







Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations
Abstract
深度学习领域新颖研究想法的验证和部署通常受到某些基本原语高效计算内核的可用性限制。特别是,无法利用现有供应商库(例如cuBLAS、cuDNN)的操作面临着设备利用率不佳的风险,除非由专家编写自定义实现——通常以牺牲可移植性为代价。因此,开发新的编程抽象来以最小的性能成本指定自定义深度学习工作负载变得至关重要。
我们提出了Triton,一种以图块(tile)概念为中心的语言和编译器,即静态形状的多维子数组。我们的方法围绕:
- 基于C语言和基于LLVM的中间表示(IR),用于根据参数图块变量的操作来表达张量程序;
- 以及一组新颖的图块级优化过程,用于将这些程序编译成高效的GPU代码。
我们将演示如何使用Triton来构建矩阵乘法和卷积核的可移植实现,与手工调优的供应商库(cuBLAS/cuDNN)相当,或者高效地实现最近的研究想法,如移位卷积。
1 Introduction
深度神经网络(DNN)最近的复兴很大程度上得益于可编程并行计算设备的广泛使用[24]。特别是,多核架构(例如GPU)性能的持续改进发挥了基础性作用,使研究人员和工程师能够使用越来越多的数据来探索越来越多、越来越大的模型。这项工作得到了一系列供应商库(cuBLAS、cuDNN)的支持,旨在尽快为从业者带来最新的硬件创新。不幸的是,这些库仅支持一组有限的张量运算,将新原语的实现留给专家[13, 17, 25]。
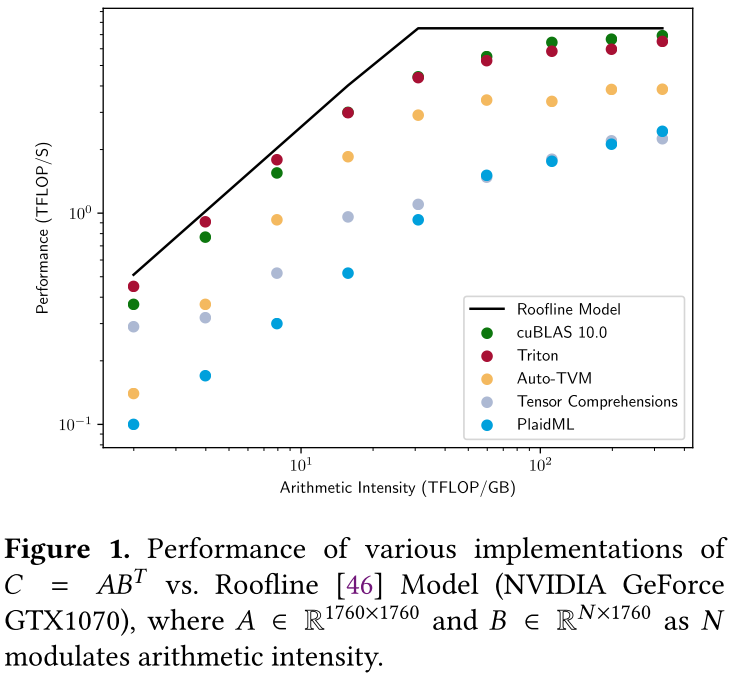
这一观察导致了基于多面体机制(例如张量理解[43])和/或循环合成技术(例如Halide[37]、TVM[10]和PlaidML[22])的DNN的各种特定领域语言(Domain-Specific Languages, DSLs)的开发。但是,虽然这些系统通常对于某些类别的问题表现良好,例如深度可分离卷积(例如MobileNet[20]),但在实践中它们通常比供应商库慢得多(参见图1),并且缺乏实现结构化稀疏模式所需的表达能力[28, 31, 47],无法在嵌套循环中使用仿射数组索引直接指定。
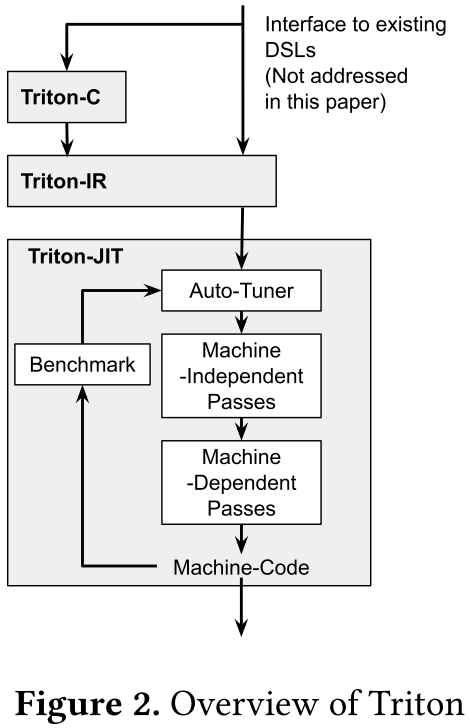
这些问题通常通过使用微内核来解决[11, 21]——即手写的图块级内在函数——但这种解决方案需要大量的体力劳动并且缺乏可移植性。尽管最近提出了几种用于图块的高级编程抽象[23, 41],但底层编译器后端仍然缺乏对图块级操作和优化的支持。为此,我们推出Triton(图2),这是一种开源的中间语言和编译器,用于指定图块程序并将其编译为高效的GPU代码。
本文的主要贡献总结如下:
-
Triton-C(第3节):一种类似C的语言,用于根据参数图块变量表达张量程序。该语言的目的是为现有的DNN转编译器(例如PlaidML、Tensor Compressive)和熟悉CUDA的程序员提供稳定的接口。Listing 1显示了与简单矩阵乘法任务相关的Triton-C源代码。

// Tile shapes are parametric and can be optimized // by compilation backends const tunable int TM = {16, 32, 64, 128} const tunable int TN = {16, 32, 64, 128} const tunable int TK = {8, 16} // C = A * B.T kernel void matmul_nt(float* a, float* b, float* c, int M, int N, int K) { // 1D tile of indices int rm[TM] = get_global_range(0); int rn[TN] = get_global_range(1); int rk[TK] = 0 ... TK; // 2D tile of pointers float* pa[TM, TK] = a + rm[:, newaxis] + rk * M; float* pb[TN, TK] = b + rn[:, newaxis] + rk * K; for (int k = K; k >= 0; k -= TK){ bool check_k[TK] = rk < k; bool check_a[TM, TK] = (rm < M)[:, newaxis] && check_k; bool check_b[TN, TK] = (rn < N)[:, newaxis] && check_k; // load tile operands float A[TM, TK] = check_a ? *pa : 0; float B[TN, TK] = check_b ? *pb : 0; // accumulate C += dot(A, trans(B)); // update pointers pa = pa + TK * M; pb = pb + TK * N; } // write-back accumulators float* pc[TM, TN] = c + rm[:, newaxis] + rn * M; bool check_c[TM, TN] = (rm < M)[:, newaxis] && (rn < N); @check_c *pc = C; } -
Triton-IR(第4节):基于LLVM的中间表示(IR),提供适合切片级程序分析、转换和优化的环境。Listing 5显示了修正线性单元(ReLU)函数的Triton-IR代码。这里,Triton-IR程序是在解析过程中直接从Triton-C构建的,但未来也可以探索从嵌入式DSL或更高级别的DNN编译器(例如TVM)自动生成。

define kernel void @relu(float* %A, i32 %M, i32 %N) { prologue: %rm = call i32<8> get_global_range(0); %rn = call i32<8> get_global_range(1); ; broadcast shapes %1 = reshape i32<8, 8> %M; %M0 = broadcast i32<8, 8> %1; %2 = reshape i32<8, 8> %N; %N0 = broadcast i32<8, 8> %2; ; broadcast global ranges %3 = reshape i32<8, 1> %rm; %rm_bc = broadcast i32<8, 8> %3; %4 = reshape i32<1, 8> %rn; %rn_bc = broadcast i32<8, 8> %4; ; compute pointer %A0 = splat float*<8, 8> %A; %5 = getelementptr %A0, %rm_bc; %6 = mul %rn_bc, %M0; %pa = getelementptr %5, %6; ; compute result %a = load %pa; %_0 = splat float<8, 8> 0; %result = max %float %a, %_0; ; write back store fp32<8, 8> %pa, %result; } -
Triton-JIT(第5节):即时(Just-In-Time, JIT)编译器和代码生成后端,用于将Triton-IR程序编译为高效的LLVM位代码。这包括:
- 一组图块级、独立于机器的通道,旨在独立于任何编译目标简化输入计算内核;
- 一组图块级机器相关通道,用于生成高效的GPU就绪LLVM-IR;
- 一个自动调节器,用于优化与上述过程相关的任何元参数。
-
Numerical Experiments(第6节):对Triton的数值评估证明了它的能力:
- 在循环神经网络和Transformer上生成与cuBLAS相当的矩阵乘法实现,并且比替代的DSL快3倍;
- 重新实现了cuDNN中用于密集卷积的
IMPLICIT_GEMM算法,而不损失性能; - 创建新颖的研究思想的有效实现,例如shift-conv[47]模块。
本文将以对现有相关文献的简要分析作为序言(第2节),并以总结和未来工作方向作为总结(第7节)。
2 Related Work
