






使用场景
在导出文件时候,我们规定同一用户只能同时导出一份数据。此时我们选择使用"USER"+userName来作为锁。
代码如下:
String key = "USER" + user.getName();
synchronized (key) {
//todo
}
其中"USER" + user.getName()会优化成StringBuilder,然后调用StringBuilder的toString方法,我们可以看到,这个时候实际上创建了一个新的String对象
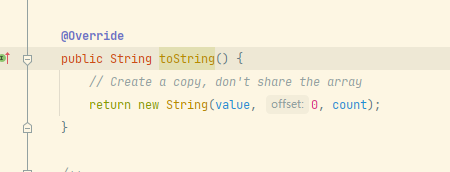
因此,即使是相同的用户,产生了相同字符串的key,也不是同一个锁。
测试代码如下:
PoJo poJo1 = PoJo.of("asd", BigDecimal.ZERO);
PoJo poJo2 = PoJo.of("asd", BigDecimal.ONE);
final String key1 = poJo1.getName() + "123";
final String key2 = poJo2.getName() + "123";
new Thread(() -> {
synchronized (key1) {
System.out.println("k1 start");
try {
Thread.sleep(2000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("k1 end");
}
}).start();
new Thread(() -> {
synchronized (key2) {
System.out.println("k2 start");
try {
Thread.sleep(2000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("k2 end");
}
}).start();
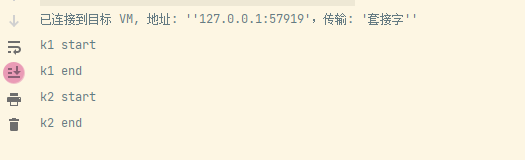
输出如下

可以看到不是我们预想的k1和k2串行执行的结果。
解决
为什么选择用String作为key来同步代码?是因为考虑到字符串常量池的存在,相同的字符串在常量池中只保存一份。
但是由于被编译器优化成StringBuilder,所以不符合原本的设想。
故,使用intern()方法即可获取字符串在常量池中对象。

执行结果如下
符合预期。
缺点
intern()方法是返回常量池中的对象,因此存在多步判断,会影响性能。
long s1 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
synchronized (String.valueOf(i)) {
int i1 = 3 / 1;
}
}
System.out.println(System.currentTimeMillis() - s1);
s1 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
synchronized (String.valueOf(i).intern()) {
int i1 = 3 / 1;
}
}
System.out.println(System.currentTimeMillis() - s1);
在百万次循环时候,上下两者时间差距为

千万次循环时候,上下两者时间差距为

但实际上可以忽略不计,业务中并没有千万级的QPS
String的编译器优化
public class TestString {
static class Pojo {
String name;
public Pojo(String name) {
this.name = name;
}
}
public static void main(String[] args) {
Pojo pojo1 = new Pojo("asd");
Pojo pojo3 = new Pojo("asd123");
String str1 = "asd" + "123";
String str2 = pojo1.name + "123";
String str3 = pojo3.name;
}
}
代码如上,我们使用javap -c TestString反编译后,可以看到
str1

直接优化成String str1 = "asd123"
str2

使用了StringBuilder的append和toString来优化。
str3

直接引用Pojo类的field















 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









