







文章目录
XML
概念和用途
- XML的全称是
Extensible Markup Language,可扩展标记语言。 - 编写XML就是编写标签,与HTML类似,拓展名.xml
- 有良好的人机可读性
与HTML的比较
- XML与HTML都是编写标签
- XML没有预定义标签,HTML有
- XML重在保存于传输数据,HTML用于显示信息
XML用途
- 是Java程序的配置描述文件。
如:

- 用于保存程序产生的数据
如:

- 网络间的数据传输

文档结构
三要素:
- 第一行必须是XML声明
- 有且仅有一个根节点
- XML标签的书写规则与HTML相同
XML声明
说明XML文档的基本信息,包括版本号与字符集,写在XML的第一行。
如:<?xml version="1.0" encoding="UTF-8"?>
version:表示版本号1.0encoding UTF-8:设置字符集,用于支持中文
第一个XML文件
<?xml version="1.0" encoding="UTF-8"?>
<!-- 注释-->
<!-- 人力资源管理系统-->
<hr>
<employee no="3309">
<name>张三</name>
<age>31</age>
<salary>4000</salary>
<department>
<dname>会计部</dname>
<address>XX大厦-A01</address>
</department>
</employee>
<employee no="3310">
<name>李四</name>
<age>30</age>
<salary>3000</salary>
<department>
<dname>工程部</dname>
<address>XX大厦-A02</address>
</department>
</employee>
</hr>
在浏览器中显示:
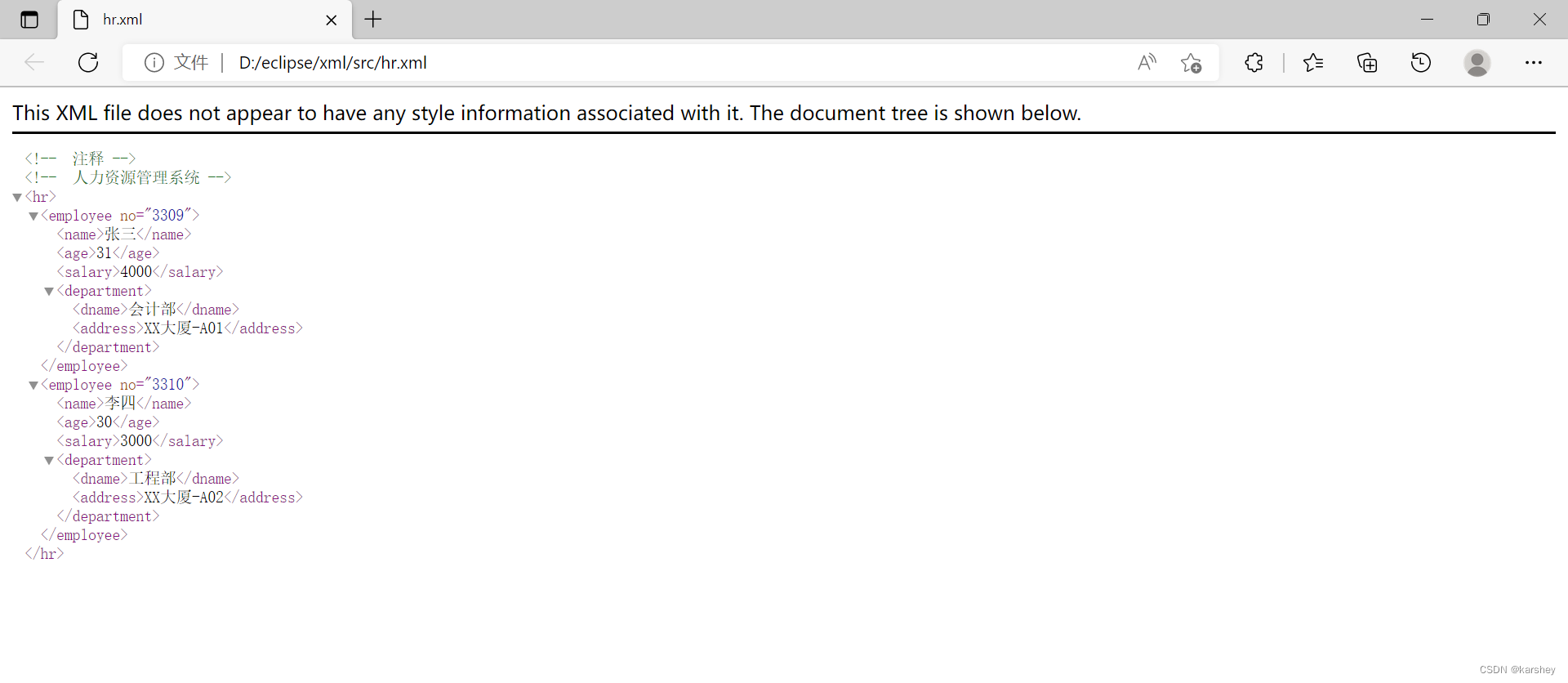
如果写错了:
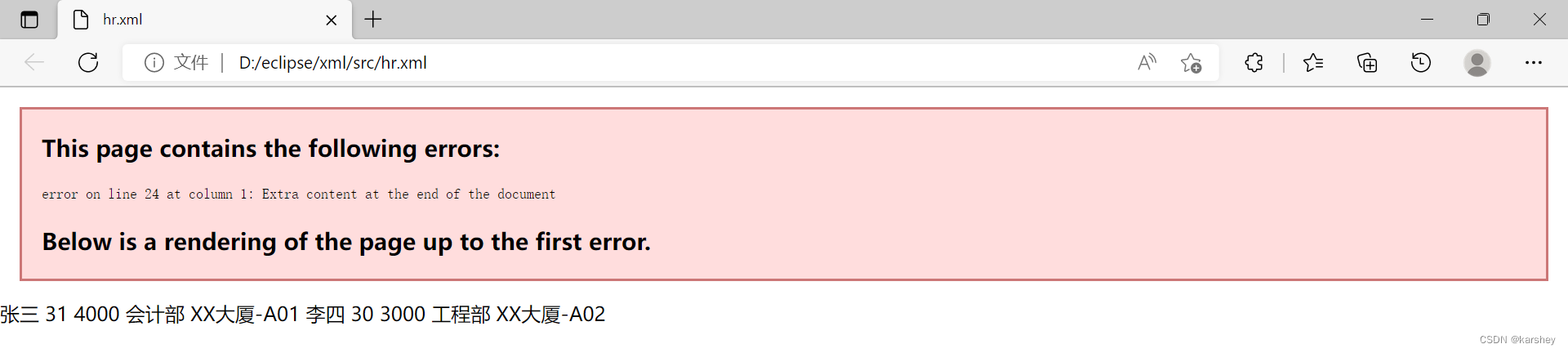
标签书写规则
- 合法的标签名
- 适当的注释和缩进
- 合理使用属性
- 特殊字符与CDATA标签
- 有序的子元素
合法的标签名
- 标签名要有意义
- 建议使用英文小写字母,单词间用
-分隔 - 多级标签之间不要存在重名的情况
合理使用属性
如:

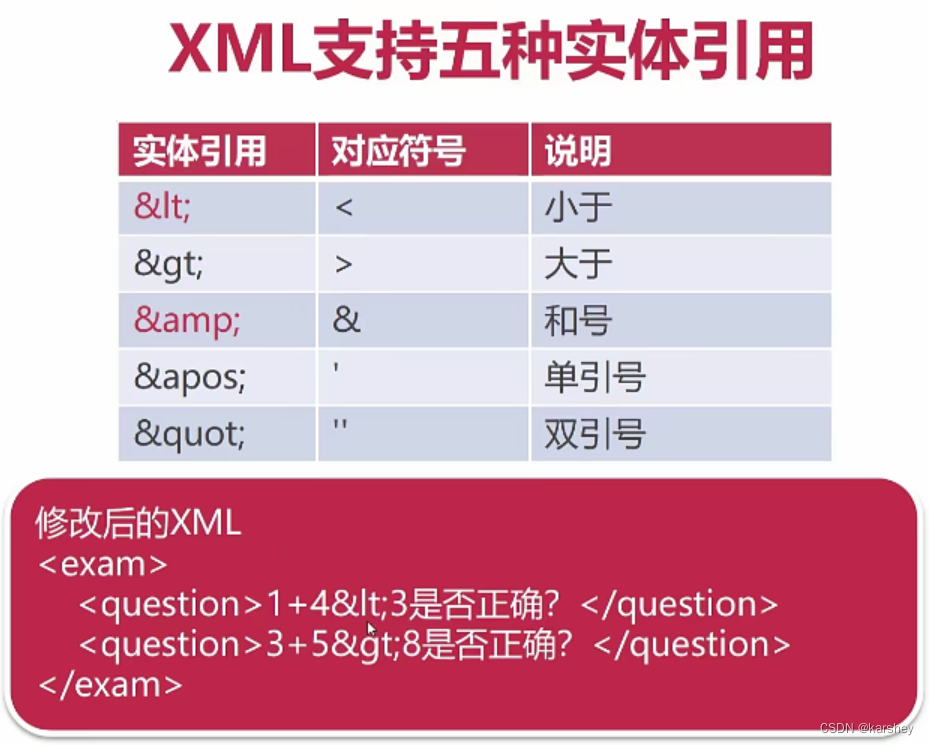
处理特殊字符
- 标签体中,出现如
<、>特殊字符,会破坏文档结构
如:<question> 1+3<4是否正确?</question>
解决方案:
- 使用实体引用
- 使用CDATA标签
XML支持的五种实体引用
CDATA标签
- CDATA指的是不应由XML解析器进行解析的文本数据
- 从
<!CDATA[开始,到]]结束
有序的子元素
- 在XML多层嵌套的子元素中,标签前后顺序应保持一致
语义约束
- XML文档结构正确,但可能不是有效的
- XML语义约束有两种定义方式:
DTD与XML Schema
DTD
- DTD,即Document Type Definition,文档类型定义:是一种简单易用的语义约束方式
- DTD文件的拓展名为
.dtd
例子:
- 定义hr节点下只允许出现1个employee子节点
<!ELEMENT hr(employee)>