深度学习框架[1, 9, 36]和库的存在对于新型神经网络架构和算法的出现至关重要。但是,尽管线性代数编译器的分析[5, 48]和经验[6, 30]启发式方法取得了进步,这些软件仍然总是依赖于手动优化的子例程(例如cuBLAS和cuDNN)。这导致了各种DSL和DNN编译器的开发,通常基于三种不同的方法之一:
- Tensor-level IRs:XLA[16]和Glow[38]已经使用张量级IRs来使用模式匹配将张量程序转换为预定义的LLVM-IR和CUDA-C操作模板(例如,张量收缩、元素级操作等)。
- The polyhedral model:张量理解(TC)[43]和Diesel[14]使用多面体模型[18],将一个或多个DNN层参数化并自动编译成LLVM-IR和CUDA-C程序。
- Loop synthesizers:Halide[37]和TVM[10]已经使用循环合成器来将张量计算转换为可以使用用户定义(尽管可能是参数化的[11])调度手动优化的环路嵌套式。
相比之下,Triton依赖于在传统编译管道中添加图块级操作和优化。这种方法提供了:
- 较XLA和Glow更多的灵活性;
- 支持非仿射张量下标,与TC和Diesel相反;
- 自动推断可能的执行计划,否则必须手动指定到Halide或TVM。
Triton的好处是以增加编程工作为代价的——参见Listing 2,了解这些DSL中矩阵乘法的实现。
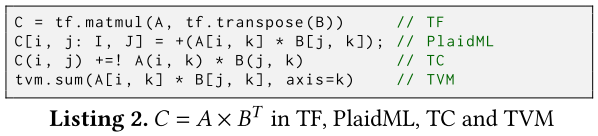
C = tf.matmul(A, tf.transpose(B)) // TF
C[i, j: I, J] = +(A[i, k] * B[j, k]); // PlaidML
C(i, j) +=! A(i, k) * B(j, k) // TC
tvm.sum(A[i, k] * B[j, k], axis=k) // TVM
3 The Triton-C Language
Triton-C的目的是为现有(和未来)DNN转编译器以及熟悉低级GPU编程的程序员提供稳定的前端。在本节中,我们将描述Triton-C的类似CUDA的语法(第3.1节)、类似Numpy[35]的语义(第3.2节)及其“单程序、多数据”(SPMD)的编程模型(第3.3节) 。
3.1 Syntax
Triton-C的语法基于ANSI C(更具体地说是CUDA-C)的语法,但进行了修改和扩展(参见Listing 3)以适应接下来两小节中描述的语义和编程模型。

// Broadcasting semantics
slice : ':' | 'newaxis'
slice_list : slice | slice_list ',' slice
slice_expr : postfix_expr | expr '[' slice_list ']'
// Range initialization
constant_range : expr '...' expr
// Intrinsics
global_range : 'get_global_range' '(' constant 'get_global_range'
dot : 'dot' '(' expr ',' expr ')'
trans : 'trans' '(' expr ',' expr ')'
intrinsic_expr : global_range | dot | trans
// Predication
predicate_expr : '@' expr
// Tile extensions for abstract declarators
abstract_decl : abstract_decl | '[' constant_list ']'
// Extensions of C expressions
expr : expr | constant_range | slice_expr | intrinsic_expr
// Extensions of C specifiers
storage_spec : storage_spec | 'kernel'
type_spec : type_spec | 'tunable'
// Extensions of C statements
statement : statement | predicate_expr statement
这些变化分为以下几类:
- Tile declarations:我们添加了用于声明多维数组的特殊语法(例如
