






Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos学习笔记

motivation:
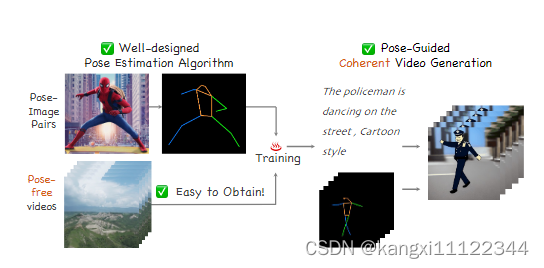
生成文本可编辑和姿势可控的视频
缺乏具有成对video-pose captions(视频姿势字幕)和generative prior models for videos(视频生成先验模型)的综合数据集。
contribution:
利用容易获得的数据集:image pose pair,pose-free video,预训练的T2I模型,进行两阶段训练,生成pose-controllable character videos(姿势可控的视频)
method
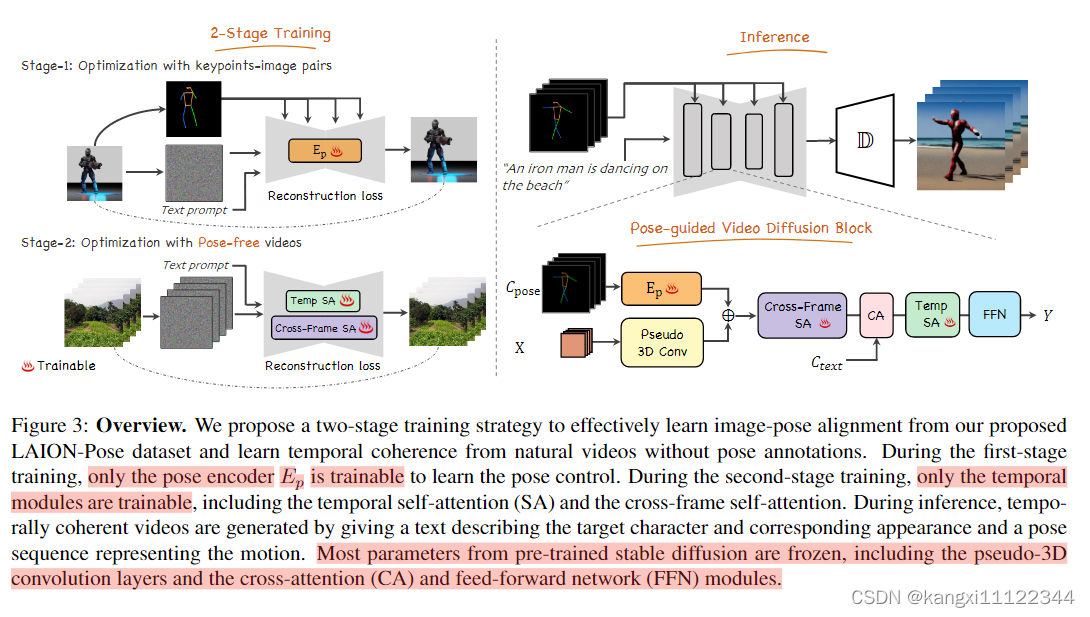 第一阶段
第一阶段
训练pose-controllable text-to-image models(姿势可控的文本到图像模型)
用MMpose提取LAION中的human skeleton images(人体骨骼图像),形成image-text-pose dataset(有图像有文本有pose的数据集)LAION-Pose
利用多个 3D 卷积层作为姿势编码器并将它们插入到 U-Net 的每个块中
通过残差连接将姿势信息注入到U-Net模型的每一层(不是直接通道维度连接)
只有pose encoder可以训练
第二阶段
在无姿态视频数据集HDVLIA上进一步微调第一阶段模型。
利用T2I先验,预训练的 U-Net 的第一个卷积层膨胀为 1 × 3 × 3 卷积核,加入temporal attention和cross frame attention
experiments

