







我的博客原文地址 :http://www.huihuidehui.top/e994b0bc/
前言
我的博客原文地址 :
如题例如抓取这样一个新闻下的所有评论:https://www.thepaper.cn/newsDetail_forward_4489661。
首先,列出需要抓取的数据:
- 新闻标题
- 新闻发布日期
- 评论者的昵称
- 评论的内容
1. 分析网页请求找到需要的数据
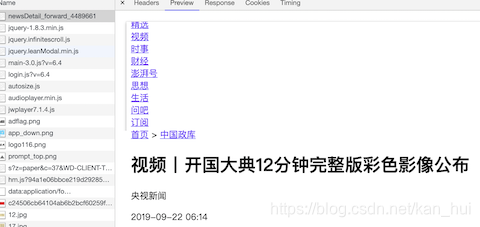
看下图,在网页的第一个请求里面已经包括了1,2两条的数据。
接着在浏览器中向下滑动新闻网页加载评论,同时关注控制台,注意搜索框里的load,如下图浏览器会不断的发送请求给服务器,在这个请求的相应里面就包含了需要的3,4条(评论,评论者的用户名)数据。看一下这个请求的url有一堆的请求参数尝试精简下最后得到这样的urlhttps://www.thepaper.cn/load_moreFloorComment.jsp?contid=4489661startId=24750775。在这个url里面只有两个参数,第一个是新闻的id,第二是评论页的id。有了这个url就可以根据不同的startid构造出评论的url最终的抓到所有的评论信息。
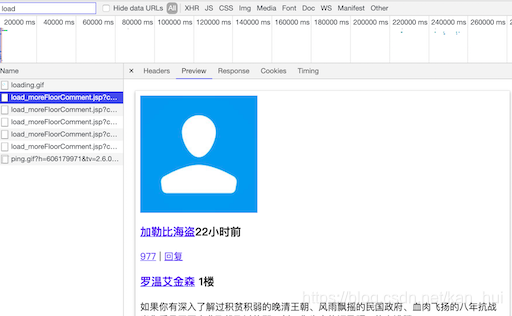
2. 怎么找到不同的startid?
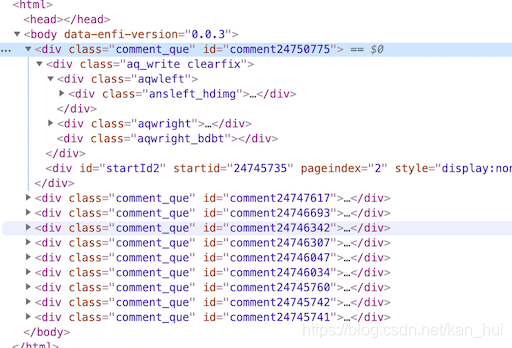
同样是上面那个图,在新标签打开对应的请求,看一下html源码,在第一条评论div里面有一个startid=‘24745735’。
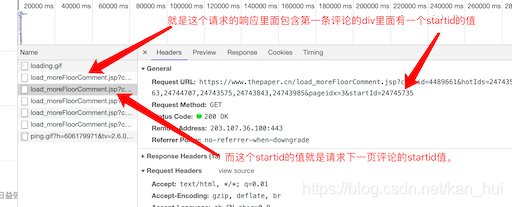
记住这个值,再回去看一下第二条请求评论的url,发现最后的startid值就是第一条请求评论的url里面的startid值。就是这个样子:
至此,所有的数据理论上来说都可以找到了。剩下的就是写代码了。
3.码码码码码码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# ************************************************************************
# *
# * @file:penpai.py
# * @author:kanhui
# * date:2019-09-22 11:40:30
# * @version 3.7.3
# *
# ************************************************************************
import requests
import re
from lxml import etree
import json
class PengPaiSpider():
'''
给定一个澎湃新闻的url爬取其下的评论信息
例如:https://www.thepaper.cn/newsDetail_forward_1292455
'''
def __init__(self):
print('input url:')
# 新闻url地址
self.url = input()
# 用来判断是否到达最后一页,在请求评论页面时的第一条评论里有一个startId参数如果为0则表示没有下一页了
self.next_id = ''
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









