







搜索下拉框也叫搜索提示,搜索下拉推荐,QAC(Query autocompletion),Query suggestion。本质上是指搜索引擎系统根据用户当前的输入,自动提供一个query候选列表供用户选择,这些推荐query一般从query log中挖掘出大量的候选query,并且保持前缀相同,然后依据某种法则给候选query计算一个分数,最后选择出top10作为最终结果。搜索下拉框在搜索引擎和广告竞价平台中已经是标配的产品,它可以帮助用户明确搜索意图,减少用户的输入并节约搜索时间,提高搜索体验有重要作用。各个搜索系统的下拉推荐的处理流程基本相同,不同主要体现在后台的query候选产生机制不同,下面先介绍几种我们常用的下拉推荐算法:基于全量日志的自动补全模型、基于时间序列的自动补全模型、基于用户信息的自动补全模型、基于上下文的自动布线模型。
| 目的 | 算法 |
|---|---|
| 方便用户输入 | 基于全量日志 |
| 缩短用户搜索时间 | 基于时间序列 |
| 图稿搜索准确度 | 基于用户信息 |
| 提高用户搜索体验 | 基于上下文 |
一、常用的算法介绍
1、基于全量日志的自动补全模型
常见的算法是MPC,也就是Most popular completion models。算法流程如下:
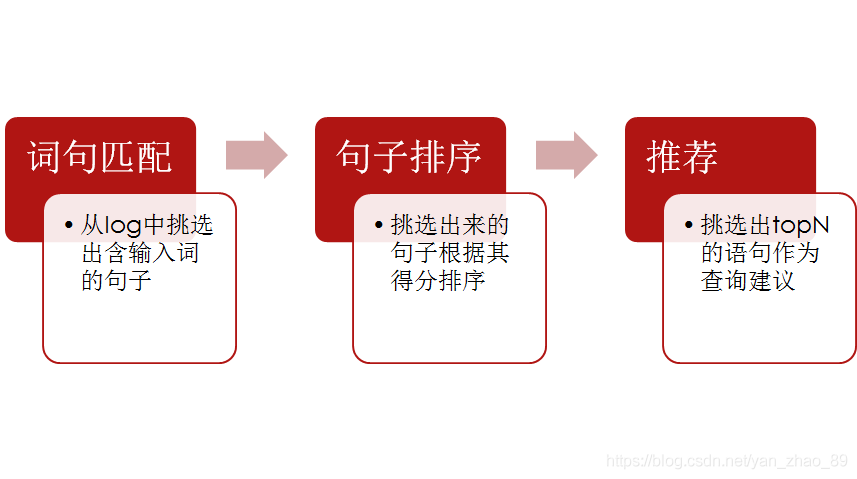
在构造索引后,如何进行排序呢?简单的逻辑是按照query的搜索次数进行排序,这样符合大多数人的习惯。计算公式如下:
然而这种方法有着很大的缺陷,推荐的结果容易集中少数热门query上,长尾query得不到曝光的机会。
在蘑菇街的应用中,造次对这种方法进行改造,在海量query log中,同意一段时间内每个query的pv和点击数等数据。第一种是根据搜索次数、gmv变化率、点击率等指标做一个加权融合,并对多天数据进行贝叶斯平滑。
第二种是考虑query的静态分。什么是query的静态分。query静态分是query质量的综合指标,该指标拟合了query各维度的知识:
| query |
| pv |
| ctr |
| 成交转化率 |
| 成交笔数 |
| 成交金额 |
| 召回商品数 |
从而建立以query转化率为目标,用户session内行行为为特征的LR模型。这种方法不仅考虑了query的历史点击信息,而且考虑了query的交易信息,是的交易行为良好的query获得更多的展现机会,大大降低了低质量和作弊query的展现概率。
2、基于时间敏感的自动补全模型
之所以考虑时间敏感的query推荐,是因为用户的检索行为随时间发生变化,不同用户在搜索中关注的焦点也不尽相同。即在不同时间,用户的查询倾向也不同(其实在相同时间,不同用户的查询倾向也不同)。分析时间因素对用户搜索行为的影响,为用户提供符合时间趋势、季节性、周期性的查询词,将大大提升用户搜索效率和用户搜索满意度。主要的方法是应用时间序列进行预测。如Holt-Winters加法指数平滑模型:
这里考虑了水平、趋势、季节的影响,为t时刻的值,表示预测的频率值。
需要注意是因为电商的大多数query词对时间敏感性并不是很强,一般在换季阶段诉求比较强烈。主要是针对用户的自主搜索query进行分析,根据一周内的用户自主搜索记录来计算query相对熵和新词等数据,一次作为对时间敏感型的query补充。
3、基于用户信息的自动补全模型
这里需要结合用户的一些信息进行推荐。根据用户的行为,识别用户的意图,对用户进行分析建模。例如识别用户的年龄、性别、购买力、短期和长期query偏好。结合之前的初排结果进行再次个性化建模推荐。这里有两个步骤:
1) 计算用户和query的相关个性化特征
2)建立合理的评价机制对这些特征学习计算权重。我们这里用的模型是LR,评级指标采用AUC。需要注意的是用户的行为往往是稀疏的,我们还需要挖掘更多其他场景的用户行为进行计算。
蘑菇街的用户性别比例差别较大。年龄段比较集中,购买力相当,风格大多比较雷同。因此这些个性化信息并不能取得较好的效果,比较有价值的是用户的点击反馈和其他场景搜索记录,从而获取用户对query的偏好。另外一个需要问题是过度个性化问题,容易陷入到搜索的闭环中,需要融合一些其他模型来避免这个问题。
4、基于上下文的自动补全模型
上下文通常会考虑用户的query session,session内的query通常是相关的,那么一个简单的想法是,将用户的上下文和候选query映射到某个空间,然后计算每个初始选择的query和上下文的相似度,越相似的query,越能表征当前用户的搜索意图,那么分数越高,这个时候就排名越靠前。
1) 如何将上下文和候选query映射到同一个空间
2)映射之后,如何计算它们的相似度?
