









 本文介绍了在资源有限的设备上,如何通过无痛涨点技术提高轻量级AI模型的性能。重点讨论了SWA(Stochastic Weight Averaging)技术,它通过对训练过程中的多个模型权重进行平均,从而提升模型的泛化能力。在CenterNet检测模型上进行实验,通过对6个不同阶段模型的权重平均,成功将mAP从0.6799提升到0.695,实现了约1.5个百分点的精度提升。
本文介绍了在资源有限的设备上,如何通过无痛涨点技术提高轻量级AI模型的性能。重点讨论了SWA(Stochastic Weight Averaging)技术,它通过对训练过程中的多个模型权重进行平均,从而提升模型的泛化能力。在CenterNet检测模型上进行实验,通过对6个不同阶段模型的权重平均,成功将mAP从0.6799提升到0.695,实现了约1.5个百分点的精度提升。
1. 为什么要对模型进行无痛涨点
在计算资源受限制的移动设备上,算法工程师们只能设计轻量级的AI模型来满足实时性,然而轻量级的模型精度往往都会偏低,这就需要各种无痛涨点技术。无痛涨点技术就是在前向推理时间一定的前提下,能够提升模型效果的技术。常见的无痛涨点技术有:数据增广,损失函数的优化,训练手段的改进等等。本篇要讲的无痛涨点技术是SWA Object Detection论文里提出来的方法,做法很简单,将多个中间模型的权重进行平均,即可得到我们想要的模型。
2. SWA 原理
简单来说,SWA就是对训练过程中的多个权重模型进行平均,以提升模型的泛化性。记训练过程第个epoch的中间模型为
,一般情况下,我们会选择训练过程中最后一个epoch的模型或者在验证集上效果最好的一个模型作为最终模型。但SWA在最后采用合适的固定学习速率或者周期式学习率额外训练一段时间,取多个权重模型的平均值作为最终模型,计算公式如下:
SWA的具体做法如下图(a)所示,前75%的时间使用标准的衰减学习率策略训练,然后剩余25%设置一个合理的固定学习率进行训练,最后平均第二阶段每个epoch的权重。如下图b所示,也可以在每个epoch采用周期式的学习率策略来训练。
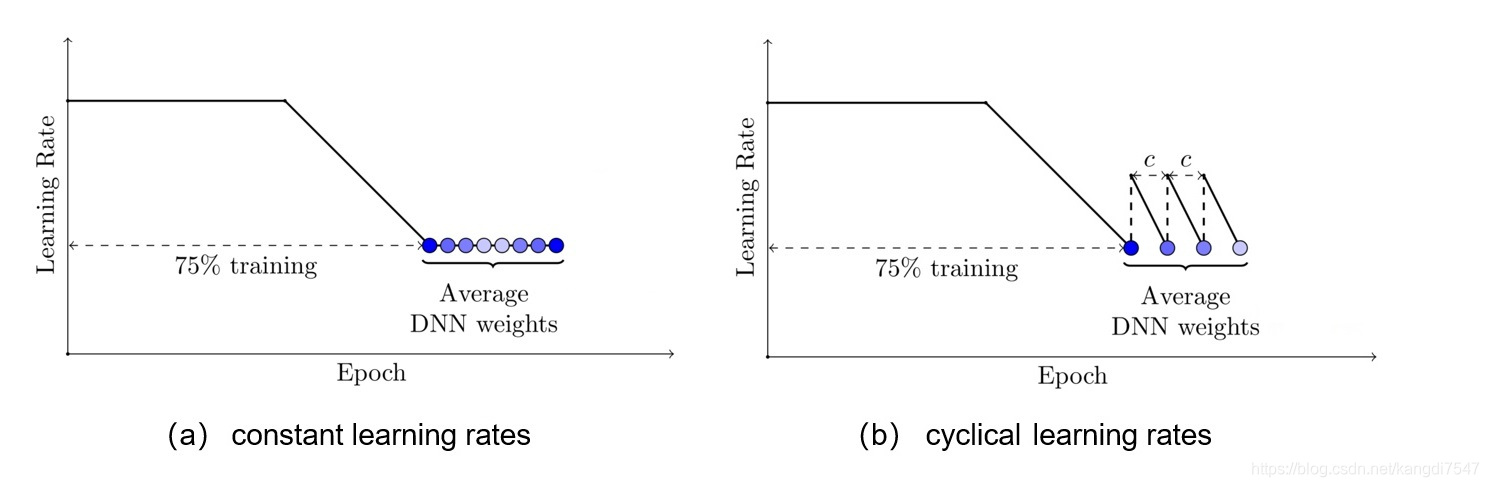
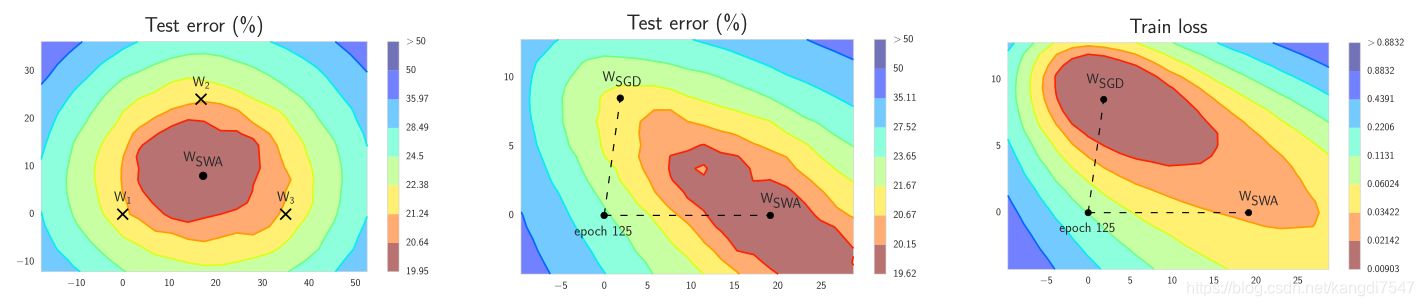
那么SWA为什么有效呢,论文也给了简单的解释,由于模型的参数属于高维空间,SGD训练的模型往往收敛到最优解的边界区域,如下图a所示,模型,
和
都落在了边缘位置,但是平均它们可以接近最优解。SWA后面采用固定学习率或者周期式学习率来寻找更多的次优解,最后平均接近最优解。图b和c说的是,训练误差和测试误差往往不对齐,也就是所说的模型泛化能力,那么平均的话是可以提升模型泛化性的。
3. 在CenterNet检测模型上进行效果测试
本人用caffe训练了一个CenterNet检测模型,用于检测车辆和行人的。采用的是余弦衰减学习率策略+Adam优化器,跑了200个epoch(CenterNet收敛好慢啊~)。
取了最后在验证集上效果较好的6个模型,这几个模型的mAP分别为:
| caffemodel 名称 | mAP |
| centernet_resnet18_fpn_yuv_12cls_iter_1625000.caffemodel | 0.6786 |
| centernet_resnet18_fpn_yuv_12cls_iter_1685000.caffemodel | 0.6788 |
| centernet_resnet18_fpn_yuv_12cls_iter_1765000.caffemodel | 0.6791 |
| centernet_resnet18_fpn_yuv_12cls_iter_1775000.caffemodel | 0.6790 |
| centernet_resnet18_fpn_yuv_12cls_iter_1815000.caffemodel | 0.6735 |
