







引
首先,混合专家层的提出非常早,早在九几年就提出来了。在机器学习中运用。想法是简单的分治法:将大的问题拆分成各个小问题,训练不同的专家来针对性地解决这些小问题,最后再将专家们的输出结合起来。
这点和ensemble learning有异曲同工之处,流行的结合方法也有bagging boosting之类的,我甚至觉得原理上讲,他们可以归为一类。
MoE的关注重点是
- 专家之间应该保证足够的差异性,这样才能使得问题域被正确地划分
- 专家的判断如何汇总成一个输出,即如何形成一个最终判断
就专家的差异性,传统的集成学习,可以提供给不同的数据集给不同专家训练,可以使专家的结构有所不同,等等
专家的汇总输出,可以加权求和,可以直接平均,等等
MoE的做法是,用一个gating network,即门控网络,来负责分发作业给各个专家。这个门控网络的作用一是对数据有个初步的认知,且知道该将此数据交给哪个专家来处理,二是平衡各个专家之间的关系,即让各个专家不至于被“冷落”
相关工作
2017 NIPS
OUTRAGEOUSLY LARGE NEURAL NETWORKS:THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER
谷歌这篇论文将MoE用于文本任务,构建庞大的专家网络,同时用门网络来保证其稀疏性:即只有少数专家被选中并参与判断。让参数量巨大的网络构成,变得人人都可以玩,同时又保证该参数量级别的网络拥有足够的表达能力。
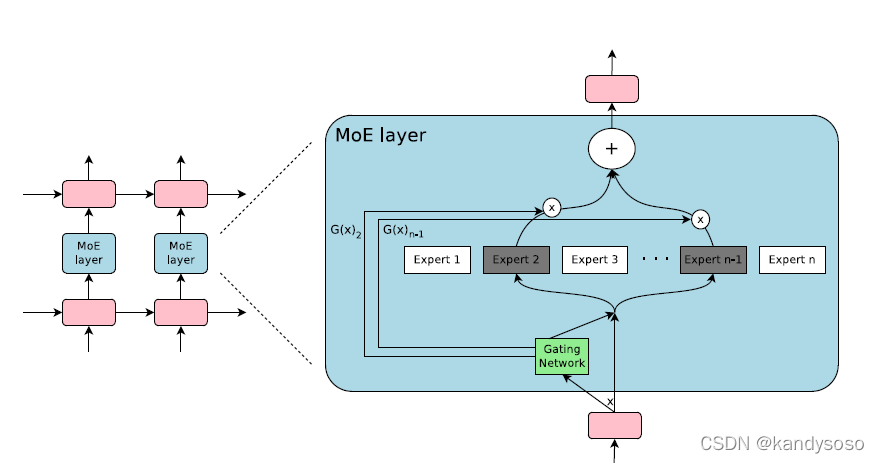
文章将MoE的结构嵌入到循环神经网络中去。
其中门网络由一个全连接层和一个softmax构成,每个expert也是小网络。gating出来只选择概率最大的K个专家的输出形成一个概率分布,这样就保证了专家的稀疏性,即论文标题中的sparsely-gated network。
这样的网络结构可以端对端的基于反向传播训练,出来效果惊人云云。
后面谷歌在图像方面,搞出了 V-MoE,在ImageNet上干到了第四。
截图来源于 paperwithcode
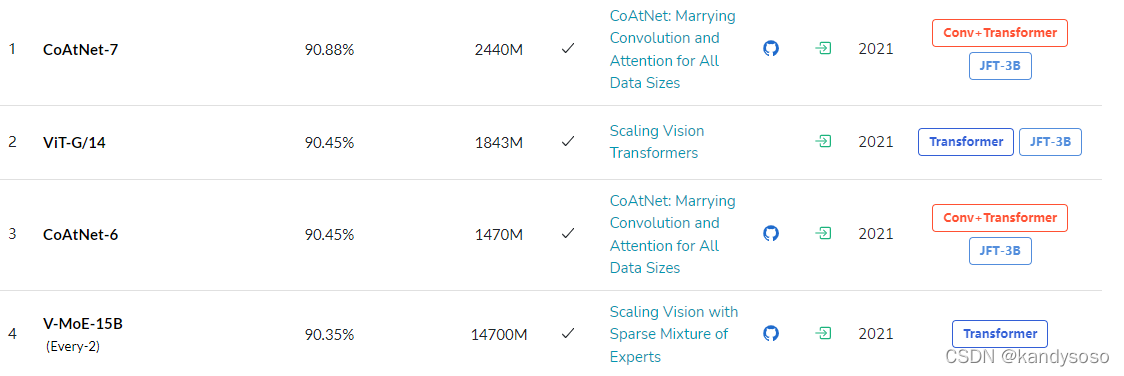
可见MoE的潜力巨大
结
MoE这种结合模型的技巧,是非常值得我们关注的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









