







 这篇2022年的UCBerkeley论文介绍了DiffusionTransformers(DiT),一种使用Transformer改进的扩散模型,它在图像生成方面实现了当时最佳性能。论文探讨了Transformer在扩散模型中的应用,以及DiT如何通过简单的扩展和优化超过传统架构,如U-Net。研究还涉及了不同条件加入方式对模型性能的影响和计算效率的分析。
这篇2022年的UCBerkeley论文介绍了DiffusionTransformers(DiT),一种使用Transformer改进的扩散模型,它在图像生成方面实现了当时最佳性能。论文探讨了Transformer在扩散模型中的应用,以及DiT如何通过简单的扩展和优化超过传统架构,如U-Net。研究还涉及了不同条件加入方式对模型性能的影响和计算效率的分析。
Paper name
Scalable Diffusion Models with Transformers (DiT)
Paper Reading Note
Paper URL: https://arxiv.org/abs/2212.09748
Project URL: https://www.wpeebles.com/DiT.html
Code URL: https://github.com/facebookresearch/DiT
TL;DR
- 2022 年 UC Berkeley 出品的论文,将 transformer 应用于 diffusion 上实现了当时最佳的生成效果。DiT 论文作者也是 OpenAI 项目领导者之一,该论文是 Sora 的基础工作之一。
Introduction
背景
- transformer 在自回归模型中得到了广泛应用,但在其他生成模型框架中的采用较少。例如,扩散模型已经处于近期图像级生成模型进展的前沿;然而,它们都采用了卷积 U-Net 架构作为默认的主干选择
- 本文展示了 U-Net 的归纳偏置对扩散模型的性能并非至关重要,可以替换为 transformer
本文方案
- 提出了基于 transformer 的 diffusion 模型 Diffusion Transformers (简称 DiTs)。该架构具有良好的可扩展性,即网络复杂度(以Gflops衡量)与样本质量(以FID衡量)之间存在强相关性。通过简单地放大 DiT 并训练一个具有高容量主干的 LDM,能够在类条件 256 × 256 ImageNet 生成基准测试上达到 2.27 FID 的最新结果

Methods
整体设计思路
- 使用 Latent diffusion models(LDM) + Classifier-free guidance + transformer + VAE (Conv) 架构设计,从下图可以看出该设计的优势,左图显示有 scaling law,右图显示 LDM 相比于 pixel space diffusion 模型 ADM 有优势,不仅精度更高,训练计算量也更低