| centernet_resnet18_fpn_yuv_12cls_iter_1900000.caffemodel | 0.6799 |
利用python脚本对这6个模型进行权重平均,得到一个新的模型,新的模型的mAP为 0.695,而参与算平均的模型中最高的mAP为0.6799,提升了约1.5个百分点。
给论文原作者比个赞👍~~
如有问题,欢迎交流!!!
附上脚本代码
脚本为python代码,需要caffe的python接口:
import os
import caffe
def model_combine(model_path, weight_dir, save_weight_path):
weight_name_list = os.listdir(weight_dir)
net_list = []
net_dst = caffe.Net(model_path, caffe.TEST)
#加载目录下所有的模型
for weight_name in weight_name_list:
weight_path = weight_dir + '/' + weight_name
caffe.set_mode_cpu()
net_src = caffe.Net(model_path, weight_path, caffe.TEST)
net_list.append(net_src)
#用第0个net初始化net_dst
for key in net_src.params.keys():
for i in range(len(net_src.params[key])):
net_dst.params[key][i].data[:] = net_list[0].params[key][i].data[:]
for key in net_dst.params.keys():
for i in range(len(net_dst.params[key])):
for idx in range(1, len(net_list)):
net_dst.params[key][i].data[:] = net_dst.params[key][i].data[:] + net_list[idx].params[key][i].data[:]
#求平均
net_dst.params[key][i].data[:] = net_dst.params[key][i].data[:] / len(net_list)
net_dst.save(save_weight_path)
def main():
#caffe模型的deploy文件
model_path = 'deploy.prototxt'
#需要合并的caffemodel所在目录
weight_dir = 'caffemodel/'
#存放生成的caffemodel路径
save_weightl_path = 'centernet_resnet18_fpn_yuv_12cls.caffemodel'
model_combine(model_path, weight_dir, save_weightl_path)
if __name__ == '__main__':
main()
脚本下载地址(caffe版):
https://download.csdn.net/download/kangdi7547/19031737
也上传下处理pytorch模型的脚本:
https://download.csdn.net/download/kangdi7547/19031847
参考文献:
[2] Averaging Weights Leads to Wider Optima and Better Generalization
[3] https://zhuanlan.zhihu.com/p/341190337



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











