







调研RobotTransformer
RT-1
起因:机器人一、缺数据,二、缺快速应用数据到实际的好的模型
成果:一个可以实时进行推断,标志化机器人的行为的多任务模型
结构:transformer:输入画面(短视频)以及描述性自然语言,输出tokenized的action
组件:Image tokenization、Action tokenization(Action tokenization: The robot’s action dimensions are 7 variables for arm movement (x, y, z, roll, pitch, yaw, gripper opening), 3 variables for base movement (x, y, yaw), and an extra discrete variable to switch between three modes: controlling arm, controlling base, or terminating the episode. Each action dimension is discretized into 256 bins.)、Token Compression(输入图片进行标志化压缩)
特点:数据训练时,还用了非自己机器人的其他数据来训练
link of origin
RT-2
起因:要使得机器人能理解语言描述的任务并正确执行
成果:a novel vision-language-action (VLA) model that learns from both web and robotics data, and translates this knowledge into generalised instructions for robotic control, while retaining web-scale capabilities.
结构:Pathways Language and Image model (PaLI-X) and Pathways Language model Embodied (PaLM-E) to act as the backbones of RT-2.模型大小是: (1) RT-2-PaLI-X is built from 5B and 55B PaLI-X , and (2) RT-2-PaLM-E is built from 12B PaLM-E
和RT-1类似的action string输入,对机械臂的pos change,rotation, gripper离散化数值
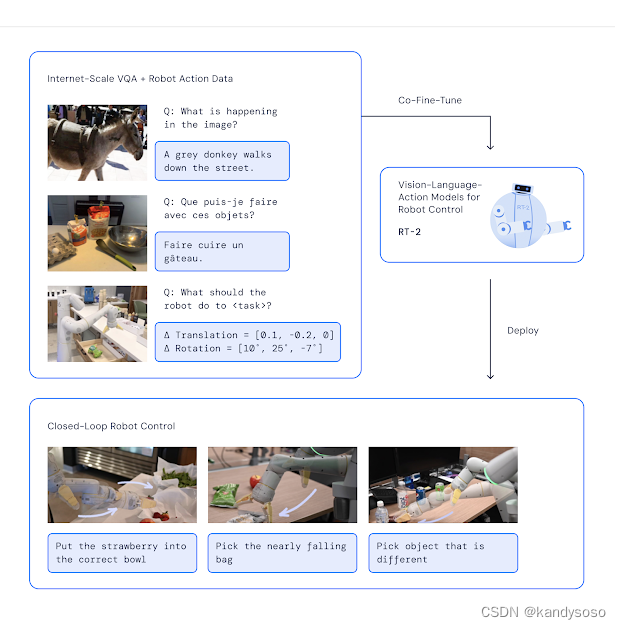
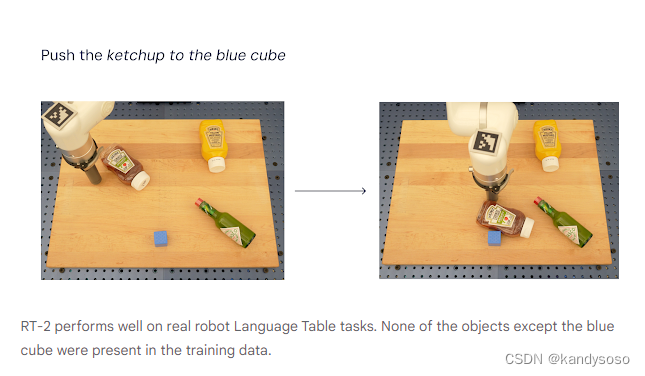
特点:给机器人的指令数据很多是训练集从未出现过的,需要模型具有泛化迁移的能力。
此外,RT2还引入了chain-of-thought reasoning,生成plan加上action,如下图,非常地amazing。