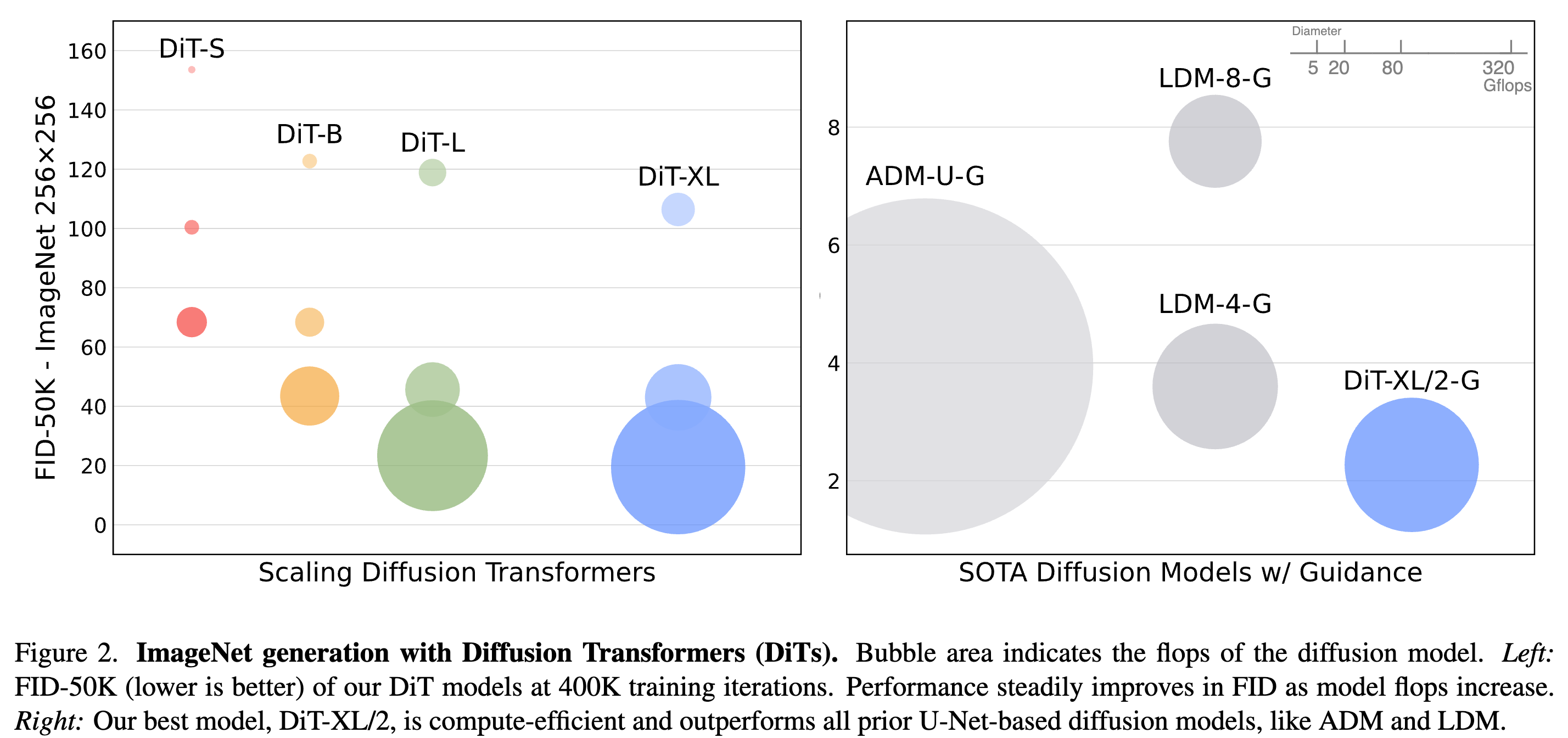
Diffusion Transformers
- DiT 基于 ViT 修改得到,整体架构如下图所示:DiT block 通过区分 condition 的添加方式分为三种设计思路,分别是通过 adaLN (或 adaLN-Zero),cross-attention 或 In-Context
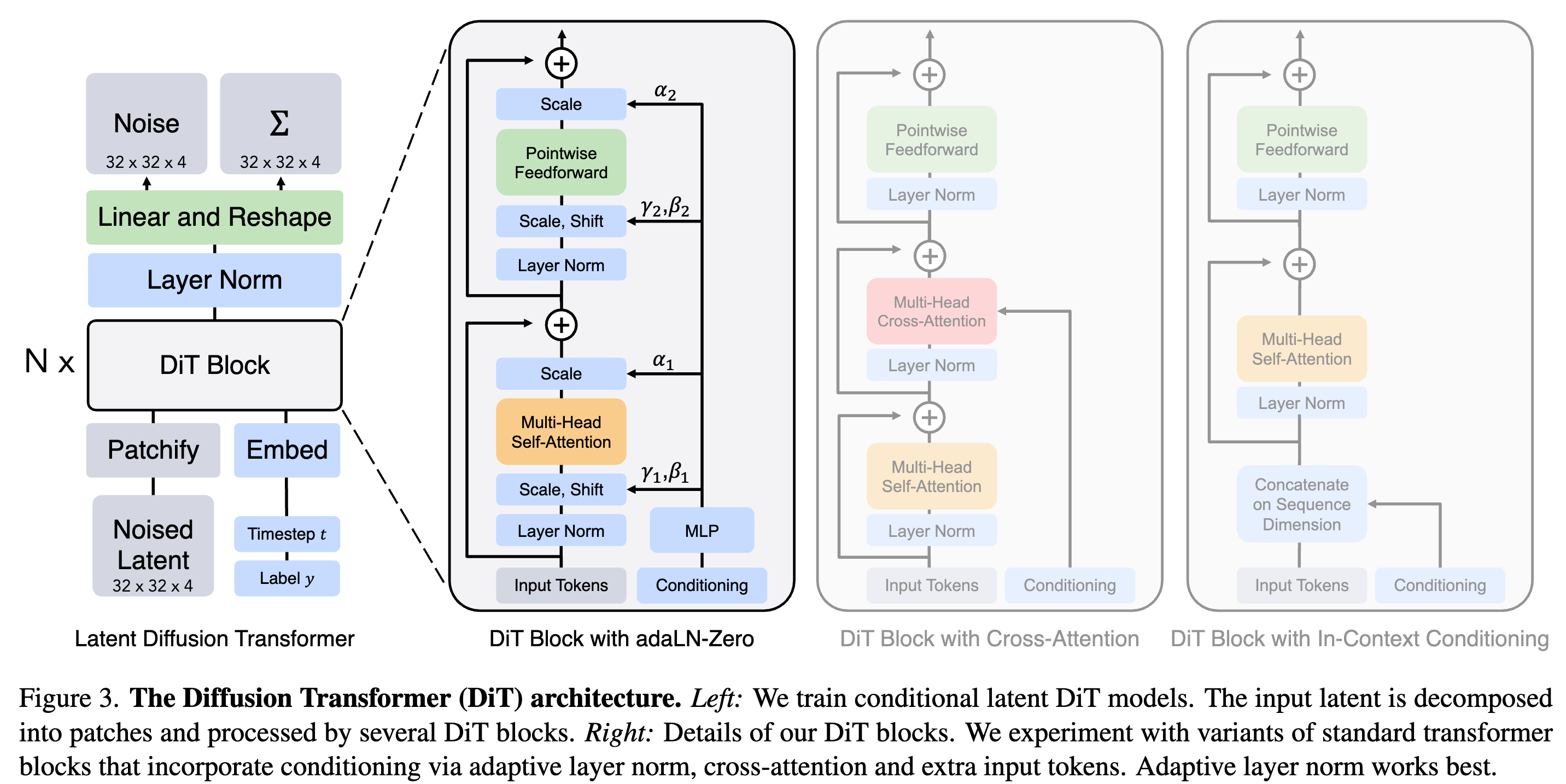
DiT 前向过程的各个模块
-
Patchify:DiT 的输入是图像的空间表示 z(对于 256×256×3 的图像,z 的形状为 32×32×4)。DiT的第一层是 “patchify”,它通过将输入中的每个补丁线性嵌入,将空间输入转换成一系列 T 个 token,每个 token 的维度为 d。在执行 patchify 之后,我们对所有输入 token 应用标准的 ViT 基于频率的位置嵌入(正弦-余弦版本)。由 patchify 创建的 token 数量 T 由补丁大小超参数 p 决定。如下图所示,将 p 减半会使 T 增加四倍,因此至少使整个 transformer Gflops 增加四倍。DiT 中主要实验了 p = 2, 4, 8
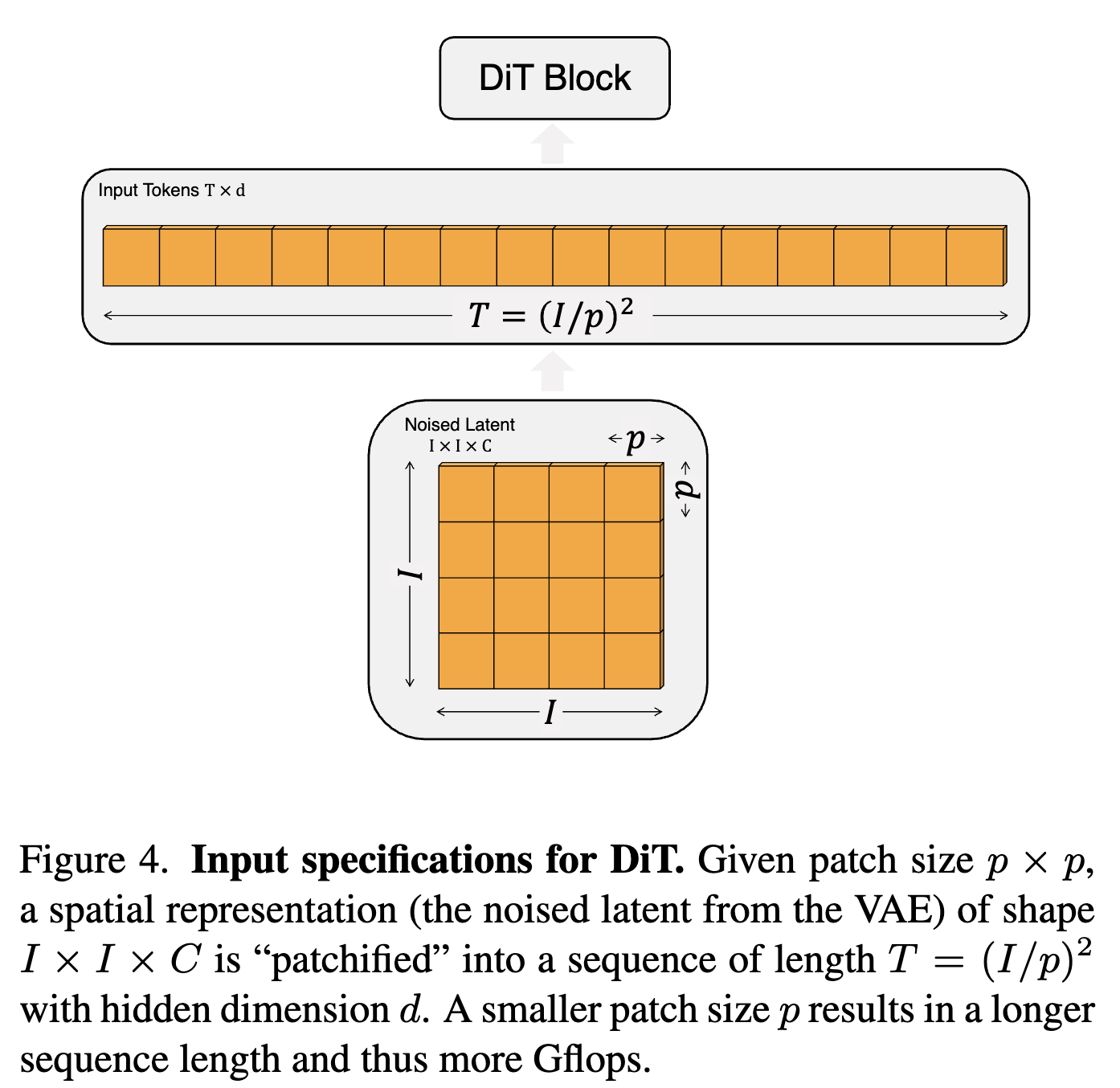
-
DiT block:如整体框架图中所示,根据 condition 加入的不同方式分为以下四种设计思路
