







网上说liquid clustering还是实验阶段,python和scala有对应的函数,java没有,只能用sql语句来建表,尝试了两天,遇到很奇怪的情况,先上代码:
import io.delta.tables.DeltaTable;
import org.apache.spark.sql.*;
import org.apache.spark.sql.types.DataTypes;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
public class DeltaLakeCluster {
//将字符串转换成java.sql.Timestamp
public static java.sql.Timestamp strToSqlDate(String strDate, String dateFormat) {
SimpleDateFormat sf = new SimpleDateFormat(dateFormat);
Date date = null;
try {
date = sf.parse(strDate);
} catch (Exception e) {
e.printStackTrace();
}
java.sql.Timestamp dateSQL = new java.sql.Timestamp(date.getTime());
return dateSQL;
}
public static void main(String[] args) {
SparkSession spark = SparkSession.builder()
.master("local[*]")
.appName("delta_lake")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.databricks.delta.autoCompact.enabled", "true")
.config("spark.databricks.delta.clusteredTable.enableClusteringTablePreview", "true")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate();
String savePath="D:\\bigdata\\detla-lake-with-java\\YellowTaxi";
String tableName = "taxidb.YellowTaxis";
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
String savePath2="file:///D:\\\\bigdata\\\\detla-lake-with-java\\\\YellowTaxiCluster";
String tableName2 = "taxidb.YellowTaxisCluster";
String savePath3="D:\\bigdata\\detla-lake-with-java\\YellowTaxi";
spark.sql("CREATE DATABASE IF NOT EXISTS taxidb");
//定义表
DeltaTable.createIfNotExists(spark)
.tableName(tableName)
.addColumn("RideId","INT")
.addColumn("VendorId","INT")
.addColumn("PickupTime","TIMESTAMP")
.addColumn("DropTime","TIMESTAMP")
.location(savePath)
.execute();
//建表只能运行一次,没有办法判断是否存在
String sqlText="CREATE TABLE IF NOT EXISTS "+tableName2+" USING DELTA CLUSTER BY (VendorId) LOCATION '"+savePath2+"' AS SELECT * FROM "+tableName+"";
spark.sql(sqlText);
DeltaTable deltaTable = DeltaTable.forPath(spark,savePath2);
deltaTable.detail().show(false);
var schema=deltaTable.toDF().schema();
//插入数据
List<Row> list = new ArrayList<Row>();