类似于搜索引擎,我们将context当做query,把候选query当做document,那么这个问题其实就是一个匹配问题。因此可以把query和context表示成词的向量,那么相似度的计算才用最简单的cosine similarity计算即可。
例如用户搜索“nike钱包”,我们计算出nike钱包和adidas钱包的相关性最高,那么用户在下一个query中输入adidas应该提示adidas钱包,这个我们的预期是一致的。同时去观察session下当然除了上面的上下文方法,还应用了一些深度学习方法。
这几种方法对比如下:
| Angle | MPC | Time-sensitive | Context-centered | User-centered |
| Strength | 简单、易实现 | 简单、时效 | 精准 | 精准 |
| Weakness or Issuse | 长尾、热词无解 | 有限消息不准确 低鲁棒性 | 难解决突变和不相关的情形 | 难发现新兴趣、难实现 |
| Requirement | 全量日志 | 全量日志(时间) | 全量log、context | 全量log、个人log |
| Assumption | Query频率不变 | 趋势、周期 | Query间具有相关性 | 用户查询反应兴趣 |
在实践中,一般是将多种策略算法融合在一起使用
二、一些实践和问题思考
1、下拉框的数据流程

我们将数据产生过程分成3个阶段,召回、模型排序和个性化层面。3个层解决的问题是不同的,召回层主要解决query丰富性问题,排序层解决的是模型匹配和相关性问题,个性化解决语义重复和个性化偏好的问题。
召回中我们首先会按照query的最近一周表现计算query的一个转化率分数,形成候选candidate-set。同时引入了一些长尾的新词和趋势词加入到池子中。这些词大概覆盖几十万的query结果,95%以上的叶子类目覆盖率,流量占比85%+。因为下拉框的功能是提供搜索提示,那么常用的规则就是前缀匹配,在用户的搜索意图下进行query补全,由于不同的用户搜索词下结果是不同的,这涉及到一个匹配的问题,我们构建了索引结构的平面存储结构,覆盖用户拼音、汉字、拼音+汉字+简写的搜索习惯至少几百万的搜索结果,这些结果中明显是稀疏集,推荐query词大于2个结果的大约百万万。至于为什么用这些的结构,其中一个好处是查询方便。
模型排序我们试了一些方法,主要的思路是根据去挖掘相应的特征,query特征以及索引特征,搜索prefix然后去点击query的相关统计特征都可以获得,还有一些是文本特征,例如索引和query的编辑距离,DBOW向量等,这些都可转为libsvm格式去调用ranklib去计算排序。试过lambda-mart-随机深林-网格查找等多模型优化,现在用的比较多的是根据hred模型计算不同query下的文本相关性分数,按照pop_score和hred_score加权融合排序。
个性化层做过两方面的尝试,query语义过滤是解决推荐结果中意图重复的问题,按照query召回结果重复以及同义词、子串过滤。个性化精排按照用户的query偏好、文本相关性、重新排序。
2 一些问题和思考
这里列出一些自己遇到问题和思考,起到抛砖引玉的作用,具体细节就不说了,欢迎交流。
2.1 搜索query和候选query之间的联系?
目前搜索query与候选query之间的联系仅仅是两者的前缀相同。这种简单的动态特征没有将搜索query与候选query紧密的结合在一起,同时静态特征和动态特征的组合都是基于线性加权。为了建立起两者的联系,我们考虑了搜索query和候选query的一些特征,在模型上经历了pointwise到pairwise到listwise(lamdamart)的转变。下拉提示结果是一个list,当用户选择下面某个query点击时,认为这个词更能满足用户的需求,那么上面的推荐query就可以为负样本,以此利用lambdamart模型进行计算。另外一种考虑文本相关性的联系。利用用户session记录来对词进行向量表示,这里参考了seq2seq的模型,针对用户搜索词和推荐query计算相关性加权到现有的结果中调整排序。这两种均能取得一定的收益。
2.2 如何建立query索引?