- 上下文条件化。我们简单地将 t 和 c 的向量嵌入作为输入序列中的两个额外 tokens 附加上去,对待它们与图像 tokens 没有区别。这与 ViT 中的 cls tokens 类似,它允许我们无需修改就使用标准的 ViT 模块。在最后一个模块之后,我们从序列中移除条件化 tokens。这种方法对模型的新 Gflops 增加可以忽略不计。
- 交叉注意力模块。我们将 t 和 c 的嵌入 concat 成一个长度为二的序列,与图像 token 序列分开。transformer 模块被修改为在多头自注意力模块后面增加一个额外的多头交叉注意力层,类似于 Attention is All you need 中的原始设计,也类似于 LDM 用于条件化类别标签的设计。交叉注意力对模型的 Gflops 增加最多,大约增加了 15% 的开销。
- 自适应层归一化(adaLN)模块。在 GANs 和具有 UNet 骨干的扩散模型中广泛使用自适应归一化层之后,我们探索了用自适应层归一化(adaLN)替换 transformer 模块中的标准归一化层。adaLN 并不是直接学习维度规模的缩放和偏移参数 γ 和 β,而是从 t 和 c 的嵌入向量之和中回归得到它们。在我们探索的三种模块设计中,adaLN 增加的 Gflops 最少,因此是最计算高效的。它也是唯一一个限制对所有 tokens 应用相同函数的条件化机制。