int tile[16, 16])以强调它们与ANSI C中的嵌套数组(例如int tile[16][16])的语义差异。图块形状必须恒定,但也可以使用tunable关键字进行参数化。一维整数图块可以使用省略号来初始化(例如int range[8] = 0 ... 8)。 - Built-in function:虽然保留了常见的C语法用于逐元素数组操作(
+, -, &&, *等等),但添加了各种内置函数(dot, trans, get_global_range)以支持图块语义(第3.2.1节)和SPMD编程模型。 - Broadcasting:N维图块可以使用
newaxis关键字和常用切片语法沿任何特定轴进行广播(例如,用于堆叠列的int Broadcast [8, 8] = range[:, newaxis])。注意,在其他情况下,禁止将图块切片来检索标量或子数组。 - Predication:图块操作(第4.3节)中的基本控制流是通过使用“@”前缀来实现的。
3.2 Semantics
3.2.1 Tile Semantics
Triton-C中内置图块类型和操作(即图块语义)的存在提供了两个主要好处。首先,它通过隐藏与块内内存合并[12]、缓存管理[32]和专用硬件利用率[27]相关的重要性能细节来简化张量程序的结构。其次,它为编译器自动执行这些优化打开了大门,如第5节所述。
3.2.2 Broadcasting Semantics
Triton-C中的图块是强类型的,因为某些指令静态地要求其操作数遵守严格的形状约束。例如,除非首先适当地广播标量,否则不能将标量添加到数组中。广播语义[35]提供了一组规则来隐式执行这些转换(参见Listing 4的示例):

int a[16], b[32, 16], c[16, 1];
// a is first reshaped to [1, 16]
// and then broadcast to [32, 16]
int x_l[32, 16] = a[newaxis, :] + b;
// Same as above but implicitly
int x_2[32, 16] = a + b;
// a is first reshaped to [1, 16]
// a is broadcast to [16, 16]
// c is broadcast to [16, 16]
int y[16, 16] = a + c;
- Padding:最短操作数的形状用1进行左填充,直到两个操作数具有相同的维度。
- Broadcasting:根据需要,多次复制两个操作数的内容,直到它们的形状相同;如果无法完成此操作,则会发出错误。
3.3 Programming Model
GPU上CUDA[33]代码的执行由SPMD[4]编程模型支持,其中每个内核与所谓的启动网格中的可识别线程块相关联。Triton编程模型类似,但每个内核都是单线程的(尽管自动并行化),并且与一组因实例而异的全局范围相关联(参见图3)。

这种方法导致内核更简单,其中不存在类似CUDA的并发原语(共享内存同步、线程间通信等)。
可以使用get_global_range(axis)内置函数查询与内核关联的全局范围,以便创建指针图块,如Listing 1所示。
4 The Triton IR
Triton-IR是一种基于LLVM的中间表示(IR),其目的是提供适合图块级程序分析、转换和优化的环境。在这项工作中,Triton-IR程序是在解析过程中直接从Triton-C构建的,尽管将来它们也可以直接从更高级别的DSL生成。
Triton-IR和LLVM-IR程序共享相同的高级结构(第4.1节中回顾),但前者还包括图块级数据流(第4.2节)和控制流(第4.3节)分析所需的许多扩展。这些新颖的扩展对于执行第5节中概述的优化以及安全访问第6节中所示的任意形状的张量至关重要。
4.1 Structure
4.1.1 Modules
在最高级别,Triton-IR程序由一个或多个称为模块的基本编译单元组成。这些模块彼此独立编译,并最终由链接器聚合,链接器的作用是解析前向声明并充分合并全局定义。
每个模块本身都由函数、全局变量、常量和其他杂项符号(例如元数据、函数属性)组成。
4.1.2 Functions