list.add(RowFactory.create(-1,-1,strToSqlDate("2023-01-01 10:00:00","yyyy-MM-dd HH:mm:ss"),strToSqlDate("2023-01-01 10:00:00","yyyy-MM-dd HH:mm:ss")));
var yellowTaxipDF=spark.createDataFrame(list,schema);//建立需要新增数据并转换成dataframe
System.out.println("插入数据,开始时间"+ sdf.format(new Date()));
yellowTaxipDF.write().format("delta").mode(SaveMode.Append).saveAsTable(tableName);
System.out.println("插入数据,结束时间"+ sdf.format(new Date()));
System.out.println("插入后数据");
deltaTable.toDF().select("*").where("RideId=-1").show(false);
//更新数据
System.out.println("更新前数据");
deltaTable.toDF().select("*").where("RideId=-1").show(false);
System.out.println("更新数据,开始时间"+ sdf.format(new Date()));
deltaTable.update(
functions.col("RideId").equalTo("-1"),
new HashMap<String, Column>() {{
put("PickupTime", functions.lit("2023-11-01 10:00:00").cast(DataTypes.TimestampType));
}}
);
System.out.println("更新数据,结束时间"+ sdf.format(new Date()));
System.out.println("更新后数据");
deltaTable.toDF().select("*").where("RideId=-1").show(false);
//删除数据
System.out.println("删除数据,开始时间"+ sdf.format(new Date()));
deltaTable.delete("RideId=1");
System.out.println("删除数据,结束时间"+ sdf.format(new Date()));
deltaTable.toDF().select("*").where("RideId=1").show(false);
//查询数据
System.out.println("不分区表查询数据,开始时间"+ sdf.format(new Date()));
spark.read().format("delta").load(savePath3).where("VendorId==4 and RideId==859744").show(false);
System.out.println("不分区表查询数据,结束时间" + sdf.format(new Date()));
System.out.println("分类表查询数据,开始时间"+ sdf.format(new Date()));
spark.read().format("delta").load(savePath2).where("VendorId==4 and RideId==859744").show(false);
System.out.println("分类表查询数据,结束时间" + sdf.format(new Date()));
}
}
第一个遇到的情况,不能像之前那样逐列定义表,即使用sql语句也不行,一定要从另外一个表select数据才能建表成功,具体见代码中sqlText定义。
第二个遇到的情况,判断表是否存在不生效,所以建表的sql运行完第一次后要注释掉否则就会报错。
最终运行结果: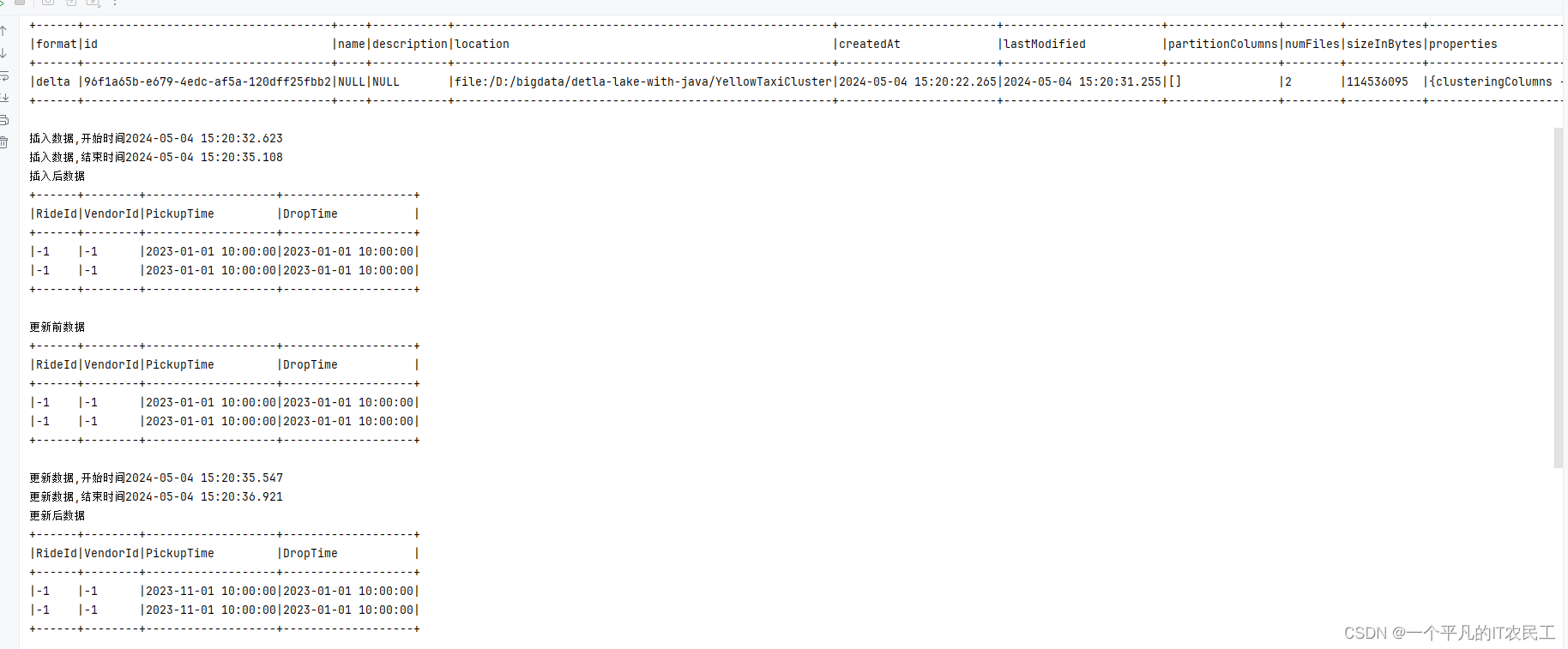
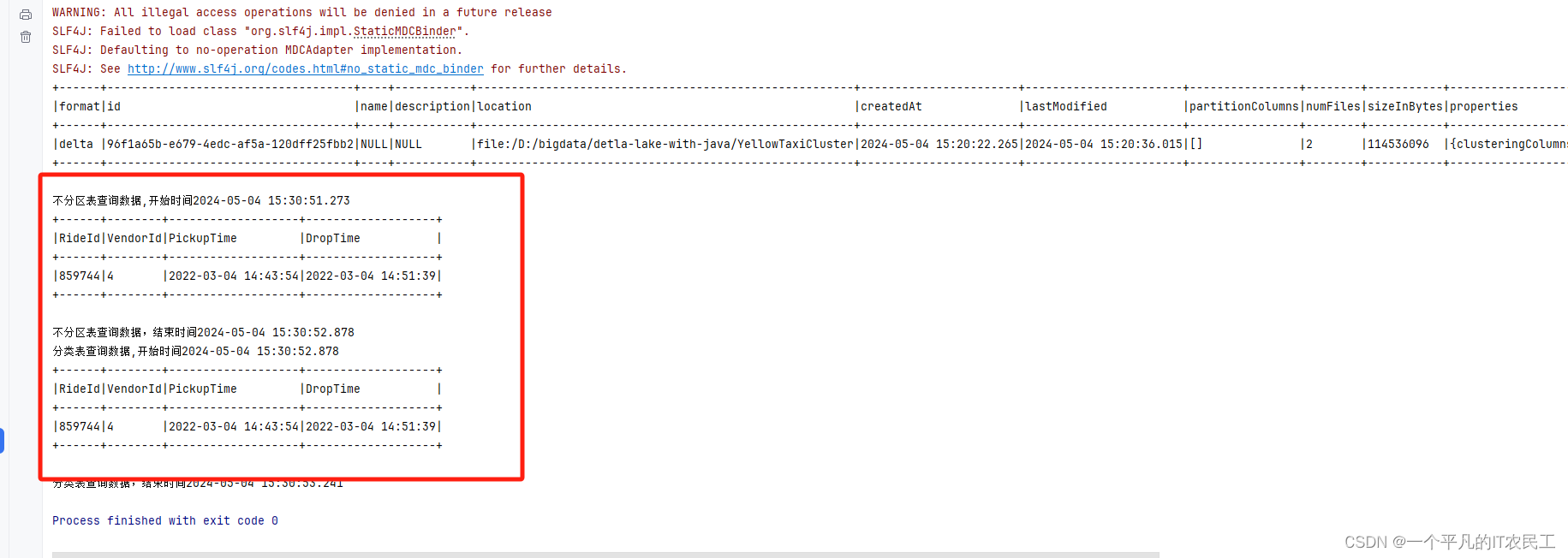
比较一下查询效率,好像没有什么区别,也不知道是不是我的代码有问题,还是本身还是实验阶段。先记录下来,后面继续跟进学习。















 557
557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