- adaLN-Zero 模块。之前的 ResNets 工作发现,将每个残差块初始化为恒等函数是有益的。例如,在监督学习环境中,将每个块中最后的批量归一化缩放因子 γ 零初始化可以加速大规模训练。扩散 U-Net 模型使用了类似的初始化策略,在任何残差连接之前零初始化每个块中的最终卷积层。我们探索了对 adaLN DiT 模块的修改,它做了同样的事情。除了回归 γ 和 β,我们还回归了在 DiT 模块内的任何残差连接之前作用的 dimension-wise 的缩放参数 α。初始化 MLP 以输出所有 α 为零向量;这将完整的 DiT 模块初始化为恒等函数。与标准的 adaLN 模块一样,adaLNZero 对模型的 Gflops 增加可以忽略不计。
-
Model size
- 使用四种配置:DiT-S、DiT-B、DiT-L 和 DiT-XL。它们涵盖了从 0.3 到 118.6 Gflops 不同范围的模型大小和浮点运算分配,使我们能够评估扩展性能。下表提供了配置的详细信息。

- 使用四种配置:DiT-S、DiT-B、DiT-L 和 DiT-XL。它们涵盖了从 0.3 到 118.6 Gflops 不同范围的模型大小和浮点运算分配,使我们能够评估扩展性能。下表提供了配置的详细信息。
-
Transformer 解码器
- 在最后的 DiT 模块之后,需要将图像 tokens 序列解码成输出噪声预测和输出对角协方差预测。这两个输出的形状等于原始的空间输入。我们使用标准 linear 解码器来完成这一任务;我们应用最终的层归一化(如果使用 adaLN 则为自适应的)并将每个 token 线性解码成一个 p×p×2C 的张量,其中 C 是输入到 DiT 的空间输入中的通道数。最后,我们将解码后的 tokens 重新排列成它们原始的空间布局,以得到预测的噪声和协方差。