Triton-IR函数定义由返回类型、名称和可能为空的参数列表组成。如果需要,可以添加额外的可见性、对齐和链接说明符。还可以指定函数属性(例如内联提示)和参数属性(例如只读、别名提示),从而允许编译器后端执行更积极的优化,例如更好地利用只读内存缓存。
该标头后面是由基本块列表组成的主体,这些基本块的相互依赖性形成了函数的控制流图(Control Flow Graph, CFG)。
4.1.3 Basic Blocks
根据定义,基本块是直线代码序列,其末尾可能仅包含所谓的终止符指令(即分支、返回)。
Triton-IR使用静态单赋值(Static Single Assignment, SSA)形式,这意味着每个基本块中的每个变量都必须是:
- 仅分配一次;
- 在使用前定义。
这样做时,每个基本块隐式定义了一个数据流图(Data-Flow Graph, DFG),其不同路径对应于程序SSA表示中的use-def链。这种形式可以直接从抽象语法树(Abstract Syntax Trees, AST)创建,如[7]所示。
4.2 Support for Tile-Level Data-Flow Analysis
4.2.1 Types
多维图块是Triton-IR中数据流分析的中心,可以使用类似于LLVM-IR中向量声明的语法进行声明。例如,i32<8, 8>是对应于
8
×
8
8 \times 8
8×8 32位整数图块的类型。请注意,Triton-IR中没有tunable关键字,因此必须在生成程序之前解析参数形状值。在我们的例子中,这是由Triton-JIT的自动调节器完成的(第5.3节)。
4.2.2 Instructions
Triton-IR引入了一组重绘指令,其目的是支持广播语义,如第3.2.2节中所述:
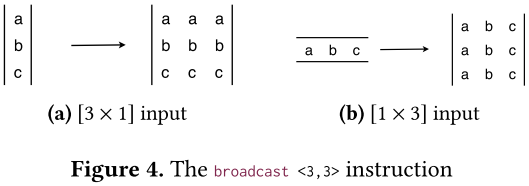
reshape指令使用来自其输入参数的数据创建指定形状的图块。这对于通过用变量填充输入形状以准备隐式或显式广播来将变量重新解释为高维数组特别有用。broadcast指令通过沿大小为1的维度根据需要多次复制其输入参数来创建指定形状的图块——如图4所示。
保留并扩展了常用的标量指令(cmp, getelementptr, add, load...),以表示对图块操作数进行逐元素操作。最后,Triton-IR还公开了用于转置(trans)和矩阵乘法(dot)的专用算术指令。
4.3 Support for Tile-Level Control-Flow Analysis
Triton-IR中存在图块级操作而产生的一个问题是图块内发散控制流的不可表达性。例如,程序可能需要部分保护图块级加载免受内存访问冲突,但这无法使用分支来实现,因为无法单独访问图块元素。

;pt[i, j], pf[i, j] = (true, false) if x[i, j] < 5
;pt[i, j], pf[i, j] = (false, true) if x[i, j] >= 5
%pt, %pf = icmpp slt %x, 5
@%pt %x1 = add &y, 1
@%pf %x2 = sub %y, 1
; merge values from different predicates
%x = psi i32<8, 8> [%pt, %x1], [%pf, %x2]
%z = mul i32<8, 8> %x, 2
我们建议通过使用谓词SSA(Predicated SSA, PSSA)形式[8]和 ψ \psi ψ函数[39]来解决这个问题。这需要向Triton-IR添加两个指令类(参见Listing 6):
cmpp指令[8]与通常的比较(cmp)指令类似,除了它们返回两个相反的谓词而不是一个。psi指令合并来自不同谓词指令流的指令。
5 The Triton-JIT Compiler
Triton-JIT的目标是通过由自动调整引擎(第5.3节)支持的一组机器独立(第5.1节)和机器相关(第5.2节)传递,将Triton-IR程序简化并编译为高效的机器代码。
5.1 Machine-Independent Passes
5.1.1 Pre-Fetching
循环内的分块级内存操作可能会出现问题,因为它们可能会导致严重的延迟,而在没有足够的独立指令的情况下,这种延迟是无法隐藏的。不过,可以通过检测循环并在必要时添加足够的预取代码来直接缓解Triton-IR中的这个问题(参见Listing 7)。

