







文章目录
一、re是什么?
re模块是python独有的匹配字符串的模块,使用模块时需要学会正则表达式
二、re使用
1.findall
import re
str = "english learn stopping august"
res1 = re.findall('e', str)
print(res1)

findall方法是匹配所有符合条件的对象,并返回结果
2.search
search方法查找到一个符合条件的对象就会停止,没有时返回none,none时无法使用group方法查看,否则会报错。
res2 = re.search('e', str)
print(res2.group())

3.match
match方法查找头部符合的对象,找到后停止,找不到返回none(在正则表达式中为^)
re3 = re.match('e', str)
print(re3.group())
4.finditer
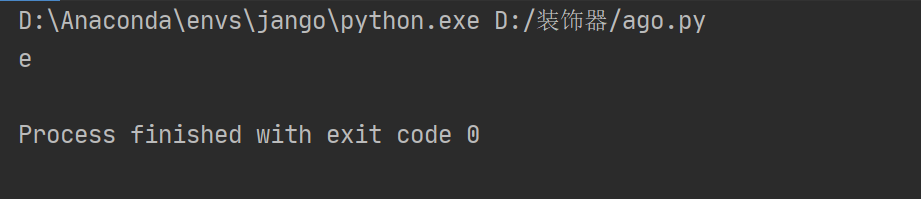
finditer查找全部符合的对象,返回结果为迭代器对象,方便节省内存
re4 = re.finditer('e', str)
print([o.group() for o in re4])

5.compile
commpile用于自定义正则表达式规则,便于后续匹配的使用
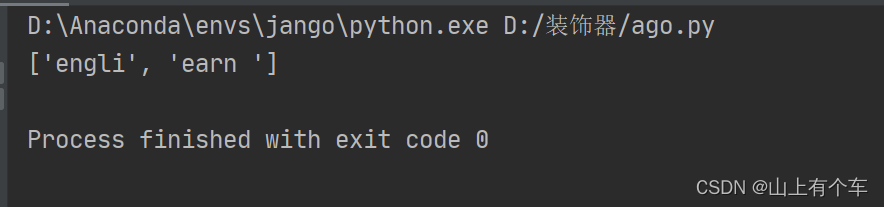
find = re.compile("e.{3,4}")
re5 = re.findall(find, str)
print(re5)
三、re模块中()的使用
在re模块中对需要匹配的对象使用括号,将优先展示括号所匹配到的内容。在括号中加入?:将取消优先展示效果
1.findall、finditer
对于()使用findall和finditer一样,()将会优先其中所匹配到的结果。
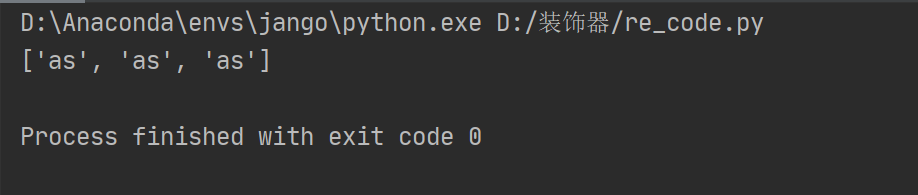
str = "asiabscassdsasikkasil"
res1 = re.findall("(as)i",str)
print(res1)
str = "asiabscassdsasikkasil"
res1 = re.findall("(a)(s)i",str)
print(res1)

2.search、match
对于search和match俩个方法在使用()后也是优先展示()中的内容。
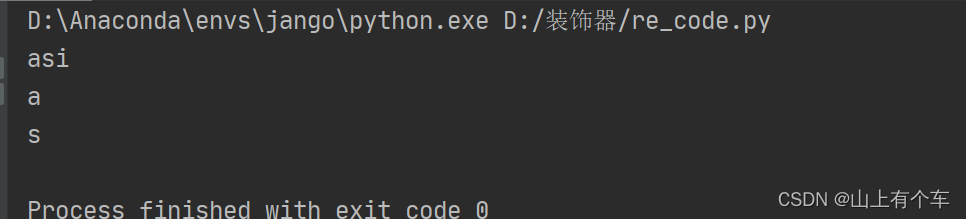
res2 = re.search("(a)(s)i", str)
print(res2.group())
print(res2.group(1))
print(res2.group(2))
四、re模块别名的使用
re3 = re.search("a(?P<s1>s)i", str)
print(re3.group("s1"))
print(re3.group())
print(re3.group(1))

使用(?P<分组名>需要匹配的)可以获得带别名的分组
使用group(“分组名”)可以获取到对应的匹配结果
一个()对应一个分组,有多个分组时用group(“分组名”),获取到对应的分组结果
re.search(“a(?Ps)i”, str) 在这里分组名为s1,只有一个分组,所以group(2)无法使用,不填默认全部分组结果,1为第一个()的匹配结果分组。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