Experiments
训练配置
- ImageNet, 256x256 或 512x512 训练
- AdamW, no weight decay
- constant lr: 1 x 10−4
- batch size: 256
- EMA: decay 0.9999
VAE/Diffusion
- Stable Diffusion 中的 VAE,下采样倍数为 8: 256 × 256 × 3 -> 32 × 32 × 4.
- tmax=1000
- linear variance schedule: 1e-4 -> 2e-2
评测指标
- FID, FID-50k,250 DDPM sampling step
DiT block 消融
- condition 的加入方式很影响精度:adaLN-Zero 精度最佳,说明权重初始化方式也很重要(让 DiT 的 block 初始化为 identity 函数)。
- 计算量:in-context (119.4 Gflops), cross-attention (137.6 Gflops), adaptive layer norm (adaLN, 118.6 Gflops) or adaLN-zero (118.6 Gflops)
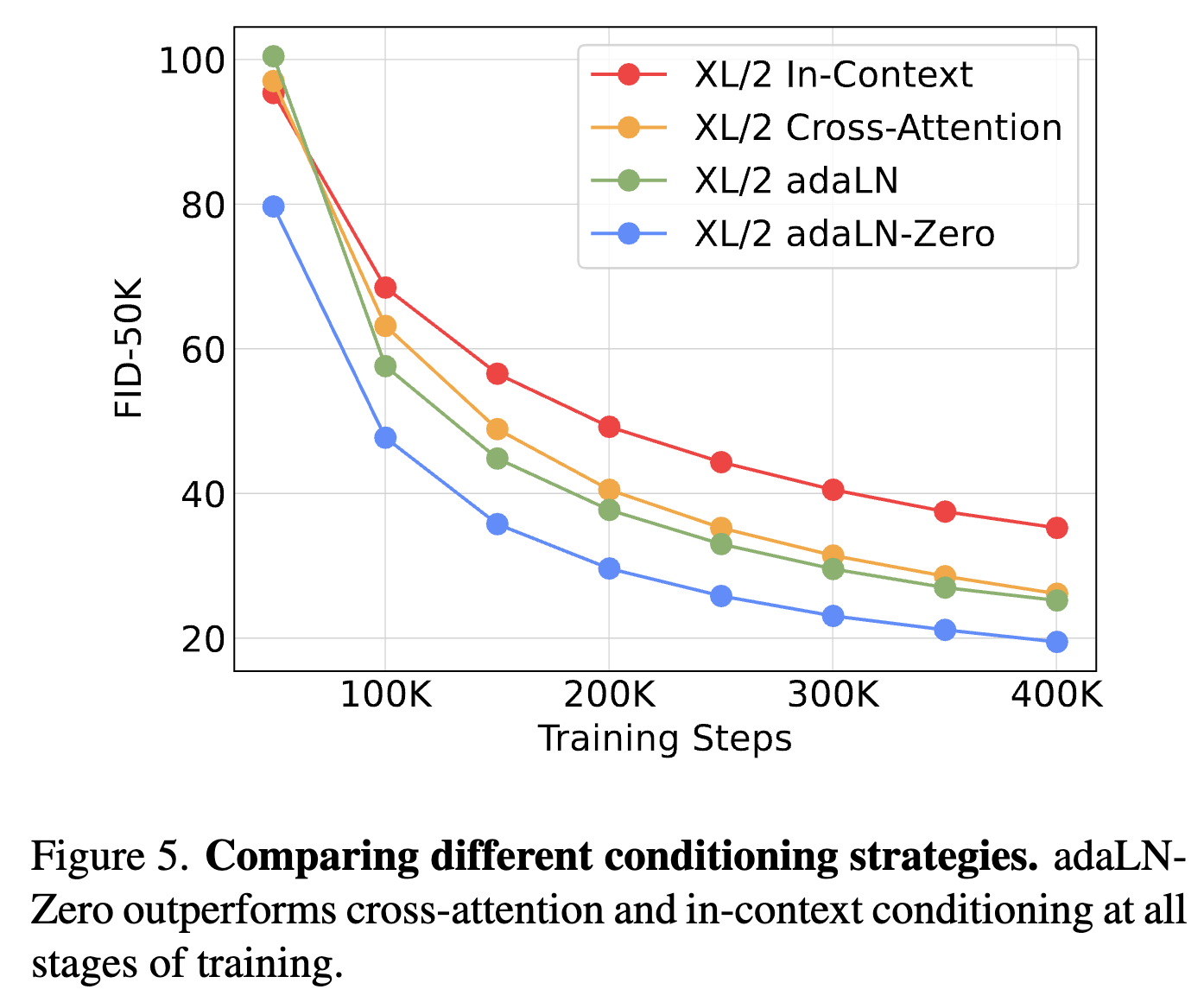
scaling 分析
-
提升模型计算量稳定涨点
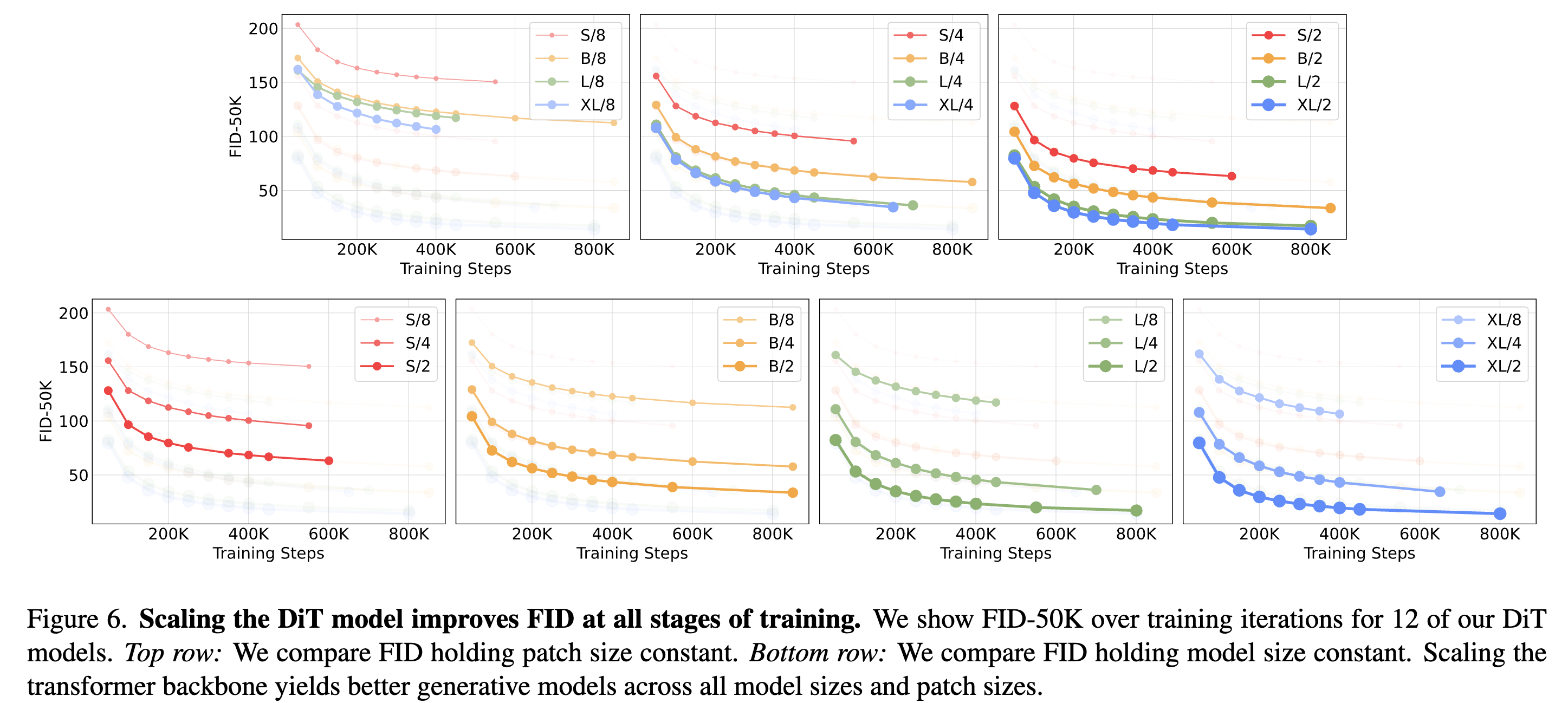
-
只要模型计算量接近,FID 就接近。
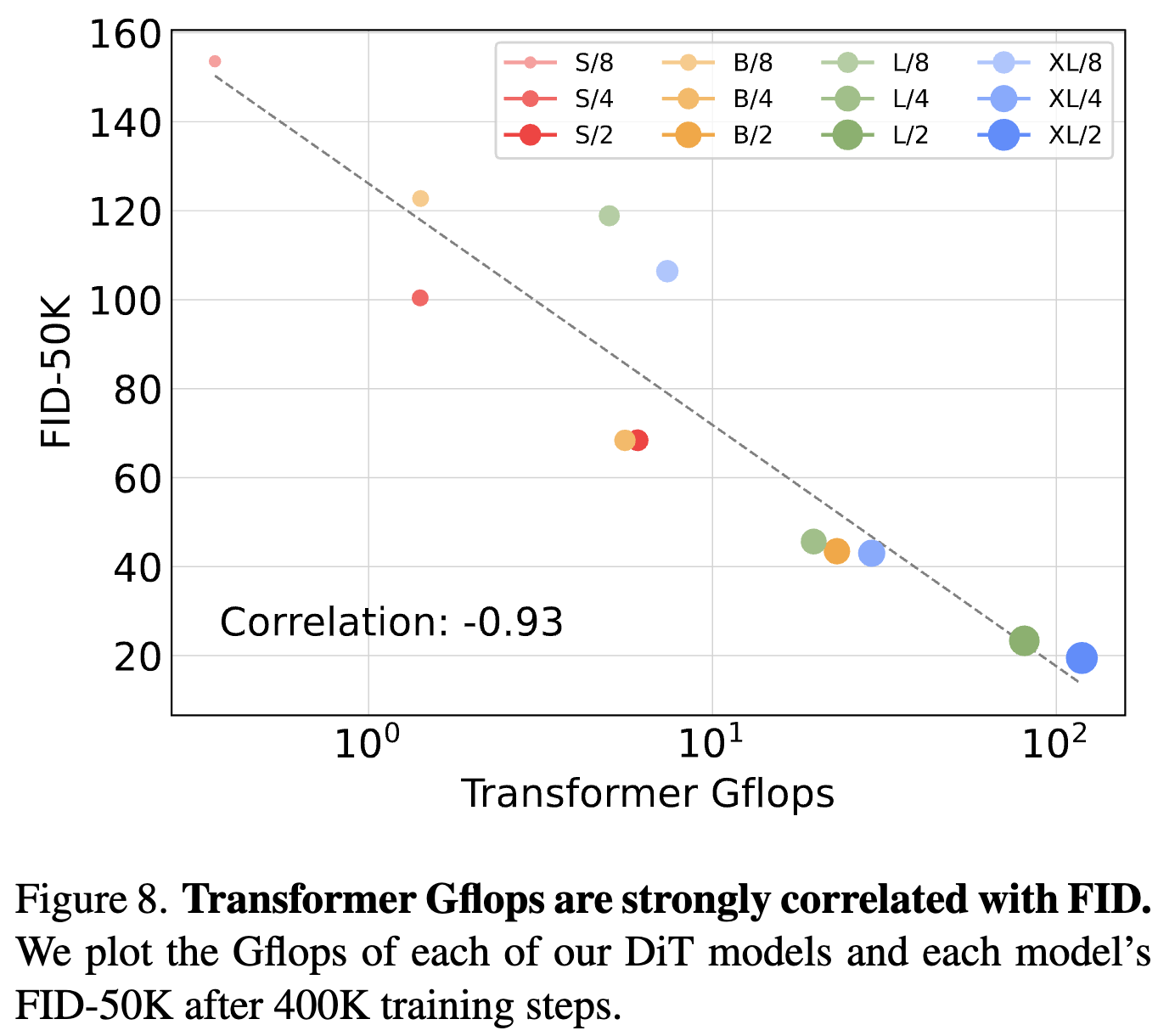
训练效率
- 更大的 DiT 模型计算效率更高。
- 训练计算量的评估方式:Gflops · batch size · training steps · 3。因子 3 大致近似于反向传播的计算量是前向传播的两倍。发现,即使训练时间更长,小型 DiT 模型最终相对于训练步数更少的大型 DiT 模型而言,在计算上变得效率低下。同样,我们发现,除了 patch 大小不同之外,其他都相同的模型即使在控制了训练 Gflops 的情况下,也有不同的性能表现。例如,在大约
1
0
10
10^{10}
1010 Gflops 之后,XL/4 的性能被 XL/2 超越。
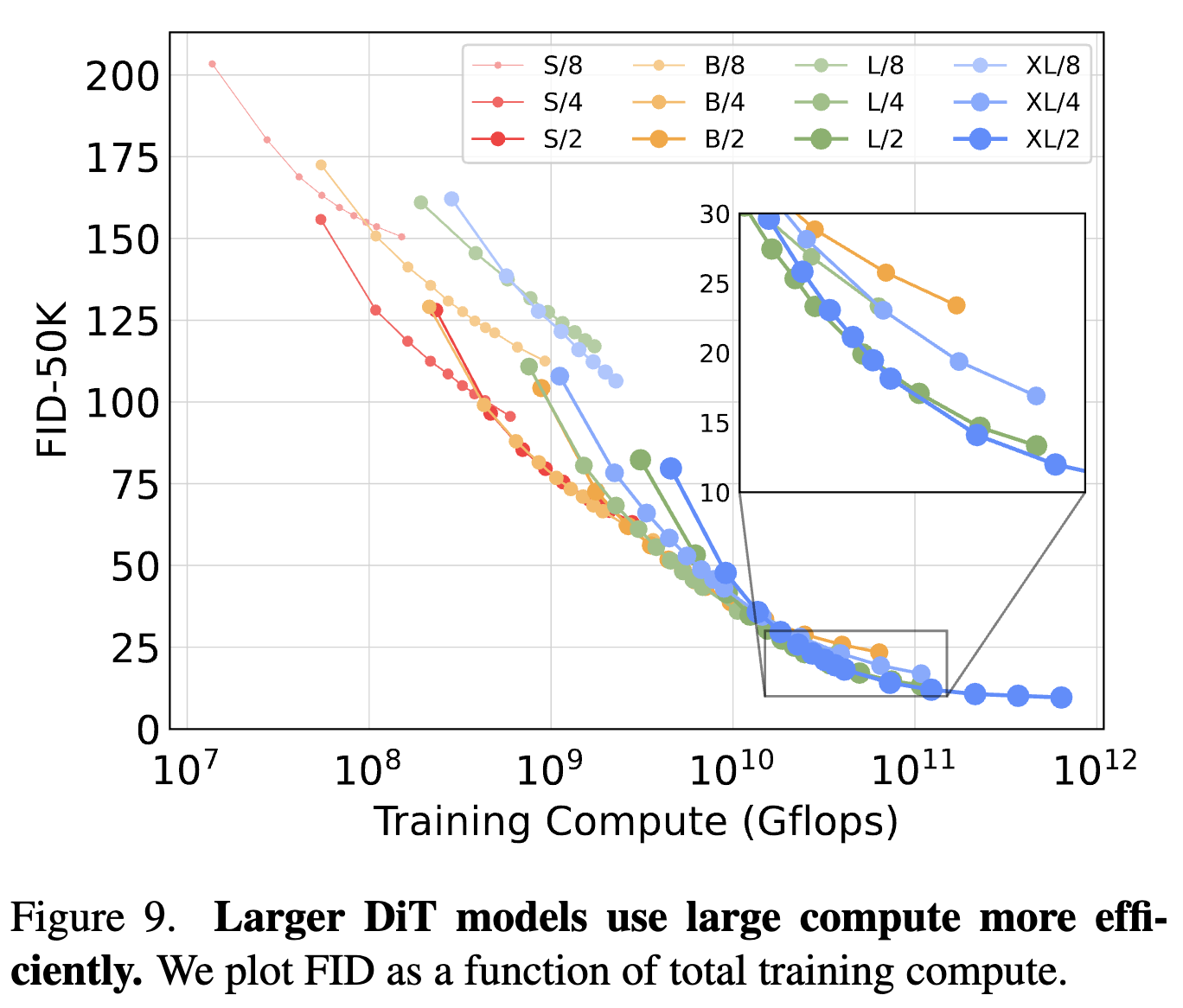
- 训练计算量的评估方式:Gflops · batch size · training steps · 3。因子 3 大致近似于反向传播的计算量是前向传播的两倍。发现,即使训练时间更长,小型 DiT 模型最终相对于训练步数更少的大型 DiT 模型而言,在计算上变得效率低下。同样,我们发现,除了 patch 大小不同之外,其他都相同的模型即使在控制了训练 Gflops 的情况下,也有不同的性能表现。例如,在大约