论文给出的pipeline如图所示:
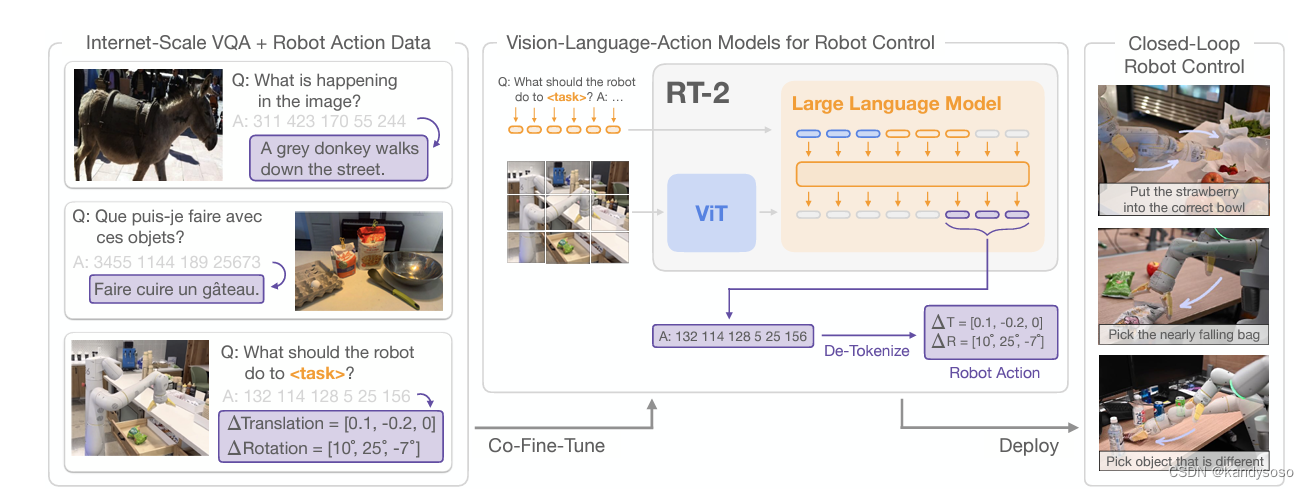
RT-2将VLM进行微调,输入图片和自然语言描述的任务,输出action code,变身成了VLA(vision language action model)。
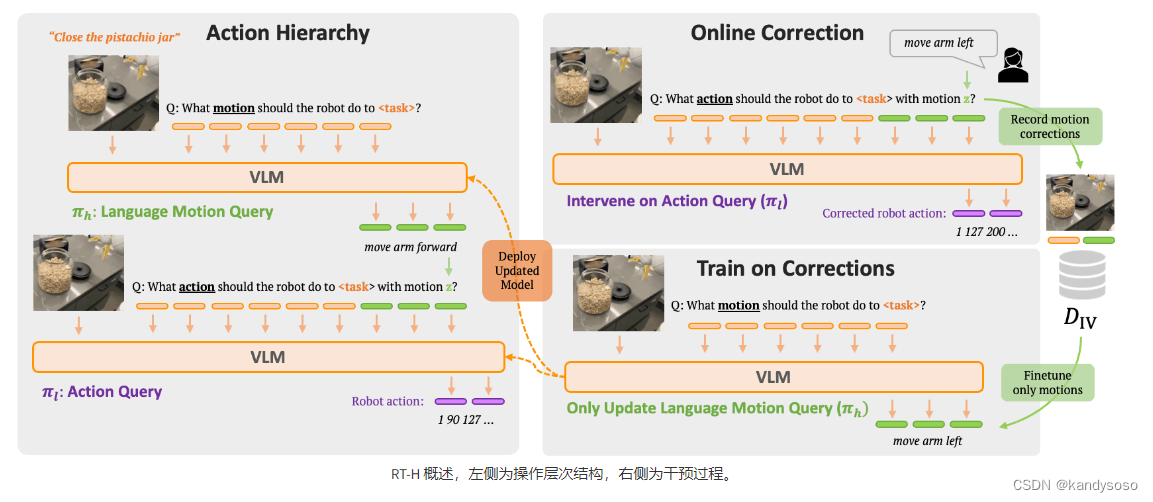
RT-H
新的RT,优化方式是,将高级动作(如倒茶)的指令预测,拆分成低级动作(将机械臂前移,将机械臂左旋转,抓紧握爪)这样的指令,从而使得任务之间共享的数据更多,而且人为干预更加容易。RT-H 利用这种语言-动作层次结构,通过有效利用多任务数据集来学习更强大、更灵活的策略。
示意图:
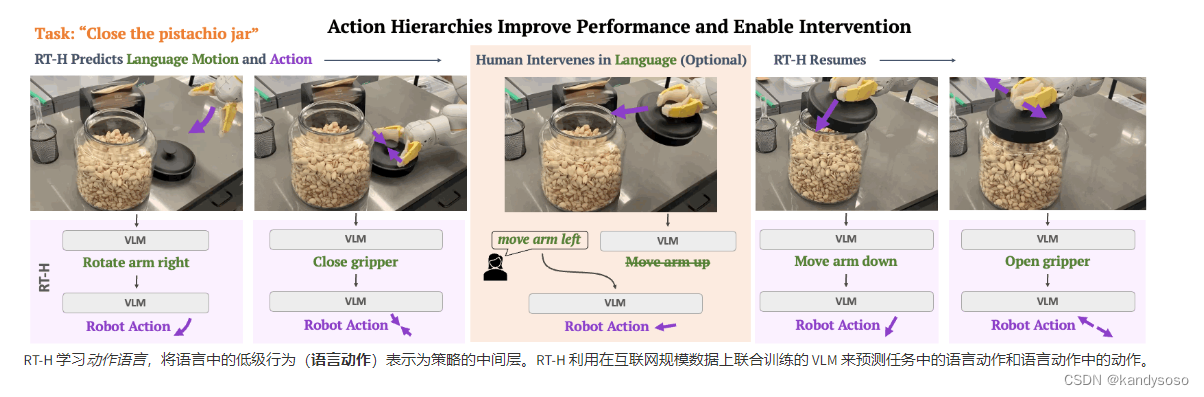
结构:















 727
727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