- 定义employee节点下必须包含以下四个节点,并按顺序出现
<!ELEMENT employee(name,age,salary,department)>
- 定义name标签只能是文本,#PCDATA代表文本元素
<!ELEMENT name(#PCDATA)>
DTD定义节点数量
如某个子节点需要多次重复出现,则需要在子节点后增加相应的描述符。
- hr节点下最少出现1个employee子节点
<!ELEMENT hr(employee+)>
- hr节点下可能出现0~n个employee子节点
<!ELEMENT hr(employee*)>
- hr节点下最多出现1个employee子节点
<!ELEMENT hr(employee?)>
XML引用DTD文件
在XML中使用<!DOCTYPE>标签来引用DTD文件。
格式:
<!DOCTYPE 根节点 SYSTEM "dtd文件路径">
第一个dtd文件
hr.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hr SYSTEM "hr.dtd">
<!-- 注释-->
<!-- 人力资源管理系统-->
<hr>
<employee no="3309">
<name>张三</name>
<age>31</age>
<salary>4000</salary>
<department>
<dname>会计部</dname>
<address>XX大厦-A01</address>
</department>
</employee>
<employee no="3310">
<name>李四</name>
<age>30</age>
<salary>3000</salary>
<department>
<dname>工程部</dname>
<address>XX大厦-A02</address>
</department>
</employee>
</hr>
对应的dtd:
<?xml version="1.0" encoding="UTF-8"?>
<!ELEMENT hr (employee+)><!--hr与后面的括号一定要空格-->
<!ELEMENT employee (name,age,salary,department)>
<!ATTLIST employee no CDATA "">
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT salary (#PCDATA)>
<!ELEMENT department (dname,address)>
<!ELEMENT dname (#PCDATA)>
<!ELEMENT address (#PCDATA)>
XML Schema
- XML Schema比DTD更复杂,提供了更多功能
- XML Schema提供了数据类型、格式限定、数据范围等特性
- XML Schema是W3C标准
- 文件后缀:
.xsd
写xsd的时候遇到了一些困难,记录一下解决的办法:eclipse写xsd报错:s4s-elt-schema-ns: The namespace of element…且没有自动补全类提示 问题的解决方法
xml文件对xsd的引入:
<hr xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="hr1.xsd">
xsd文件:
<?xml version="1.0" encoding="UTF-8"?>
<schema xmlns="http://www.w3.org/2001/XMLSchema">
<!-- 根节点的名字是hr -->
<element name="hr">
<!-- complexType标签含义是复杂节点,包含子节点时必须使用这个标签-->
<complexType>
<!--要按sequence顺序严格书写-->
<sequence>
<!-- employee最少出现1次,最多出现9999次 -->
<element name="employee" minOccurs="1" maxOccurs="9999">
<complexType>
<sequence>
<element name="name" type="string"></element>
<element name="age">
<!--一个简单类型的约束,对年龄有约束:要求在18岁到50岁之间-->
<simpleType>
<restriction base="integer">
<minInclusive value="18"></minInclusive>
<maxInclusive value="50"></maxInclusive>
</restriction>
</simpleType>
</element>
<element name="salary" type="integer"></element>
<element name="department">
<complexType>
<sequence>
<element name="dname" type="string"></element>
<element name="address" type="string"></element>
</sequence>
</complexType>
</element>
</sequence>
<!-- 对属性的设置:属性no妖师string类型,且一定要有(required) -->
<attribute name="no" type="string" use="required"></attribute>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
DOM与Dom4j
DOM文档对象模型
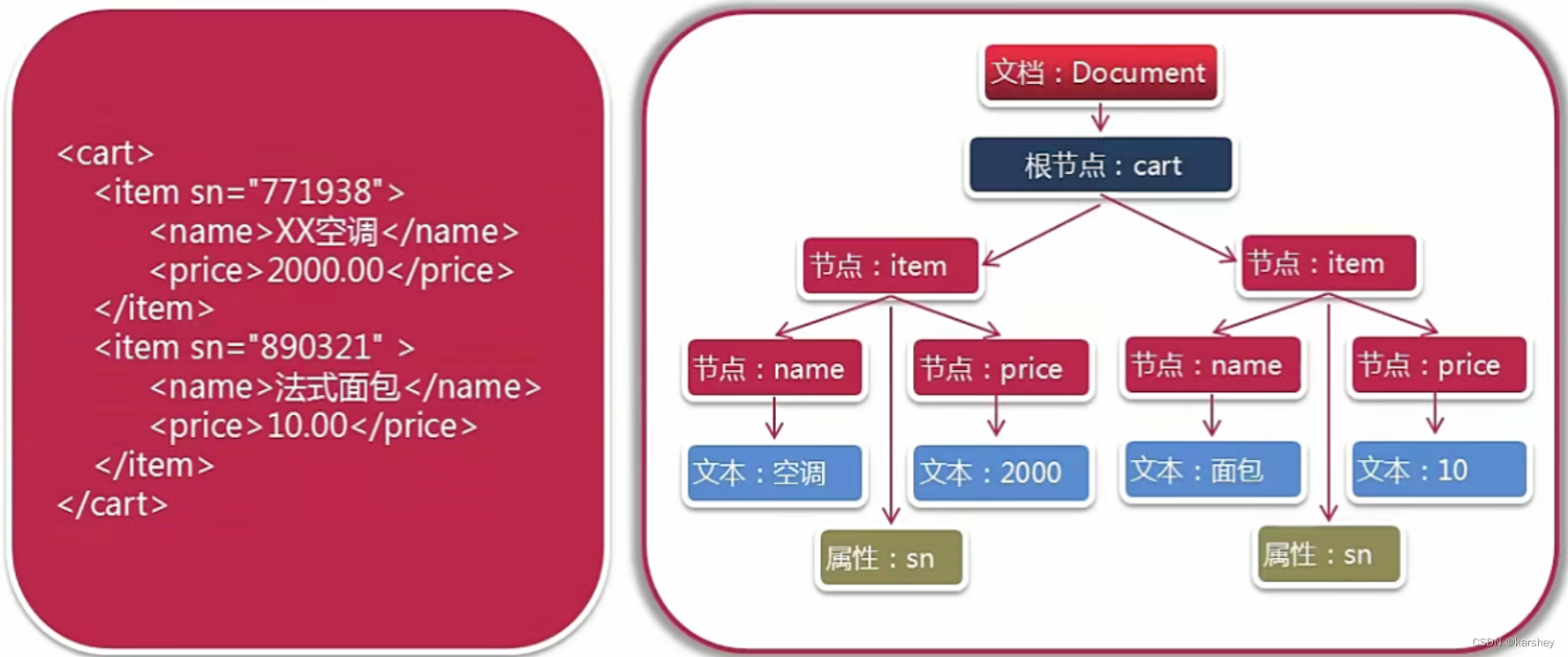
DOM,即Document Object Model,定义了访问和操作XML文档的标准方法,DOM把XML文档作为树结构来查看,能够通过DOM树来读写所有元素。
如:
Dom4j
- Dom4j是一个易用的、开源的库,用于解析XML。它应用于Java平台,具有性能优异、功能强大和极其易使用的特点
- Dom4j将XML视为Document对象
- XML标签被Dom4j定义为Element对象
Dom4j遍历XML
下载Dom4j:下载地址
在src下创建一个Foler,命名为lib。把下载的Dom4j拖进去。
然后:
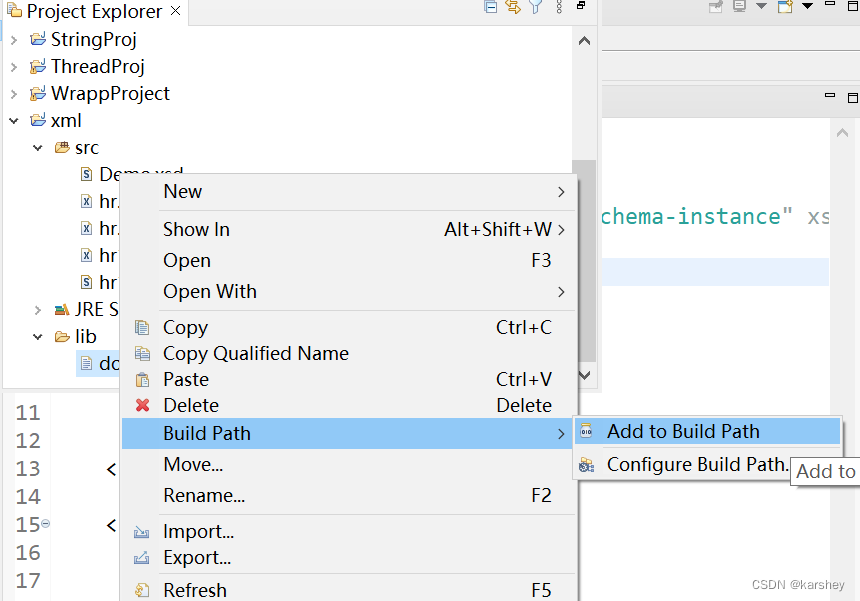
若出现了一个新的dom4j就成功了。
尝试一下:
xml文件为:
<?xml version="1.0" encoding="UTF-8"?>
<!-- 注释-->
<!-- 人力资源管理系统-->
