







使用urlopren()分分钟拔下一个网页
例子
# -*- coding:utf-8 -*-#导入request
from urllib import request#打开网页
response=request.urlopen("http://www.umei.cc/meinvtupian/xingganmeinv/")
html=response.read().deconde("utf-8")
print(html)直接用urllib.request模块的urlopen()获取页面数据格式为bytes类型,需要decode()解码,转换成str类型。
urlopen返回对象提供方法:
- read() , readline() ,readlines() , fileno() , close() :对HTTPResponse类型数据进行操作
- info():返回HTTPMessage对象,表示远程服务器返回的头信息
- getcode():返回Http状态码。如果是http请求,200请求成功完成;404网址未找到
- geturl():返回请求的url
使用urlretrieve()分分钟下载图片
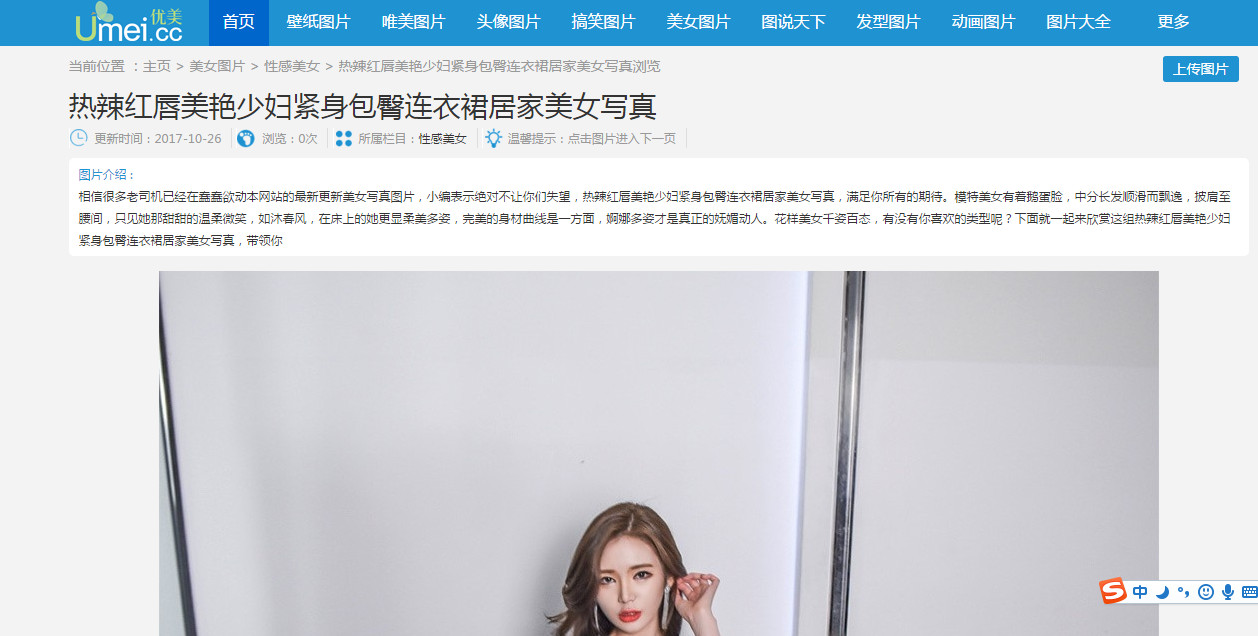
比如我们要下载这个网页里面的这张图片
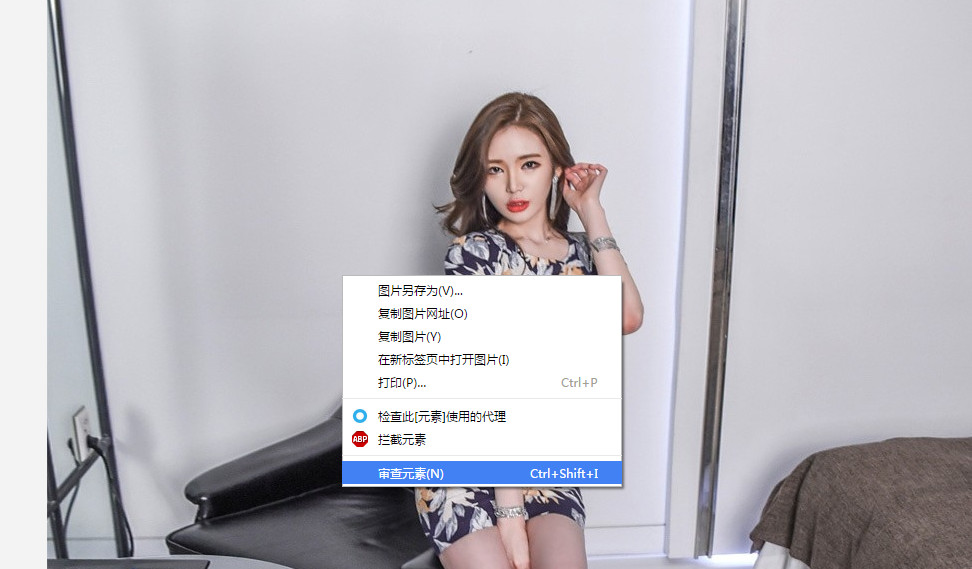

# -*- coding:utf-8 -*-
from urllib import request
#图片url地址
imgurl="http://i1.umei.cc/uploads/tu/201709/9999/62bb166433.jpg"
request.urlretrieve(imgurl,filename="美女.jpg")
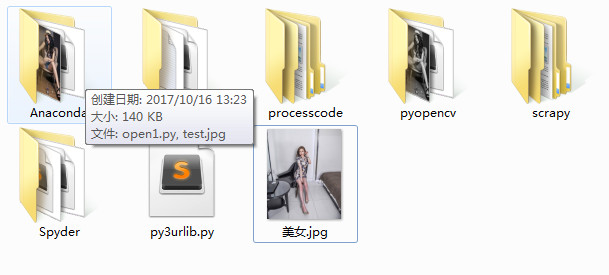
最简单的爬虫就是这样的啦!















 2386
2386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