B0:
%p0 = getelementptr %1, %2
B1:
%p = phi [%p0, B0], [%p1, B1]
%x = load %p
; increment pointer
%p1 = getelementptr %p, %3
B0:
%p0 = getelementptr %1, %2
%x0 = load %p0
B1:
%p = phi [%p0, B0], [%p1, B1]
%x = phi [%x0, B0], [%p1, B1]
; increment pointer
%p1 = getelementptr %p, %3
; prefetching
%x1 = load %p
5.1.2 Tile-Level Peephole Optimization
Triton-IR中图块级操作的存在为窥视孔[29]优化器提供了新的机会。例如,对于任何图块 X X X,可以使用恒等式 X = ( X T ) T X = (X^T)^T X=(XT)T来简化转置链。我们相信,与对角线图块相关的其他代数性质在未来也可以被利用。
5.2 Machine-Dependent Passes
现在,我们提出了一组遵循图5所示高级模型的机器优化过程。
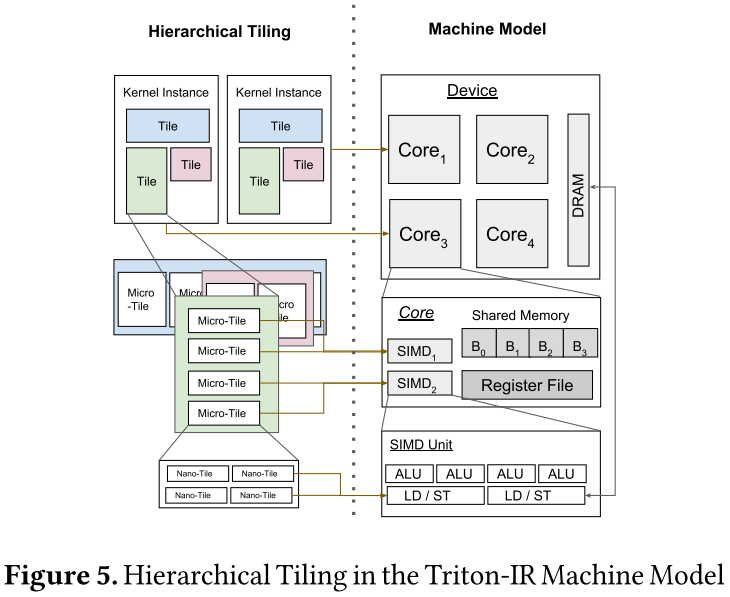
具体来说,Triton-JIT执行的优化包括:
- 分层图块;
- 内存合并;
- 共享内存分配;
- 共享内存同步。
5.2.1 Hierarchical Tiling
嵌套切片策略(见图5)旨在将图块分解为micro图块并最终分解为nano图块,以便尽可能紧密地适应机器的计算能力和内存层次结构。虽然这种技术通常用于自动调整框架[34, 40],但Triton-IR的结构使得可以自动枚举和优化任何可表达程序的有效嵌套图块配置(并且不需要多面体机器)。
5.2.2 Memory Coalescing
当相邻线程同时访问附近的内存位置时,内存访问被称为合并。这很重要,因为内存通常是从DRAM中以大块的形式检索的。
由于Triton-IR程序是单线程且自动并行化,因此我们的编译器后端能够在每个微块内部对线程进行排序,以便尽可能避免未合并的内存访问。此策略减少了加载图块列所需的内存事务数量(参见图6)。

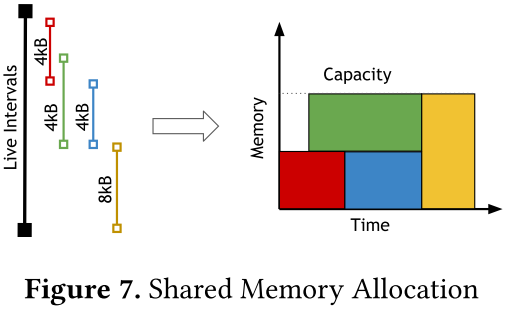
5.2.3 Shared Memory Allocation
具有高算术强度(例如dot)的图块级操作可以受益于将其操作数临时存储在快速共享内存中。共享内存分配过程的目的是确定应将图块存储到此空间的时间和位置。如图7所示,这可以通过首先计算每个感兴趣变量的生存范围,然后使用[15]中提出的线性时间存储分配算法来完成。
5.2.4 Shared Memory Synchronization
在我们的机器模型中,共享内存的读取和写入是异步的。共享内存同步过程的目标是在生成的GPU源代码中自动插入屏障,以保持程序的正确性。这是通过使用前向数据流分析和以下数据流方程来检测写后读(RAW)和读后写(WAR)危险来完成的:
i
n
s
(
R
A
W
)
=
⋃
p
∈
pred
(
s
)
o
u
t
p
(
R
A
W
)
i
n
s
(
W
A
R
)
=
⋃
p
∈
pred
(
s
)
o
u
t
p
(
W
A
R
)
o
u
t
s
(
R
A
W
)
=
{
∅
i
f
i
n
s
(
R
A
W
)
∩
r
e
a
d
(
s
)
≠
∅
(
barrier
)
i
n
s
(
R
A
W
)
∪
w
r
i
t
e
(
s
)
o
t
h
e
r
w
i
s
e
o
u
t
s
(
W
A
R
)
=
{
∅
i
f
i
n
s
(
W
A
R
)
∩
w
r
i
t
e
(
s
)
≠
∅
(
barrier
)
i
n
s
(
W
A
R
)
∪
r
e
a
d
(
s
)
o
t
h
e
r
w
i
s
e
