







Paper name
OpenAI Sora 技术报告:Video generation models as world simulators
Paper Reading Note
- 官网:https://openai.com/sora

- 技术报告:https://openai.com/research/video-generation-models-as-world-simulators
TL;DR
- 2024 OpenAI 的视频生成工作 Sora。探索在视频数据上进行大规模生成模型的训练。具体来说,作者团队在多种持续时间(duration)、分辨率 (resolution) 和长宽比 (aspect ratio) 的视频和图像上训练文本条件扩散模型。利用了一个在视频和图像潜在编码的时空补丁 (spacetime patches) 上运行的 transformer 架构。所提出的 Sora 能够生成一分钟高保真度的视频。实验结果表明,扩展视频生成模型是建立通用物理世界模拟器的有前途的途径。
Introduction
- 技术报告着重介绍两个方面(不包括模型和训练细节):
- 将各种类型的视觉数据转换为统一表示的方法,以实现大规模生产模型的训练
- 对 Sora 的能力和局限性进行定性评估
背景
- 之前也有许多对视频数据进行建模的方法,比如 RNN/GAN/AR transformer/diffusion 等。这些工作通常专注于视觉数据的一小部分类别,较短的视频,或者固定大小的视频。Sora 是一个通用的视觉数据模型——它可以生成跨越不同持续时间、长宽比和分辨率的视频和图像,最高可达一分钟的高清视频。
本文方案
将视觉数据转换为补丁 (Turning visual data into patches)
- LLM 范式的成功得益于优雅地统一了文本、代码、数学和各种自然语言多样化的文本 token。Sora 使用视觉补丁 (visual patches) 来对标文本 token
- 补丁已被证明是视觉数据模型的有效表示。作者认为补丁是一种高度可扩展和有效的表示方法,适用于对各种类型的视频和图像进行生成模型训练。首先将视频压缩成低维潜在空间,然后将表示分解成时空补丁 (spacetime patches)
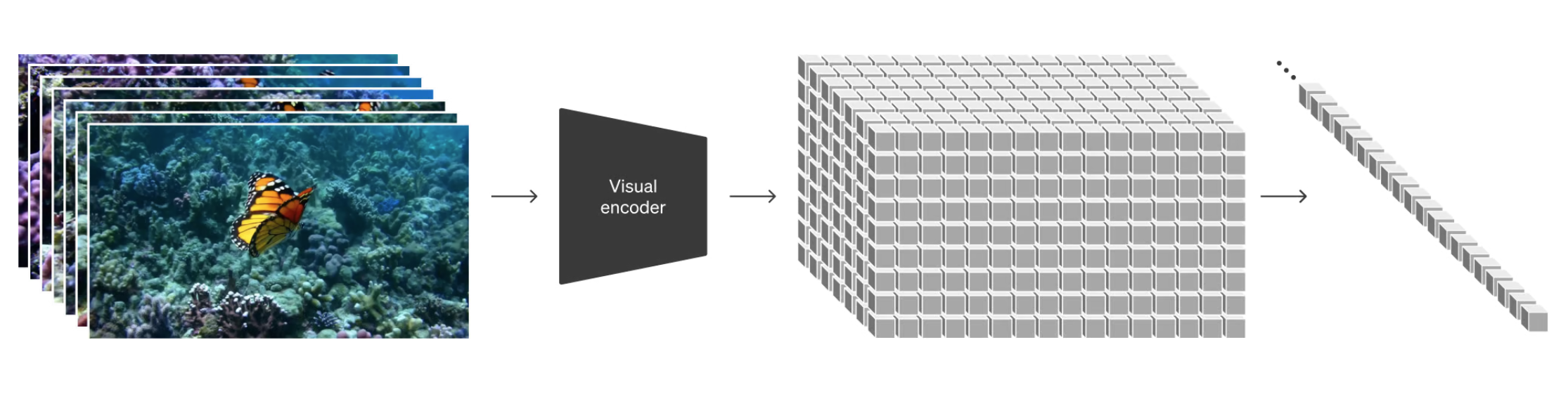
视频压缩网络
- 训练了一个网络,可以降低视觉数据的维度。这个网络以原始视频作为输入,并输出一个在时间和空间上都经过压缩的潜在表示。Sora 在经过这种压缩的潜在空间中进行训练,并生成视频。我们还训练了一个相应的解码器模型,将生成的潜在表示映射回像素空间。
重头戏:扩大规模(scaling)
- Sora是一个扩散模型,对于给定输入的嘈杂补丁(以及类似文本提示的调节信息),它被训练来预测原始的“干净”补丁。重要的是,Sora 是一个扩散 transformer。transformer 在各种领域展现出了显著的可扩展性,包括语言建模、计算机视觉和图像生成。

