







一、模块
1.模块循环导入
当俩个模块彼此导入对方时可能出现,需要的函数、类、变量还没有生成,导致调用错误。
#c.py内容
import d
def c1():
print("from c")
d.d1()
#d.py内容
import c
def d1():
print("from d")
c.c1()

如果已经发生循环导入,同时无法更换别的方式便只能将需要使用到的变量、函数、类提前到导入语句之前或者将导入语句放入函数体内部,就可以被调用。
2.判断py文件是执行文件还是被导入文件
#执行文件c.py
import d
print("我是执行文件")
print(__name__)
#被导入文件d.py
print("我是被导入文件")
print(__name__)

借用__name__可以将代码分割为导入与执行是可用以及仅执行可用。
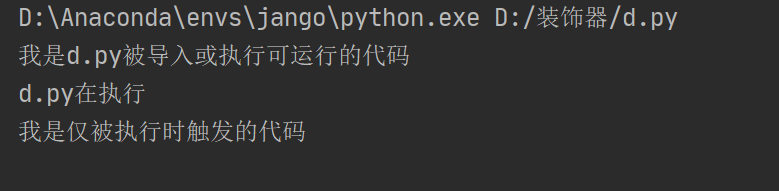
import d
print("c.py在执行")
print("我是d.py被导入或执行可运行的代码")
if __name__ == '__main__':
print("d.py在执行")
print("我是仅被执行时触发的代码")
执行c.py时,无法触发使用 name == ‘main’ 限制的代码

执行d.py时,可以触发使用 name == ‘main’ 限制的代码
3.模块导入时查询模块位置的顺序
- 从内存中获取所需模块
- 从内置模块中获取
- sys.path中查找
4.导入模块时的注意事项
模块的导入时基于执行文件所在根目录来执行的


当需要导入的模块与执行文件不再同一层级,导入将会出错
import d
print("c.py在执行")

- 此时可以使用路径.文件完成导入
import D.d
print("c.py在执行")

2. 除此之外还可以使用from 路径/文件夹 import 模块名
from D import d
print("c.py在执行")

3. 可以向sys.path中加入对应路径此时可以按照执行文件和被导入文件在同一层级处理
import sys
sys.path.append(r'D:\装饰器\D')#绝对路径
sys.path.append(r'F')#相对路径
import d
import f
print("c.py在执行")

二、包
包的作用是将代码解耦,使各个功能之间不再相互干扰,方便协作开发以及代码的维护。
包实质上就是文件夹,只不过文件夹中又一个__init__.py的文件。
而__init__.py的作用便是管理该包下各文件的调用,方便开发时的使用。
三、软件开发目录规范
软件开发需要划分各项功能,方便开发同时维护与协作开发也能更方便,各个模块也不会产生影响。
- 核心业务文件夹:用于存放核心业务代码
- 启动配置文件夹:用于存放启动软件的配置文件
- 日志文件夹:存放日志,方便管理软件以及软件的恢复
- 设置文件夹:存放对软件的各方面设置文件
- 数据文件夹:存放数据文件
- 公共文件夹:存放一些公共的功能代码
- 程序文本文件夹:存放使用说明、文件说明、广告等额外信息
- 开发环境及其版本的文本文件















 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