什么是索引呢?索引就是在同一个搜索前缀下,得到的前缀相同的query推荐结果集。索引的目的是前缀匹配的应用,由于用户搜索结果是未知的,本质上我们需要了给出所有的推荐结果,由于支持拼音、中文和简写输入和混合等功能,那么这个索引结构就会特别大,存储和计算都会占用不小的开销,而实际上用户常搜索的词是有限的,因此索引集将十分稀疏,最关键的是,索引大了,同一前缀下推荐结果特别多,匹配效率就会降低。为了解决这个问题,我们需要更好的索引形式,例如trie树。不过目前之所以还用平行化的pair对索引结构,一是考虑到词数量有限的,二是构造样本和后续计算比较方便。当然除了前缀匹配还有其他触发逻辑可以选择,这点淘宝曾做过长尾query的模糊匹配触发。在下拉框整个工程中,索引的建立是至关重要的一环,不仅要满足用户的需求,还得提高匹配效率。
2.3 相关性和语义问题?
在实践中,无论采用哪种方法,我们总会遇到推荐的结果query词比较集中的情况,例如搜索小白鞋,推荐词为小白鞋女、小白鞋女生,本质上这种结果语义重复,浪费了一个位置,我们需要予以取舍过滤。目前的方法采用Word2vec计算同义词、编辑距离、引擎召回商品判断等。还有一个需要考虑的问题是推荐query是否需要递增出现?需要分析用户的意图是否明显?如何不明显,那么后缀递增是否能代表用户的需求?因为下拉框前几个词如果太长、后面很短是否影响体验和用户选择?
2.4 深度学习在下拉框的应用
随着深度学习的流行,一些算法RNN、CNN等模型开始暂露头角。在下拉框中主要是两个应用,第一是文本表示,对query构造向量计算相似query和文本相关性。第二我们参考了A Hierarchical Recurrent Encoder-Decoder for Context-Aware Generative Query Suggestion论文,利用session信息计算query和上下文的匹配分从而对结果排序,结构采用目前比较流行的GRU变体,在模型训练上我们用了一周的时间,迭代计算上百万次,从效果上看对点击率有一定的提升作用,推荐的query结果还算比较合理,具体细节可以参考这篇文章。
2.5 结果的衡量和目标调整?
对于前缀和query,同一个前缀下query结果本身就保证了一定的相关性,对于运营评估来说,哪个query排在前面和后面无法进行量化。当用一些推荐结果评估中,我们无法给出最优集合,根据label定义的ndcg本身就是有偏的。另外按照前缀下的query是否点击和成交来看,本身稀疏性特别大,一些没有出现的query没有曝光机会,造成偏差。按照全局query来看,label代表一定的趋势,但是下的特征就弱化了。一个好的样本label影响到最终的优化方向和评价。后面是按照ctr、cvr还是gmv rate需要评估和设计。
2.6 移动搜索个性化的需求?
用户在搜索的时候,肯定是有一些个性化需求在的。有的包含在query中,例如夏季连衣裙女长款,包含季节、性别、偏好、产品词等需求。有的隐含在之前的搜索记录和反馈上,针对用户做个性化,无非是考虑用户之前的行为,理解和转化用户的搜索意图,这点我们做了一些尝试,一般思路是根据初排的结果再融合个性化信息进行rerank。比较常见的像淘宝的用户搜索历史query的加权。需要注意的是个性化引导是否会导致过度个性化?
2.7 搜索闭环和丰富性?
从用户来说,搜索结果希望能包含用户所有的搜索意图,query和类目丰富性越多越好,针对整个推荐结果,我们是不是推荐的结果越来越集中呢?因此需要考虑用户的引流和流量分布,query之间的转化、这些监控指标能帮助平台更好健康发展。
参考文献
[1]C.H.Ricardo Baeza-Yates and M.Mendoza. Query recommendation using query logs in search engines. In Trends in Database Technology-EDBT 2004 Workshops, 2005.
[2]ShokouhiM,RadinskyK.Time sensitive query auto completion [A].Procedings of the 35th International ACM SIGIR Con ference on Researchand Developmentin InformationRetrieval [C].Portland:ACM,2012.601-610.
[3]BarYosefZ,KrausN.Context sensitive queryauto completion[A].Procedings of the 20th International Conference on World Wide Web[C].Hyderabad:ACM,201.107-16.
[4]M. Shokouhi. Learning to personalize query auto-completion. In SIGIR ’13, pages 103–112, 2013.
[5]B. Mitra. Exploring session context using distributed representations of queries and reformulations. In Proceedings of the 38th International ACM SIGIRConference on Research and Development in
Information Retrieval, pages 3–12. ACM, 2015.
[6]A. Sordoni, Y. Bengio, H. Vahabi, C. Lioma,
J. Grue Simonsen, and J.-Y.Nie. A hierarchical recurrent encoder-decoder for generative context-aware query suggestion. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, pages 553–562. ACM, 2015.















 4763
4763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









