






Implicit Diffusion Models for Continuous Super-Resolution学习笔记

CVPR 2023
motivation:
- 目前的SR方法通常存在过平滑和伪影,且大多数只使用固定放大倍率的工作。
contribution:
- IDM在统一的端到端框架中集成了隐式神经表示和去噪扩散模型,增强 SR 图像的高保真细节。
- 计了一种尺度自适应调节机制,动态调整来自 LR 特征的真实信息与扩散过程中生成的精细细节的比率。
method
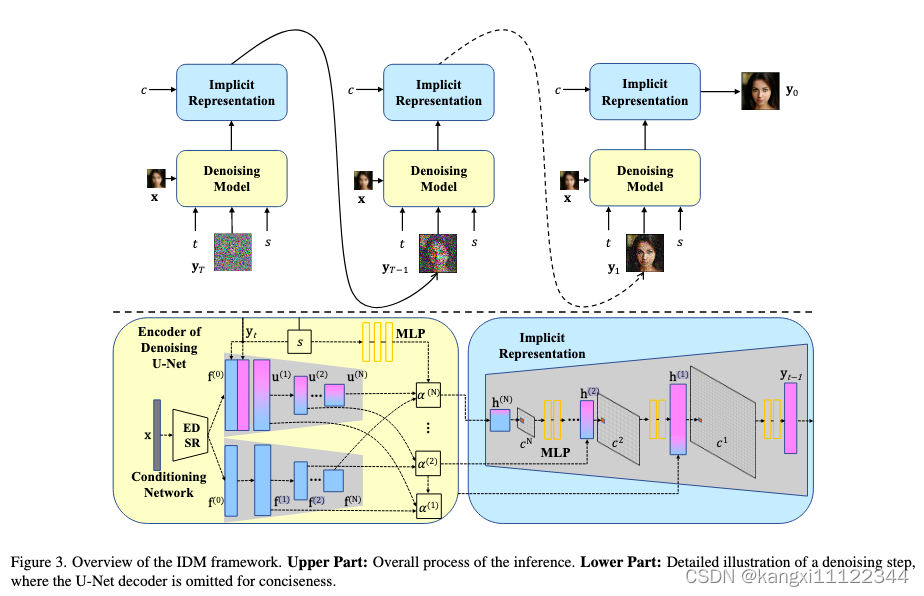
集成了Implicit Neural Representation(隐式神经表示)和去噪扩散模型
低分辨率图像x通过EDSR提取特征,将
f
(
0
)
f^{(0)}
f(0)和
y
t
y_t
yt连接起来,并将结果输入到U-Net中进行初步条件指导。
f
(
0
)
f^{(0)}
f(0)同时传入CNN
f
(
i
)
=
C
o
n
v
(
f
(
i
−
1
)
)
,
(
4
)
\mathbf{f}^{(i)}=\mathbf{Conv}\left(\mathbf{f}^{(i-1)}\right),\quad(4)
f(i)=Conv(f(i−1)),(4)
Conv 表示具有双线性滤波下采样操作的卷积层和leaky ReLU
Scaling Factor Modulation(比例因子调制)
引入了一个比例因子s作为扩散过程的条件,目的:实现连续分辨率的放大。
首先定义一个区间 (1, M ),其中 M 是最大放大率,并在训练期间从区间中随机选择。
做法:将 s 映射到一组缩放向量
α
=
{
α
1
(
1
)
,
α
2
(
1
)
,
…
,
α
1
(
i
)
,
α
2
(
i
)
,
…
,
α
1
(
N
)
,
α
2
(
N
)
}
\alpha = \left\{\alpha_{1}^{(1)},\alpha_{2}^{(1)},\ldots,\alpha_{1}^{(i)},\alpha_{2}^{(i)},\ldots,\alpha_{1}^{(N)},\alpha_{2}^{(N)}\right\}
α={α1(1),α2(1),…,α1(i),α2(i),…,α1(N),α2(N)}
α = R e s h a p e ( M L P ( s ) ) , ( 5 ) α ˉ 1 ( i ) = ∣ α 1 ( i ) ∣ α 1 ( i ) 2 + α 2 ( i ) 2 + δ , ( 6 ) o ‾ i 2 ( i ) = ∣ α 2 ( i ) ∣ α 1 ( i ) 2 + α 2 ( i ) 2 + δ , ( 7 ) h ( i ) = α ˉ 1 ( i ) ⋅ f ( i ) + α ˉ 2 ( i ) ⋅ C o n c a t ( u u p ( i ) , u d o w n ( i ) ) , ( 8 ) \begin{aligned} \alpha=Reshape(\mathrm{MLP}(s)),& \left(5\right) \\ \bar{\alpha}_{1}^{(} i)=\frac{\left|\alpha_{1}^{(i)}\right|}{\sqrt{\alpha_{1}^{(i)^{2}}+\alpha_{2}^{(i)^{2}}+\delta}}, & (6) \\ \overline{o} i_{2}^{(i)}=\frac{\left|\alpha_{2}^{(i)}\right|}{\sqrt{\alpha_{1}^{(i)^{2}}+\alpha_{2}^{(i)^{2}}+\delta}}, & \left(7\right) \\ \mathbf{h}^{(i)}=\bar{\alpha}_{1}^{(i)}\cdot\mathbf{f}^{(i)}+\bar{\alpha}_{2}^{(i)}\cdot\mathbf{Concat}\left(\mathbf{u}_{\mathrm{up}}^{(i)},\mathbf{u}_{\mathrm{down}}^{(i)}\right),& \left(8\right) \end{aligned} α=Reshape(MLP(s)),αˉ1(i)=α1(i)2+α2(i)2+δ α1(i) ,oi2(i)=α1(i)2+α2(i)2+δ α2(i) ,h(i)=αˉ1(i)⋅f(i)+αˉ2(i)⋅Concat(uup(i),udown(i)),(5)(6)(7)(8)
u u p ( i ) \mathbf{u}_{\mathrm{up}}^{(i)} uup(i), u d o w n ( i ) \mathbf{u}_{\mathrm{down}}^{(i)} udown(i)分别指U-Net Decoder和Encoder的feature map
Implicit Neural Representation(隐式神经表示)
解决问题:
流行的 SR 方法通常受到复杂的级联管道或两阶段训练策略(以此实现连续分辨率)
做法:
将coordinate-based(基于坐标)的MLP插入到U-Net架构的上采样中,以参数化隐式神经表示
c:多分辨率特征的连续坐标,利用比例因子s从去噪网络中获得
u
u
p
(
i
)
=
D
i
(
h
^
(
i
+
1
)
,
c
(
i
)
−
c
^
(
i
+
1
)
)
,
(
9
)
\mathbf{u}_{\mathrm{up}}^{(i)}=D_i\left(\hat{\mathbf{h}}^{(i+1)},c^{(i)}-\hat{c}^{(i+1)}\right),\quad(9)
uup(i)=Di(h^(i+1),c(i)−c^(i+1)),(9)
experiments
















 9075
9075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