\begin{aligned} in_s^{(RAW)} &= \bigcup_{p \in \text{pred}(s)}out_p^{(RAW)} \\ in_s^{(WAR)} &= \bigcup_{p \in \text{pred}(s)}out_p^{(WAR)} \\ out_s^{(RAW)} &= \begin{cases} \begin{array}{ll} \emptyset & \mathbf{if}\ in_s^{(RAW)} \cap read(s) \ne \emptyset\ (\text{barrier}) \\ in_s^{(RAW)} \cup write(s) & \mathbf{otherwise} \end{array} \end{cases} \\ out_s^{(WAR)} &= \begin{cases} \begin{array}{ll} \emptyset & \mathbf{if}\ in_s^{(WAR)} \cap write(s) \ne \emptyset\ (\text{barrier}) \\ in_s^{(WAR)} \cup read(s) & \mathbf{otherwise} \end{array} \end{cases} \end{aligned}
ins(RAW)ins(WAR)outs(RAW)outs(WAR)=p∈pred(s)⋃outp(RAW)=p∈pred(s)⋃outp(WAR)={∅ins(RAW)∪write(s)if ins(RAW)∩read(s)=∅ (barrier)otherwise={∅ins(WAR)∪read(s)if ins(WAR)∩write(s)=∅ (barrier)otherwise
5.3 Auto-tuner
传统的自动调优器[42, 45]通常依靠手写的参数化代码模板来在预定义的工作负载上实现良好的性能。相比之下,Triton-JIT可以通过简单地连接与上述每个优化过程相关的元参数来直接从Triton-IR程序中提取优化空间。
在这项工作中,仅考虑分层图块通道,导致每个图块每个维度的图块参数不超过3个。然后使用对:
- 32和128之间的2的幂进行穷举搜索来优化这些参数,以获取图块大小;
- micro图块尺寸为8和32;
- 1和4为nano图块尺寸。
将来可以使用更好的自动调整方法。
6 Numerical Experiments
在本节中,我们将根据深度学习文献评估Triton在各种工作负载上的性能。我们使用NVIDIA GeForce GTX1070,并将我们的系统与最新的供应商库(cuBLAS 10.0、cuDNN 7.0)以及相关编译器技术(AutoTVM、TC、PlaidML)进行比较。如果适用,我们会按照官方文档指南针对每个单独的问题大小自动调整这些DSL。
6.1 Matrix Multiplication
矩阵乘法任务的形式为: A = D × W T ( D ∈ R M × K , W ∈ R N × K ) A = D \times W^T(D \in \mathbb{R}^{M \times K}, W \in \mathbb{R}^{N \times K}) A=D×WT(D∈RM×K,W∈RN×K)是神经网络计算的核心。在这里,我们考虑了来自循环神经网络(DeepSpeech2[3])和Transformer[44]的各种任务;我们在图8中报告了它们的性能。
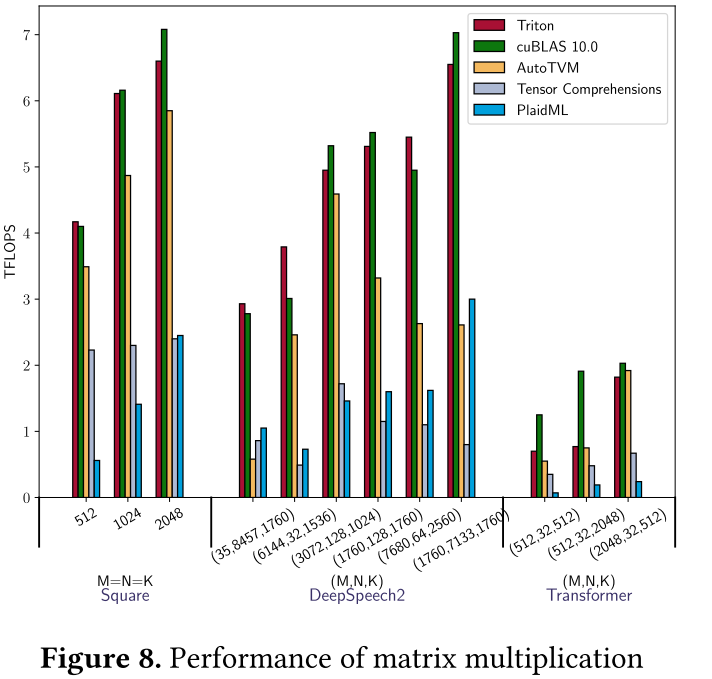
Triton和cuBLAS总体上不相上下,在某些任务上达到了设备峰值性能90%以上。然而,由于使用了3D算法[2],cuBLAS在浅层Transformer上仍然比Triton更快,该算法将深度归约分割为独立的块,以便在M和N太小时提供更多并行性。否则,现有的DSL比我们的解决方案慢2-3倍——除了当输入形状是32的倍数时的TVM(慢 < 2 < 2 <2倍)。
6.2 Convolutions
卷积神经网络(CNN)是一类重要的机器学习模型,应该得到DSL和编译器的良好支持。它们基于卷积层(图9a),其实现为矩阵乘法(图9b),这对于使用专用张量处理硬件是必要的——但现有DSL不支持。

在这里,我们对cuDNN的“IMPLICIT_GEMM”算法(第6.2.1节)的Triton重新实现进行了基准测试,并提供了第一个可用于移位卷积的融合内核(第6.2.2节)。我们使用指针增量查找表来实现这些例程,如Listing 8所示。

const tunable int TM = {16, 32, 64, 128};
const tunable int TN = {16, 32, 64, 128};