<hr xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="hr1.xsd">
<employee no="3309">
<name>张三</name>
<age>31</age>
<salary>4000</salary>
<department>
<dname>会计部</dname>
<address>XX大厦-A01</address>
</department>
</employee>
<employee no="3310">
<name>李四</name>
<age>30</age>
<salary>3000</salary>
<department>
<dname>工程部</dname>
<address>XX大厦-A02</address>
</department>
</employee>
</hr >
java文件为:
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class HrReader {
public void readXml() {
//hr.xml的地址
// String file="D:\\eclipse\\xml\\src\\hr.xml"; //这样也可以
String file="D:/eclipse/xml/src/hr.xml";
//SAXReader类是读取XML文件的核心类。用于将XML解析后以"树"的形式保存在内存中
SAXReader reader=new SAXReader();
//解析
try {
Document document=reader.read(file);
//获取XML文档的根节点,即hr标签
Element root=document.getRootElement();
//获取所有employee标签
List<Element> employee =root.elements("employee");
//遍历
for(Element e:employee) {
//element方法用于获取唯一的子节点对象
Element name=e.element("name");
//获取标签的文本值
String empName=name.getText();
System.out.println(empName);
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
HrReader reader=new HrReader();
reader.readXml();
}
}
输出:
张三
李四
若把Element name=e.element("name");的name改成age,则输出:
31
30
可以把这三句合并:
//element方法用于获取唯一的子节点对象
Element name=e.element("name");
//获取标签的文本值
String empName=name.getText();
System.out.println(empName);
合并为:
System.out.println(e.elementText("name"));
如果想要获得属性:
for(Element e:employee) {
//element方法用于获取唯一的子节点对象
Element name=e.element("name");
//获取属性no