- 从下图可以看出不错的可扩展性。下图展示了固定随机种子和输入的比较效果。随着训练计算量的增加,样本质量显著提高

可变的视频时长,分辨率,长宽比
- 之前工作一般在固定的时长和分辨率上训练,比如 256px 的 4s 视频上,本文发现在原始尺寸上训练有很多好处
- Sora 可以对宽屏 1920x1080p 视频、竖屏 1080x1920 视频以及两者之间的视频进行采样。这使得Sora可以直接针对不同设备的原生宽高比创建内容。这也使我们能够在较低分辨率下快速原型设计内容,然后再以全分辨率生成,而且都使用同一个模型。

- 从实验中发现,以原始宽高比训练视频可以改善构图和画面组成。在正方形裁剪训练的模型(左侧)有时会生成只有部分主体出现在画面中的视频。相比之下,来自Sora的视频(右侧)具有更好的构图。

- Sora 可以对宽屏 1920x1080p 视频、竖屏 1080x1920 视频以及两者之间的视频进行采样。这使得Sora可以直接针对不同设备的原生宽高比创建内容。这也使我们能够在较低分辨率下快速原型设计内容,然后再以全分辨率生成,而且都使用同一个模型。
自然语言理解
- 训练文本到视频生成系统需要大量具有相应文本标题的视频。将 DALL·E3 中引入的重新字幕 (re-captioning) 技术应用到视频中。首先训练一个高度描述准确性的 caption 模型,然后使用它为我们的训练集中的所有视频生成文本 caption。我们发现,基于高度描述准确性的视频标题进行训练可以提高文本的准确性以及视频的整体质量。
- 与DALL·E 3 类似,我们还利用 GPT 将用户简短提示转化为更详细的 caption,然后将其发送到视频模型。这使得 Sora 能够生成高质量的视频,准确地遵循用户提示。
提示支持图像和视频
- 官网的所有结果都是基于文本提示得到的,同时也支持图像和视频进行提示。方便支持图像视频编辑任务:制作完美循环的视频,为静态图像添加动画,将视频向前或向后延长时间等
图像生成
- Sora 也支持图像生成:通过在一个帧的时间范围内将高斯噪声的补丁排列在空间网格中来实现这一点。该模型可以生成不同尺寸的图像,分辨率高达2048x2048。

涌现出的仿真能力
- 在大规模训练时,视频模型表现出许多有趣的新兴能力。这些能力使 Sora 能够模拟物理世界中人、动物和环境的一些方面。这些特性是在没有任何明确的归纳偏差(如3D、物体等)的情况下出现的,它们纯粹是 scaling 后的现象。
- 3D 一致性。Sora 能够生成具有动态摄像机运动的视频。随着摄像机的移动和旋转,人物和场景元素在三维空间中保持一致地移动。
- 长距离一致性和对象永恒性。视频生成系统面临的重要挑战之一是在采样长视频时保持时间上的一致性。我们发现,Sora通常能够有效地建模短期和长期依赖关系,尽管并非总是如此。例如,我们的模型可以在人、动物和物体被遮挡或离开画面时仍然保持它们的存在。同样,它可以在单个样本中生成同一角色的多个镜头,并在整个视频中保持它们的外观。
- 与世界互动。索拉有时可以模拟会以简单的方式影响世界状态的行为。例如,画家可以在画布上留下新的笔触,这些笔触会随着时间的推移而保留下来,或者一个人可以吃掉一个汉堡并留下咬痕。
- 模拟数字世界。Sora还能够模拟人工过程 - 一个例子是视频游戏。Sora可以同时使用基本策略控制Minecraft中的玩家,同时以高保真度渲染世界及其动态。这些能力可以通过提示Sora提及“Minecraft”来 zero-shot 地引出。
模型局限点
- 当前模型局限点:
- 它可能在准确模拟复杂场景的物理过程方面遇到困难,并且可能无法理解特定的因果关系实例。例如,一个人可能会咬一口饼干,但之后饼干上可能没有咬痕。
- 该模型还可能混淆提示的空间细节,例如,左右混淆,并且可能在描述随时间发生的事件的细节方面遇到困难,比如跟随特定的摄像机轨迹。


















 1641
1641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