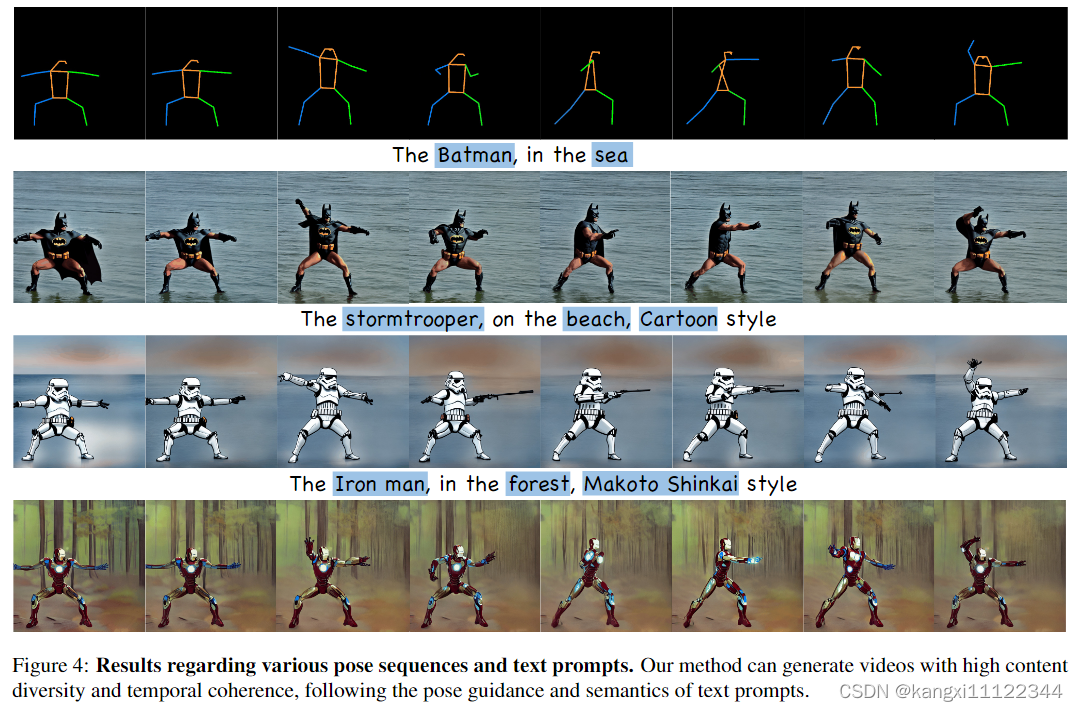 不同风格转换
不同风格转换
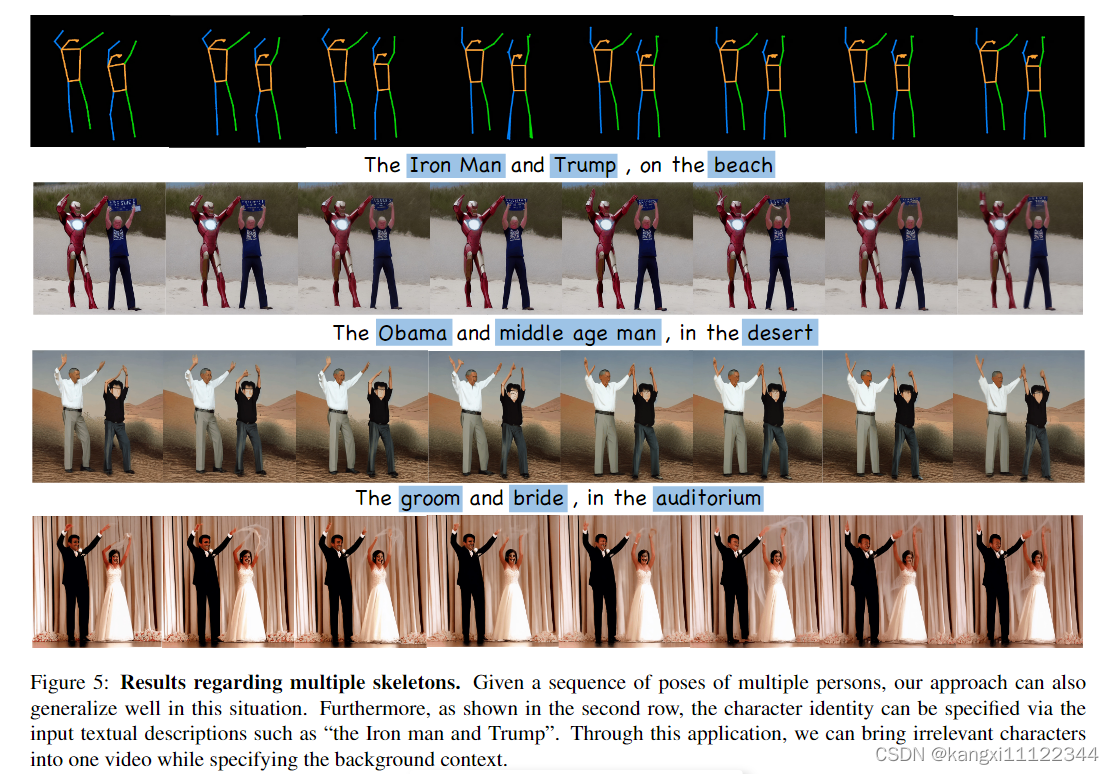 multiple skeletons转换
multiple skeletons转换


与其他方法的比较,保持生成的外观和背景一致

ablation study:pose条件输入方法:
第一行:通道维度链接
第二行:单层卷积
第三行:多层卷积


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