const tunable int TK = {8};
__constant__ int* delta = alloc_const int[512];
for (int c = 0; c < C; c ++)
delta[c] = c * H * W + shift_h[c] * W + shift_w[c]
void shift_conv(restrict read_only float *a,
restrict read_only float *b, float *c,
int M, int N, int K){
int rxa[TM] = get_global_range[TM](0);
int rxb[TN] = get_global_range[TM](1);
int rka[TK] = 0 ... TK;
int rkb[TK] = 0 ... TK;
float C[TM, TN] = 0;
float* pxa[TM, TN] = a + rxa[:, newaxis];
float* pb[TN, TK] = b + ryb[:, newaxis] + rkb * N;
__constant__ int* pd[TK] = delta + rka;
for (int k = K; k > 0; k = k - TK){
int delta[TK] = *pd;
float *pa[TM, TK] = pxa + delta[newaxis, :];
float a[TM, TK] = *pa;
float b[TN, TK] = *pb;
C = dot(a, trans(b), C);
pb = pb + TK * N;
pd = pd + TK;
}
int rxc[TM] = get_global_range[TM](0);
int ryx[TN] = get_global_range[TM](1);
float* pc[TM, TN] = c + rxc[:, newaxis] + ryc * M;
bool checkc0[TM] = rxc < M;
bool checkc1[TN] = ryc < N;
bool checkc[TM, TN] = checkc0[:, newaxis] && checkc1;
@checkc *pc = C;
}
6.2.1 Dense Convolutions
本小节中考虑的卷积层来自深度学习文献,如表1所示。

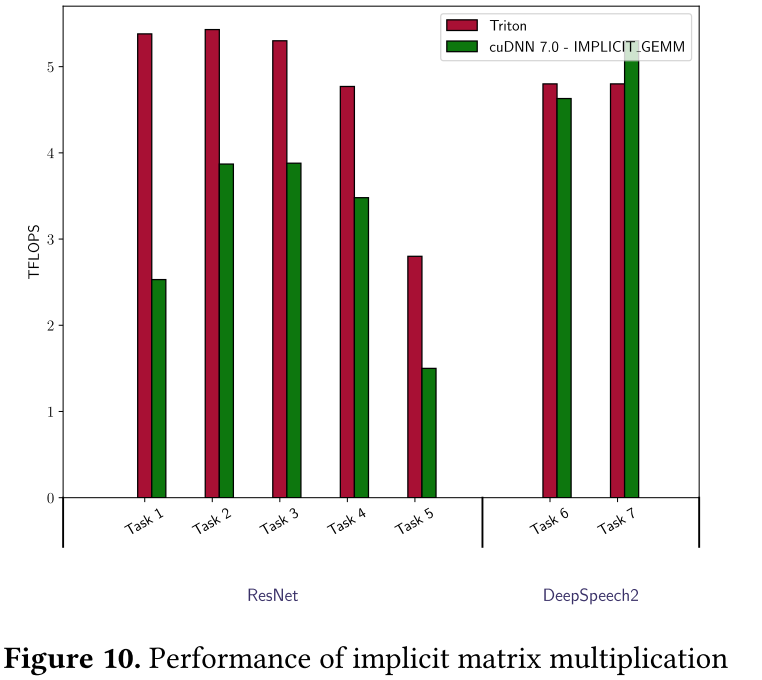
如图10所示,Triton的性能优于cuDNN对ResNet的IMPLICIT_GEMM实现。这可能是因为cuDNN还为 3 × 3 3 \times 3 3×3卷积维护了更好的算法(即 Winograd[25]),从而几乎没有留下多少工程资源来优化不太重要的内核。当快速算法不可用时(例如DeepSpeech2),cuDNN和Triton不相上下。
6.2.2 Shift Convolutions
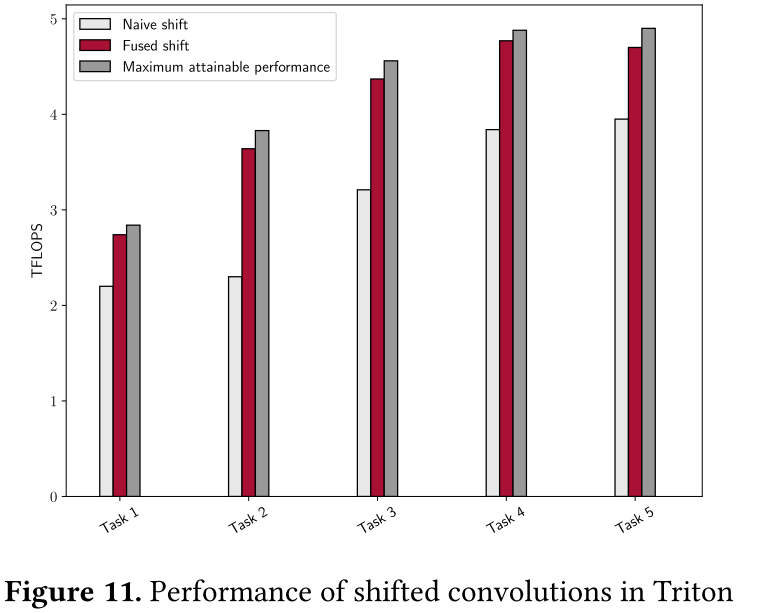
最后,我们将表1中的Task1-5的实现视为移位卷积——一种新颖的CNN方法(见图9a)。
我们将Triton中融合移位转换模块的实现(Listing 8)与依赖手写移位内核和单独调用cuBLAS的简单实现进行比较。我们还报告了未完成移位(即 1 × 1 1 \times 1 1×1卷积)时可达到的最大性能。
正如我们在图11中看到的,我们的Triton实现几乎完全隐藏了转移成本。
7 Conclusions
在本文中,我们介绍了Triton,一种开源语言和编译器,用于将平铺神经网络计算表达和编译为高效的机器代码。我们表明,只需向LLVM-IR添加一些数据流和控制流扩展就可以实现各种图块级优化过程,从而共同实现与供应商库相当的性能。我们还提出了Triton-C,这是一种高级语言,我们能够在其中为CNN的新型神经网络架构简洁地实现高效的内核。
未来的工作方向包括对张量核心的支持、量化内核的实现[26]以及集成到更高级别的DSL中。
















 451
451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











