







学习用Python处理Excel
之前建模的时候都是C++玩的(另外才明白上次我套模板做分类肯定是overfitting了,不然正确率就40%左右,还不如反向分类呢)
首先,新建一个Excel

随意存几个数据,因为很懒,随意命名为noteone,存在E盘,只有Sheet1(注意区分大小写,不然打开的时候会报错),然后存了几个没啥意思的数据做测试:
| sequence number | name | price | number | left | fav |
| 1 | Apple | 2 | 5 | 1 | 2 |
| 2 | banana | 1 | 20 | 1 | 3 |
| 3 | orange | 3 | 50 | 1 | 2 |
| 4 | chocolate | 20 | 10 | 1 | 3 |
| 5 | candy | 1 | 100 | 1 | 3 |
准备工作
首先要安装Python,然后要配环境等等。
因为懒得装太多了,所以继续用visual studio:
https://blog.csdn.net/qq_44296347/article/details/89847984
然后参考这个,建立项目和文件:
https://blog.csdn.net/qq_44296347/article/details/89851819
然后win+r打开,输入cmd,点击确认。安装xlrd模块(复制粘贴回车):
python -m pip install xlrd
其他模块也如法炮制,python -m pip install 模块名
读取数据
参考https://www.jianshu.com/p/7546f4bd2b8a
https://blog.csdn.net/wangkai_123456/article/details/50457284
https://www.cnblogs.com/tester-go/p/7778237.html
https://www.php.cn/python-tutorials-424821.html
读取某一张表
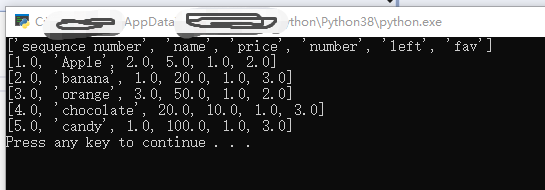
如下代码表示按行读取。
第一行引入xlrd模块
第二行打开Excel文件,存在book(不用一定叫book,我改成books也一样work,但是要记得下面一行的book也要替换)
第三行是读取Excel文件里的某一张表,按表格的名字读取
下面的for循环就是输出所有的行(sheet.nrows就是看有几行)
import xlrd
book=xlrd.open_workbook(r'E:noteone.xlsx')
sheet=book.sheet_by_name('Sheet1')
for i in range(sheet.nrows):
print(sheet.row_values(i))执行结果:
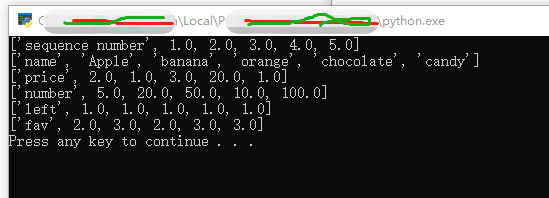
同理,按列读取也完全work,只要把行的row改成列的col就可以了。代码如下:
import xlrd
book=xlrd.open_workbook(r'E:noteone.xlsx')
sheet=book.sheet_by_name('Sheet1')
for i in range(sheet.ncols):
print(sheet.col_values(i))执行结果:
另外除了
book.sheet_by_name这种写法,还可以:
book.sheet_by_index为了说明问题我有添加了Sheet2:
| sequence number | name | salary | fine | final |
| 1 | Tom | 2000 | 10 | 1990 |
| 2 | Mary | 2125 | 15 | 2110 |
| 3 | Ted | 2136 | 35 | 2101 |
| 4 | Jane | 2500 | 320 | 2180 |
| 5 | Andy | 2231 | 100 | 2131 |
| 6 | Tony | 2451 | 0 | 2451 |
| 7 | Bill | 9000 | 500 | 8500 |
| 8 | Lily | 5000 | 160 | 4840 |
代码如下:
import xlrd
book=xlrd.open_workbook(r'E:noteone.xlsx')
sheet=book.sheet_by_index(1)
nrows=sheet.nrows
for i in range(nrows):
print(sheet.row_values(i))执行结果:
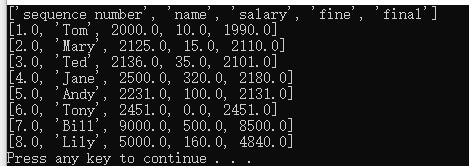
很明显,索引是1的是第二张表,还是按行读取。
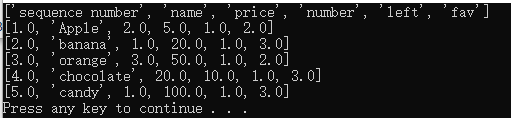
如果把sheet=book.sheet_by_index(1)改成sheet=book.sheet_by_index(0),结果就是在准备阶段准备到那张表了,如下:
读取某一张表格的一部分
读取一行、一列、某个单元格
import xlrd
book=xlrd.open_workbook(r'E:noteone.xlsx')
sheet=book.sheet_by_index(1)
#行数、列数
nrows=sheet.nrows
ncols=sheet.ncols
#第2行、第3列、第4行第5列单元格
rowvalue=sheet.row_values(1)
colvalue=sheet.col_values(2)
cellvalue=sheet.cell(3,4).value
print(rowvalue)
print(colvalue)
print(cellvalue)执行结果:

需要注意索引都从0开始计数
pandas读取数据
import pandas as pd
all_data = pd.read_excel('E:noteone.xlsx')
print(all_data.info())执行结果:

写入数据
参考:https://www.php.cn/python-tutorials-424821.html
首先需要装一个xlwt模块
打开cmd,粘贴:python -m pip install xlwt
写一个单元格
import xlwt
excel_w=xlwt.Workbook()
sheet_w=excel_w.add_sheet('TestWriteSheet')
sheet_w.write(2,2,'test if it works')
excel_w.save('excelwriting.xls')执行结果:
![]()


注意路径。
另外不知道为什么如果保存后缀名为——.xlsx就会报错:

反复执行也没有关系,就相当于是该数据了。
据说没有直接插入行,或者写入行当方法,但是可以自己写,参考:
https://zhidao.baidu.com/question/2010435244065866508.html
https://blog.csdn.net/qq_33733970/article/details/106188141
https://blog.csdn.net/zhouz92/article/details/106857122
调用公式
参考:https://blog.csdn.net/dongyu1703/article/details/82291747
https://www.cnblogs.com/BlueSkyyj/p/7571787.html
首先要安装模块openpyxl
打开cmd,粘贴:python -m pip install openpyxl
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet['A1'] = 200
sheet['B1'] = 300
sheet['C1'] = '=SUM(A1:B1)'
wb.save('excelwriting.xlsx')执行结果:


要注意不能用xls后缀名,不然打开表格的时候会报错:
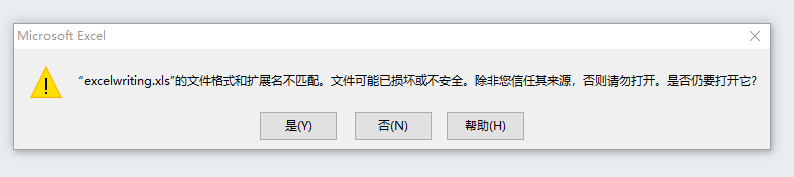
openpyxl(可读写excel表)专门处理Excel2007及以上版本产生的xlsx文件,xls和xlsx之间转换容易 注意:如果文字编码是“gb2312” 读取后就会显示乱码,请先转成Unicode。
——https://www.cnblogs.com/BlueSkyyj/p/7571787.html
点击是,打开的效果和上面打开的表格一样。
再测试一下别的函数,如最大值MAX()
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet['A1'] = 200
sheet['B1'] = 300
sheet['C1'] = '=MAX(A1:B1)'
wb.save('excelwriting.xlsx')执行结果:

能看到C1单元格里确确实实是公式
绘制图表
非Excel画图
因为种种原因,昨天装了matplotlib(参考:https://blog.csdn.net/zzx2016zzx/article/details/83099583),所以顺便记录一下
参考http://gis4g.pku.edu.cn/matplotlib-10-mins/
import matplotlib.pyplot
import numpy
x = numpy.linspace(0, 2 * numpy.pi, 50)
matplotlib.pyplot.plot(x, numpy.sin(x), 'r-o',
x, numpy.cos(x), 'g--')
matplotlib.pyplot.show()执行结果:

另外,如果前面引入模块的时候这样写:
import matplotlib.pyplot as plt
import numpy as np就可以写简单点(有点类似C++里的#define LL long long )
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 2 * np.pi, 50)
plt.plot(x, np.sin(x), 'r-o',
x, np.cos(x), 'g--')
plt.show()执行结果一样
Excel图表绘制
刚发现Excel画图也要用matplotlib
……
参考:
https://www.cnblogs.com/czz0508/p/10458425.html
https://blog.csdn.net/fei347795790/article/details/90641817
https://www.cnblogs.com/zhubinglong/p/7069318.html
为方便查看,再附录一下测试使用的表格:
| sequence number | name | salary | fine | final |
| 1 | Tom | 2000 | 10 | 1990 |
| 2 | Mary | 2125 | 15 | 2110 |
| 3 | Ted | 2136 | 35 | 2101 |
| 4 | Jane | 2500 | 320 | 2180 |
| 5 | Andy | 2231 | 100 | 2131 |
| 6 | Tony | 2451 | 0 | 2451 |
| 7 | Bill | 9000 | 500 | 8500 |
| 8 | Lily | 5000 | 160 | 4840 |
代码:
import numpy as np
import matplotlib.pyplot as plt
import xlrd
# 打开一个workbook
workbook = xlrd.open_workbook(r'E:noteone.xlsx')
# 抓取所有sheet页的名称
worksheets = workbook.sheet_names()
print('worksheets is %s' % worksheets)
# 打开Sheet2,并命名为mySheet
mySheet = workbook.sheet_by_name(u'Sheet2')
# get datas
# 读取第三列数据,并打印
salary = mySheet.col_values(2)
print(salary)
# 读取姓名列
name = mySheet.col(1)
print('coworker',name)
name = [x.value for x in name]
print('coworker_name',name)
# drop the 1st line of the data, which is the name of the data.
salary.pop(0)
name.pop(0)
# declare a figure object to plot
fig = plt.figure(1)
# plot pressure
plt.plot(name,salary)
plt.title('total salary')
plt.xlabel('name')
plt.ylabel('salary')
plt.xticks(range(len(name)),name)
plt.show()
一开始我参考的博客里有两句,我直接改过来还是没明白啥意思,如下:
# 读取姓名列
name = mySheet.col(1)
print('coworker',name)
name = [x.value for x in name]
print('coworker_name',name)感觉没有这个必要,就缩减了一下,代码改为:
import numpy as np
import matplotlib.pyplot as plt
import xlrd
# 打开一个workbook
workbook = xlrd.open_workbook(r'E:noteone.xlsx')
# 抓取所有sheet页的名称
worksheets = workbook.sheet_names()
print('worksheets is %s' % worksheets)
# 打开Sheet2,并命名为mySheet
mySheet = workbook.sheet_by_name(u'Sheet2')
# get datas
# 读取第三列数据,并打印
salary = mySheet.col_values(2)
print(salary)
# 读取姓名列
name = mySheet.col_values(1)
print('coworker',name)
# drop the 1st line of the data, which is the name of the data.
salary.pop(0)
name.pop(0)
# declare a figure object to plot
fig = plt.figure(1)
# plot pressure
plt.plot(name,salary)
plt.title('total salary')
plt.xlabel('name')
plt.ylabel('salary')
plt.xticks(range(len(name)),name)
plt.show()执行结果:

不影响作图。直接删了后两行会报错,应该是直接读取列的时候读的是字符串(?)我猜的

因为按照参考博客直接写出的代码(第一个)输出的红框框看起来像键值对。删改后的代码(第二个)就直接去掉这一行,省去后面循环读出的部分。
另外还有很多图,参考:
https://blog.csdn.net/fei347795790/article/details/90641817
# plot pressure
plt.bar(name,salary)把之前的plt.plot(name,salary)改成上述代码,得到条形图,执行结果如下:

把所有数据放上来:
import numpy as np
import matplotlib.pyplot as plt
import xlrd
# 打开一个workbook
workbook = xlrd.open_workbook(r'E:noteone.xlsx')
# 抓取所有sheet页的名称
worksheets = workbook.sheet_names()
print('worksheets is %s' % worksheets)
# 打开Sheet2,并命名为mySheet
mySheet = workbook.sheet_by_name(u'Sheet2')
# get datas
# 读取第三列数据(工资),并打印
salary = mySheet.col_values(2)
print(salary)
# 读取姓名列
name = mySheet.col_values(1)
print('coworker',name)
# 读取罚款金额
fine = mySheet.col_values(3)
print('fineD',fine)
# 读取最终工资
final = mySheet.col_values(4)
print('finalSalary',final)
number= mySheet.nrows-1
number=np.arange(number)
# drop the 1st line of the data, which is the name of the data.
salary.pop(0)
fine.pop(0)
final.pop(0)
name.pop(0)
# declare a figure object to plot
fig = plt.figure(1)
bar_width=0.3
# plot pressure
plt.bar(number,salary,bar_width,color='#E6E6FA',label='intSalary')
plt.bar(number+bar_width,fine,bar_width,color='#E9967A',label='intFine')
plt.bar(number+bar_width*2,final,bar_width,color='#32CD32',label='finSalary')
plt.title('final salary')
plt.xlabel('name')
plt.ylabel('dollar')
plt.xticks(number+bar_width/3,name)
plt.legend()
plt.show()执行结果:

***********************************
补充:
这里用到了读取一共有多少行的代码:
number= mySheet.nrows-1因为这里人数是行数减1(减去表头)
举例如下:
import xlrd
# 打开一个workbook
workbook = xlrd.open_workbook(r'E:noteone.xlsx')
# 抓取所有sheet页的名称
worksheets = workbook.sheet_names()
print('worksheets is %s' % worksheets)
# 打开Sheet2,并命名为mySheet
mySheet = workbook.sheet_by_name(u'Sheet2')
nrows = mySheet.nrows
print('表格总行数',nrows)
ncols = mySheet.ncols
print('表格总列数',ncols)执行结果:

************************************
再放一个饼图的
import numpy as np
import matplotlib.pyplot as plt
import xlrd
# 打开一个workbook
workbook = xlrd.open_workbook(r'E:noteone.xlsx')
# 抓取所有sheet页的名称
worksheets = workbook.sheet_names()
print('worksheets is %s' % worksheets)
# 打开Sheet2,并命名为mySheet
mySheet = workbook.sheet_by_name('Sheet1')
# get datas
# 读取食品名单
name = mySheet.col_values(1)
print('refreshment name',name)
# 读取食品数量
number = mySheet.col_values(3)
print('number',number)
explode=(0,0.1,0,0,0)
# drop the 1st line of the data, which is the name of the data.
name.pop(0)
number.pop(0)
# declare a figure object to plot
fig = plt.figure(1)
# plot pressure
plt.pie(number,explode=explode,labels=name,autopct='%1.1f%%',shadow=True,startangle=90 )
plt.axis('equal')
plt.title('refreshment list')
plt.show()执行结果:

如下图所示,红框框中的代码是调整拿出来多少的。
懂了这就拿饼图去画pizza(大雾

筛选数据
为了做筛选做了一个大一点的表格(摘录部分,随机点的没有内涵的意思):
| UDI | name | country | 301score | 106score | 203score |
| 20201100 | AB | America | A | A | A |
| 20201101 | AB | Canada | B | A | A |
| 20201102 | AB | china | A | A | A |
| 20201103 | AB | china | A | B | A |
| 20201104 | AB | Canada | A | A | A |
| 20201105 | AB | Canada | A | A | A |
| 20201106 | AB | Canada | A | B | A |
| 20201107 | AB | china | A | A | A |
| 20201108 | AB | china | A | A | A |
| 20201109 | AB | china | A | A | A |
| 20201110 | AB | china | B | A | A |
| 20201111 | CD | America | A | A | A |
| 20201112 | CD | china | A | A | A |
| 20201113 | CD | Japan | B | A | A |
表格为成绩单。按照从左向右依次是学号(UID),姓名(name),国家(country),301课程的成绩(301score),106课程的成绩(106score),203课程的成绩(203score)
首先是用pandas打开这个表格
import pandas as pd
all_data = pd.read_excel('E:noteone.xlsx',sheet_name='Sheet3')
print(all_data.info())
print(all_data.head(300))因为我有200+行,为了能全读出来,就设置了300(如果设置100的话在第一百行就停了)
执行结果如下:

筛选出301score是B,203score是C的
代码如下:
import pandas as pd
all_data = pd.read_excel('E:noteone.xlsx',sheet_name='Sheet3')
print(all_data.info())
some = all_data[(all_data['301score'] == 'B') & (all_data['203score'] == 'C')]
print(some)执行结果:

pandas其他用法:https://pandas.pydata.org/pandas-docs/stable/
其他
一些写毕设的时候老师可能会扣的零零散散的东西
绘制图像中的字体大小
(先吐槽一句,虽然确实字体调整之后看起来会方便很多,但是……写了快四年的实验报告和各种小论文真是不堪其扰,尤其是如果投稿论文的时候对格式的要求简直令人头秃)
(再吐槽一句用labview特别容易自闭,建模的时候,写论文的时候就要一边写一边把数据表格、图像等等转格式,或者提前发给负责labview的同学写代码,简直反人类!!!而且输出的结果我觉得和用Word输出没什么区别)
为了证明确实有用,就用之前的饼图当小白鼠
参考:https://blog.csdn.net/qq_40421671/article/details/109640106
https://blog.csdn.net/u010358304/article/details/78906768
代码如下:
import numpy as np
import matplotlib.pyplot as plt
import xlrd
# 打开一个workbook
workbook = xlrd.open_workbook(r'E:noteone.xlsx')
# 抓取所有sheet页的名称
worksheets = workbook.sheet_names()
print('worksheets is %s' % worksheets)
# 打开Sheet2,并命名为mySheet
mySheet = workbook.sheet_by_name('Sheet1')
# get datas
# 读取食品名单
name = mySheet.col_values(1)
print('refreshment name',name)
# 读取食品数量
number = mySheet.col_values(3)
print('number',number)
explode=(0,0.5,0,0.3,0)
# drop the 1st line of the data, which is the name of the data.
name.pop(0)
number.pop(0)
# declare a figure object to plot
fig = plt.figure(1)
#!!!!!!!!!!这里调整了
font = {'family':'Times New Roman','weight' : 'normal','size': 39,}
#!!!!!!!!!!这里
# plot pressure
plt.pie(number,explode=explode,labels=name,autopct='%1.1f%%',shadow=True,startangle=90 )
plt.axis('equal')
plt.title('refreshment list',font)
plt.show()执行结果:

创建新Sheet
设置单元格格式、字体
参考:https://www.cnblogs.com/eternalpal/p/12900390.html
________________________________________________________________________________________
这里是更新的分割线,今天早上刚刚写完被安排的任务,在此记录几点心得
1.记录我拿来对比填充单元格背景颜色的工具:https://www.sioe.cn/yingyong/yanse-rgb-16/
2.记录一个超好用的模块,写入、公式、画图、单元格格式都可以(好像没法筛选,但是功能已经很OK了):https://xlsxwriter.readthedocs.io/index.html
3.有关筛选数据并统计个数,虽然筛选的方法多种多样,但是统计个数这个真没找到比较好的,所以就自己写了:先用pandas打开,然后筛选出来之后填到新的表格中,再利用除去表头剩下的都是数据,因此统计行数就得到筛选数据个数的方法得出结论。
4.在筛选时如果首行不是分类,而是表头(举例:)
| sequence number | name | salary | fine | final |
| 1 | Tom | 2000 | 10 | 1990 |
| 2 | Mary | 2125 | 15 | 2110 |
| 3 | Ted | 2136 | 35 | 2101 |
| 4 | Jane | 2500 | 320 | 2180 |
| 5 | Andy | 2231 | 100 | 2131 |
| 6 | Tony | 2451 | 0 | 2451 |
| 7 | Bill | 9000 | 500 | 8500 |
| 8 | Lily | 5000 | 160 | 4840 |
如果打开表格之后这样的表格没有顶格写,而是有比如xxx工资表,再合并个单元格什么的,直接筛选会报错。可以通过:
data = pd.read_excel(r"E:/codepath/processingdata.xlsx",skiprows= 3)skiprows跳过这些行,读取有效数据。
附录:
前文提到的自己写的筛选,随意马赛克了一下
E:/codepath/Target.xlsx这个就是原始数据(或者说是skiprows跳过某些行得到的有效数据)
'E:/codepath/Target1.xlsx就是筛选得到的数据(每一次筛选写入的时候都会覆盖原来的数据,如果需要保存,记住每次更改写入位置)
另外注意照这样写,每一个人都数据都被单独放进一个sheet中,所以下面计数读取的时候需要索引值index
#假设这段代码为了统计出某人的奖惩信息
#而摘取片段为了筛选出每个人获得国家级奖励的次数
#参数说明:
#name_s_筛选出每个人获得国家级奖励的信息,name1表示第一个人,
#s1表示获得的奖励是国家级的(同理省级可以是s2)
#这里name1s1的意思就是第一个人(A)获得国家级奖励的具体信息
all_data = pd.read_excel('E:/codepath/Target.xlsx',usecols = ['人名','奖励','惩罚'])
with pd.ExcelWriter('E:/codepath/Target1.xlsx') as writer:
name1s1 = all_data[(all_data['人名'] == 'A') & (all_data['奖励'] == '国家级奖励')]
name1s1.to_excel(writer,'A')
name2s1 = all_data[(all_data['人名'] == 'B') & (all_data['奖励'] == '国家级奖励')]
name2s1.to_excel(writer,'B')
name3s1 = all_data[(all_data['人名'] == 'C') & (all_data['奖励'] == '国家级奖励')]
name3s1.to_excel(writer,'C')
name4s1 = all_data[(all_data['人名'] == 'D') & (all_data['奖励'] == '国家级奖励')]
name4s1.to_excel(writer,'D')
name5s1 = all_data[(all_data['人名'] == 'E') & (all_data['奖励'] == '国家级奖励')]
name5s1.to_excel(writer,'E')
name6s1 = all_data[(all_data['人名'] == 'F') & (all_data['奖励'] == '国家级奖励')]
name6s1.to_excel(writer,'F')
name7s1 = all_data[(all_data['人名'] == 'G') & (all_data['奖励'] == '国家级奖励')]
name7s1.to_excel(writer,'G')
name8s1 = all_data[(all_data['人名'] == 'H') & (all_data['奖励'] == '国家级奖励')]
name8s1.to_excel(writer,'H')
name9s1 = all_data[(all_data['人名'] == 'I') & (all_data['奖励'] == '国家级奖励')]
name9s1.to_excel(writer,'I')
name10s1 = all_data[(all_data['人名'] == 'J') & (all_data['奖励'] == '国家级奖励')]
name10s1.to_excel(writer,'J')
name11s1 = all_data[(all_data['人名'] == 'K') & (all_data['奖励'] == '国家级奖励')]
name11s1.to_excel(writer,'K')
name12s1 = all_data[(all_data['人名'] == 'L') & (all_data['奖励'] == '国家级奖励')]
name12s1.to_excel(writer,'L')
#参数说明:
#cnt1表示第一个人
#s1还是代表国家级奖励
#这里cnt1s1的意思就是第一个人(A)获得国家级奖励的个数
book=xlrd.open_workbook(r'E:/codepath/Target1.xlsx')
sheet=book.sheet_by_index(0)
nrows=sheet.nrows
cnt1s1=nrows-1
sheet=book.sheet_by_index(1)
nrows=sheet.nrows
cnt2s1=nrows-1
sheet=book.sheet_by_index(2)
nrows=sheet.nrows
cnt3s1=nrows-1
sheet=book.sheet_by_index(3)
nrows=sheet.nrows
cnt4s1=nrows-1
sheet=book.sheet_by_index(4)
nrows=sheet.nrows
cnt5s1=nrows-1
sheet=book.sheet_by_index(5)
nrows=sheet.nrows
cnt6s1=nrows-1
sheet=book.sheet_by_index(6)
nrows=sheet.nrows
cnt7s1=nrows-1
sheet=book.sheet_by_index(7)
nrows=sheet.nrows
cnt8s1=nrows-1
sheet=book.sheet_by_index(8)
nrows=sheet.nrows
cnt9s1=nrows-1
sheet=book.sheet_by_index(9)
nrows=sheet.nrows
cnt10s1=nrows-1
sheet=book.sheet_by_index(10)
nrows=sheet.nrows
cnt11s1=nrows-1
sheet=book.sheet_by_index(11)
nrows=sheet.nrows
cnt12s1=nrows-1
记录一个文档:
https://xlsxwriter.readthedocs.io/index.html#
yyds














 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









