,args=(),tol=1.48e-08,maxiter=50,fprime2=None)
# func:接受function,表示需要求解的函数。无默认值
# x0:接受 array,表示初始估计值。无默认值
# fprime:。接受function,表示函数的导数,默认为None
# args:接受tuple、list,表示函数的额外参数。无默认值
# tol:接受float,表示允许的误差。默认为1.48e-08
# maxiter:接受int,表示最大迭代次数。默认为50
# fprime2:接受function,表示函数的二阶导数。默认为None基于Python使用Newton法求解本例方程的根
from scipy import optimize
# 定义求解函数
def f1(x):
return(2.5*x**2-15*x-100)
root1 = optimize.newton(f1,x0=5,tol=0.001,
fprime= lambda x:5*x-15)
print('使用Newton法求解的结果为:',root1)结果输出:
使用Newton法求解的结果为:10.000000000000002
相比于迭代法,Newton法的优点在于不需要选择迭代公式,只要非线性方程在区间中有解,该方法就能收敛。
3.4、Newton法求解非线性方程组
SciPy库中的optimize模块并未提供使用Newton法求解非线性方程组的函数,但是提供的fsolve函数可以验证非线性方程组的求解正确与否,其语法格式如下。
scipy.optimize.fsolve(func,x0,args=(),fprime=None,full_output=0,
col_deriv=0,xtol=1.49012e-08,maxfev=0,band=None,epsfcn=None,factor=100,
diag=None)
# func:接受function,表示需要求解的函数(方程组)。无默认值
# x0:接受 array,表示初始估计值。无默认值
# fprime:。接受function,表示方程组的jacobi矩,默认为None
# full_output:接受bool,表示是否输出所有解。默认为0
# maxfev:接受int,表示调用函数的最大数目。默认为0,表示最大为100(N+1)个,
N为初始方程组内方程的数目。基于Python使用Newton法求解本例方程的根
from scipy import optimize
# 定义非线性方程组
def f1(p):
x1,x2=p
return [x1**2+x2**2-5,(x1+1)*x2-3*x1-1]
# 使用fsolve解方程组
root2 = optimize.fsolve(f1,[1,1])
print('x1,x2分别为:',root2)结果输出:
x1,x2分别为: [1. 2.]














 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