Attribute att=e.attribute("no");
System.out.println(att.getText());
}
输出:
3309
3310
Dom4j更新XML
如何利用Dom4j往XML里写数据呢?用addElement方法创建新节点。
我们想给XML加一个新的节点:
- 姓名:王五
- 编号:3301
- 年龄:25
- 工资:3600
- 部门:人事部
- 地址:XX大厦-A03
增加新节点的代码:这只是在内存中增加新节点,我们稍后还要把它写进XML
Document document=reader.read(file);
Element root=document.getRootElement();
//用addElement方法创建新的employee节点
Element employee=root.addElement("employee");
//增加属性
employee.addAttribute("no", "3311");
//新节点的姓名
Element name=employee.addElement("name");
name.setText("王五");
//年龄
employee.addElement("age").setText("25");
//工资
employee.addElement("salary").setText("3600");
//办公地点
Element department=employee.addElement("department");
department.addElement("dname").setText("人事部");
department.addElement("address").setText("XX大厦-A03");
写进XML的代码:
Writer writer=new OutputStreamWriter(new FileOutputStream(file),"UTF-8");
document.write(writer);
writer.close();
总体代码:
import java.io.FileOutputStream;
import java.io.OutputStreamWriter;
import java.io.Writer;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class HrWriter {
public void writeXML() {
//获取XML文件路径
String file="D:/eclipse/xml/src/hr.xml";
//对XML文件读取和解析
SAXReader reader=new SAXReader();
try {
Document document=reader.read(file);
Element root=document.getRootElement();
//用addElement方法创建新的employee节点
Element employee=root.addElement("employee");
//增加属性
employee.addAttribute("no", "3311");
//新节点的姓名
Element name=employee.addElement("name");
name.setText("王五");
//年龄
employee.addElement("age").setText("25");