1
0
10
10^{10}
1010 Gflops 之后,XL/4 的性能被 XL/2 超越。
可视化效果
- 提升模型计算量可视化效果明显提升

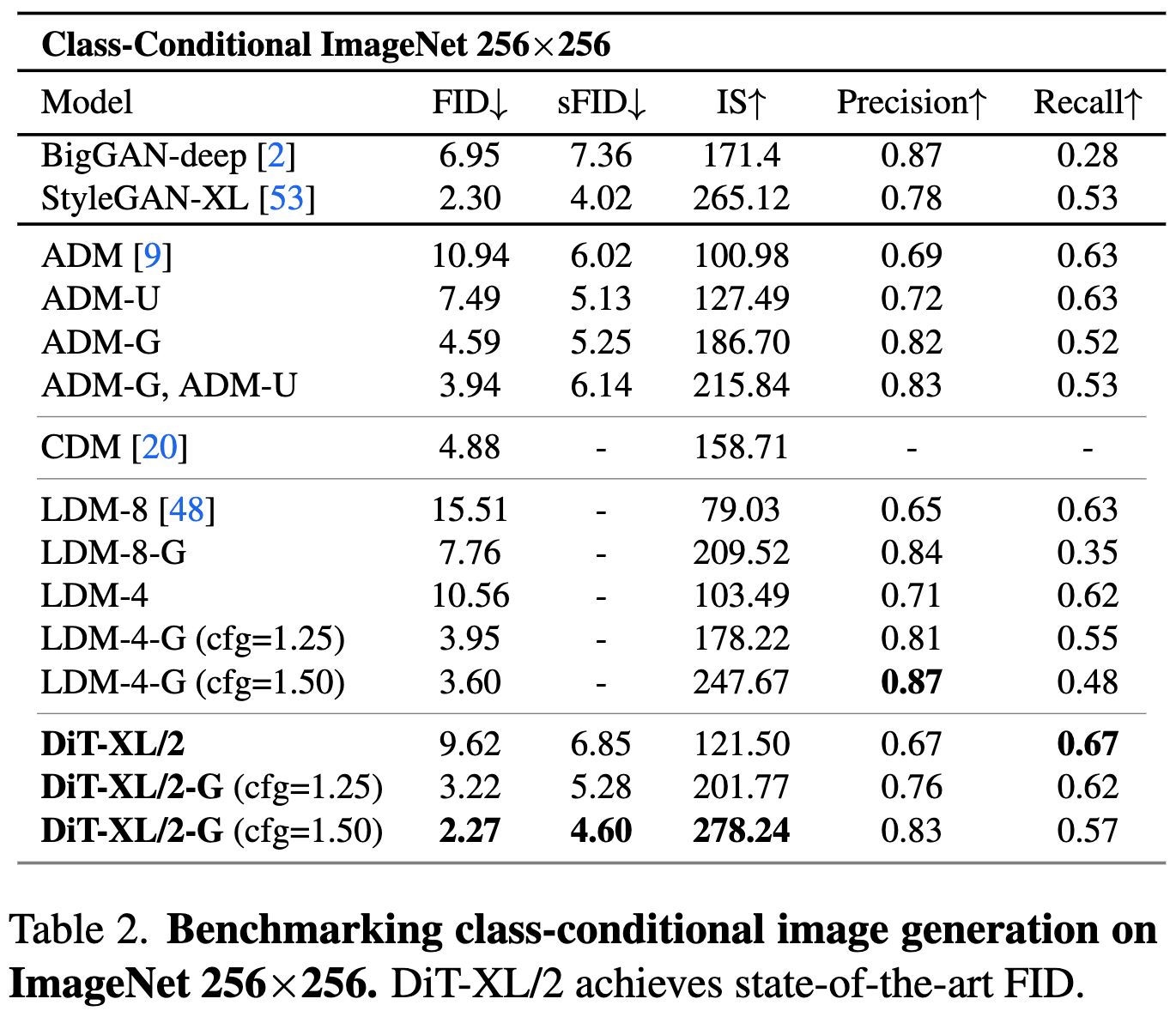
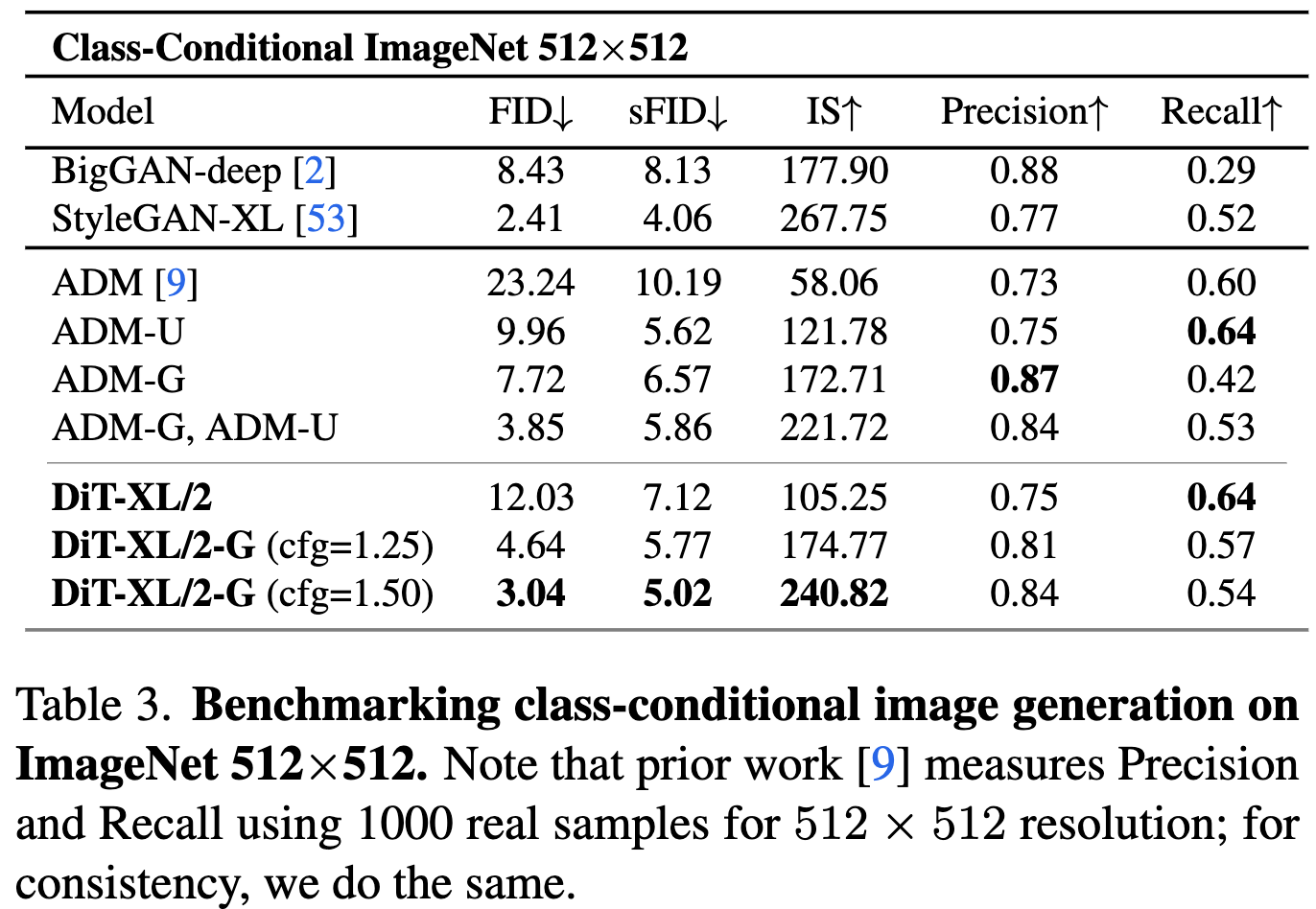
class condition 定量分析
- 达到 sota 效果,比之前的 sota StyleGAN-XL 精度更高
增加模型参数量 or 增加 sampling 步数
- 扩散模型的独特之处在于可以通过增加生成图像时的采样步骤来在训练后使用额外的计算资源。
- 研究了在使用更多采样计算的情况下,较小模型计算的 DiT 是否能够超越较大的模型。结论是增加采样计算的规模无法弥补模型计算能力的不足。

Thoughts
- 符合 scaling law 的简洁架构才是王道。scaling law 在 DiT 这的实验效果极佳,和 OpenAI 价值观相符,这应该是作为 Sora 基础工作之一的原因
- condition 的加入方式可能还需要更多的 class condition 之外的消融实验,比如 image condition、text condition 等



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