//工资
employee.addElement("salary").setText("3600");
//办公地点
Element department=employee.addElement("department");
department.addElement("dname").setText("人事部");
department.addElement("address").setText("XX大厦-A03");
//以上这一段只是在内存中进行编写
//以下是把这些写入XML中
//把文件输出流转成writer对象
try {
Writer writer=new OutputStreamWriter(new FileOutputStream(file),"UTF-8");
document.write(writer);
writer.close();
} catch (Exception e) {
e.printStackTrace();
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
HrWriter hrWriter=new HrWriter();
hrWriter.writeXML();
}
}
结果,hr.xml中增加了:
<employee no="3311">
<name>王五</name>
<age>25</age>
<salary>3600</salary>
<department>
<dname>人事部</dname>
<address>XX大厦-A03</address>
</department>
</employee>
XPath路径表达式
基本表达式与谓语表达式
- XPath路径表达式是XML文档中查询数据的语言
- 可以提高在提取数据时的开发效率
- 学习XPath后可以掌握各种形式表达式的使用技巧
基本表达式
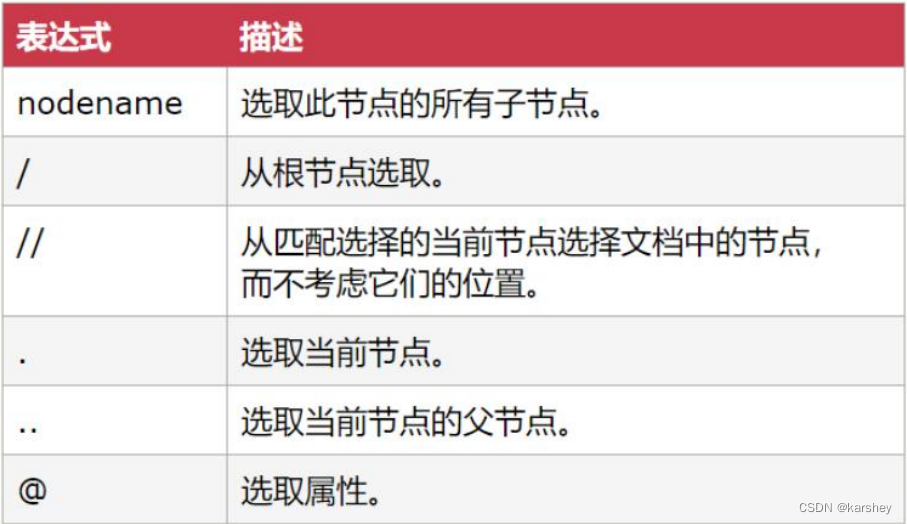
相关案例:

谓语表达式
使用中括号[]再加一个谓语来说明。

Jaxen介绍
- Jaxen是一个Java编写的开源的XPath库。Jaxen适应多种不同的对象模型,包括DOM,XOM,Dom4j和JDOM。
- Dom4j底层依赖Jaxen实现XPath查询
下载Jaxen:阿里云云效 Maven
在这里搜Jaxen即可。
我下载的是这个:
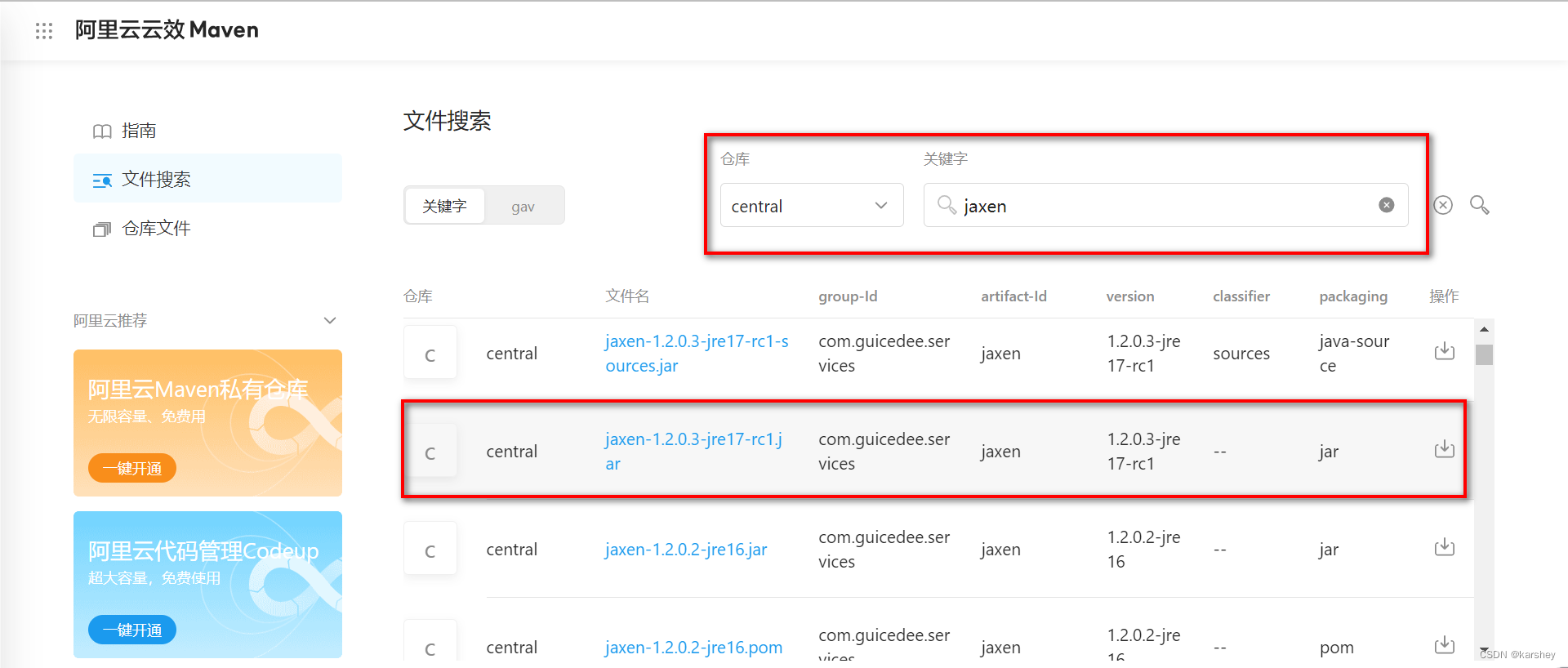
我们把下载好的jar包复制到lib下,然后:
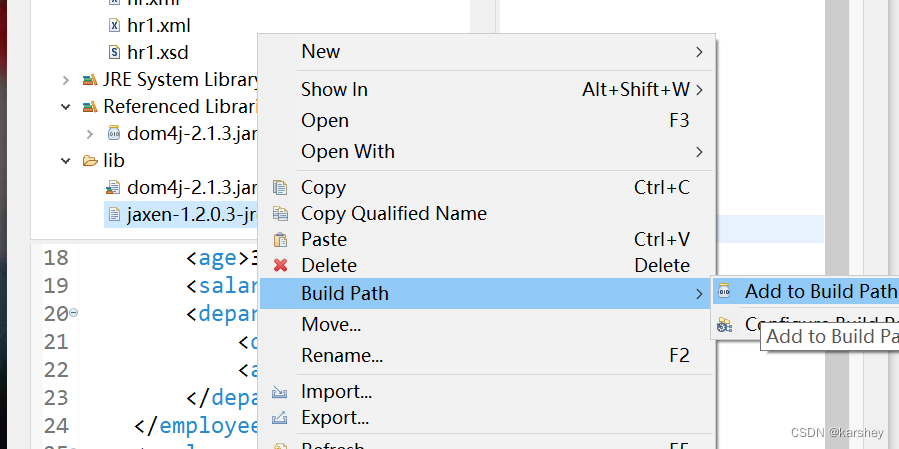
现在我们用XPath进行查询。
XPath的运用
hr.xml文件改一下,多增加一点员工:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hr SYSTEM "hr.dtd">
<!-- 人力资源管理系统 -->
<hr>
<employee no="3301">
<name>李铁柱</name>
<age>37</age>
<salary>3600</salary>
<department>
<dname>人事部</dname>
<address>XX大厦-B105</address>
</department>
</employee>
<employee no="3302">
<name>林海</name>
<age>50</age>
<salary>7000</salary>
<department>
<dname>财务部</dname>
<address>XX大厦-B106</address>
</department>
</employee>
<employee no="3303">
<name>安娜</name>
<age>24</age>
<salary>4600</salary>
<department>
<dname>人事部</dname>
<address>XX大厦-B105</address>
</department>
</employee>
<employee no="3304">
<name>张晓宇</name>
<age>29</age>
<salary>3000</salary>
<department>
<dname>后勤部</dname>
<address>XX大厦-B108</address>
</department>
</employee>
<employee no="3305">
<name>赵子轩</name>
<age>19</age>
<salary>1500</salary>
<department>
<dname>后勤部</dname>
<address>XX大厦-B108</address>
</department>
</employee>
<employee no="3306">
<name>张晓璇</name>
<age>20</age>
<salary>1700</salary>
<department>
<dname>后勤部</dname>
<address>XX大厦-B108</address>
</department>
</employee>
<employee no="3307">
<name>张檬</name>
<age>43</age>
<salary>8700</salary>
<department>
<dname>会计部</dname>
<address>XX大厦-B103</address>
</department>
</employee>
<employee no="3308">
<name>李梅</name>
<age>33</age>
<salary>8700</salary>
<department>
<dname>工程部</dname>
<address>XX大厦-B104</address>
</department>
</employee>
<employee no="3309">
<name>张三</name>
<age>31</age>
<salary>4000</salary>
<department>
<dname>会计部</dname>
<address>XX大厦-B103</address>
</department>
</employee>
<employee no="3310">
<name>李四</name>
<age>23</age>
<salary>3000</salary>
<department>
<dname>工程部</dname>
<address>XX大厦-B104</address>
</department>
</employee>
</hr>
用XPath的例子:这里的XPath表达式是/hr/employee,即要根节点下的所有employee,输出所有employee节点的name、age、salary:
public class XPathTestor {
// 参数:传入的XPath表达式
public void xpath(String xpathExp) {
String file = "D:/eclipse/xml/src/hr2.xml";
SAXReader reader = new SAXReader();
try {
Document document = reader.read(file);
// 接下来是执行XPath的核心方法selectNodes
// Node是节点Element和标签Attribute的父类,是selectNodes返回的数据类型
// selectNodes返回的是一个List
List<Node> nodes = document.selectNodes(xpathExp);
// 对List进行遍历
for (Node node : nodes) {
Element emp = (Element) node;
// 打印name
System.out.println(emp.elementText("name"));
System.out.println(emp.elementText("age"));
System.out.println(emp.elementText("salary"));
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
public static void main(String[] agrs) {
XPathTestor testor = new XPathTestor();
// 想要所有的employee节点。其中hr是根节点。
String str = "/hr/employee";
testor.xpath(str);
}
}
输出:
李铁柱
37
3600
林海
50
7000
安娜
24
4600
张晓宇
29
3000
赵子轩
19
1500
张晓璇
20
1700
张檬
43
8700
李梅
33
8700
张三
31
4000
李四
23
3000
就是这样。
关于XPath表达式:
- 想要从根节点hr出发下的所有employee:
/hr/employee - 想要所有的employee标签,不管它在哪里:
//employee - 想要工资小于4000的员工的姓名:
/hr/employee[salary<4000]或//employee[salary<4000]
代进去,输出得:
李铁柱
张晓宇
赵子轩
张晓璇
李四
- 想要李铁柱这个员工的信息:
//employee[name="李铁柱"] - 找到编号为3301的员工:这里标号是属性:
//employee[@no="3301"] - 找到员工编号最小的:
//employee[1]——表示第一个出现的employee - 找到前五个员工:
//employee[position()<6]
代入得:
李铁柱
林海
安娜
张晓宇
赵子轩
XPath支持组合表达式:如果想要第3和8名员工,可以://employee[3] | //employee[8],竖线|表示把前后两个合并。
代入得:
安娜
李梅
















 1195
1195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











