







Paper name
Consistent Video Depth Estimation
Paper Reading Note
URL: https://arxiv.org/pdf/2004.15021.pdf
代码 URL:https://github.com/facebookresearch/consistent_depth
TL;DR
SIGGRAPH 2020 的文章,提出了一种基于视频的重建方案,结合基于深度学习的深度估计方法及传统的基于几何约束的方法,来得到准确和一致的深度;具体采用的方法是在测试时对单帧深度估计网络进行 finetune,让模型学会满足特定场景的几何约束,同时也保持合成合理深度的能力
Introduction
- 基于手持的相机或手机采集到的视频进行场景的 3D 重建有重要的利用价值,比如可以进行视频特效处理、场景三维建模,然而难度也很大,典型问题有低纹理区域、重复纹理、遮挡以及视频采集可能带来的高噪声、抖动、运动模糊、 卷帘变形(rolling shutter deformations)、相邻帧 baseline 过小、运动物体等问题,所以传统方法一般效果都不太好,比如下图的 b (部分区域深度缺失)和 c(几何不连续、抖动的深度) 所示

- 传统重建方法(如 colmap)结合稀疏 sfm 和稠密 multi-view stereo,因为基线匹配中的噪声,通常会加入启发式平滑先验,这通常会导致受影响区域几何不正确,这些方法往往就直接将低置信度的区域丢弃了(上图b中的空洞)
- 现在基于深度学习的方法在单帧上重建效果较好,能得到稠密的深度图,并且由于是单帧处理,也不会收到视频中运动物体的影响,然而这些方法在处理视频时产生的深度抖动较大,另外也存在不是米制的绝对深度(与绝对深度差一个 scale),这就导致了单帧方法在处理视频时有几何不一致问题。目前已有的视频深度估计方式无论是隐式得基于 RNN 的方法或者基于多视角重建的显式方法,都局限于静态场景建模
- 本文提出了一种基于视频的重建方案,结合基于深度学习的深度估计方法及传统的基于几何约束的方法,来得到准确和一致的深度;具体采用的方法是在测试时对单帧深度估计网络进行 finetune,让模型学会满足特定场景的几何约束,同时也保持合成合理深度的能力
Dataset/Algorithm/Model/Experiment Detail
实现方式
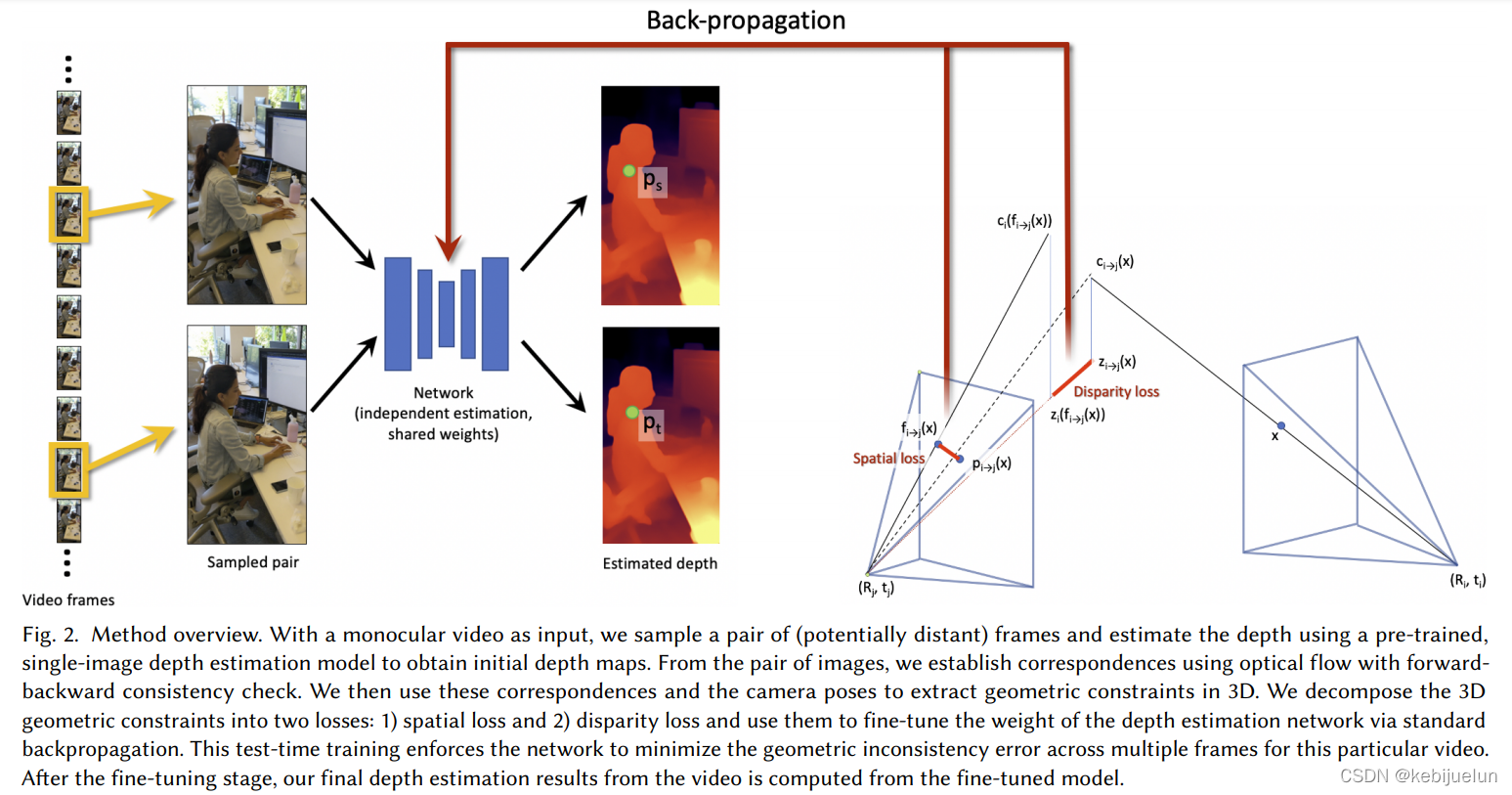 整个 PPL 分为两个阶段:预处理、测试时训练
整个 PPL 分为两个阶段:预处理、测试时训练
- 预处理
- 基于 colmap 进行传统的 SFM 重建,基于 Mask RCNN 过滤场景中的人来提升特征点提取与匹配的准确性,得到相机准确的内参与外参以及场景的稀疏点云
- 基于光流估计不同帧之间的稠密匹配关系
- 测试时训练
- 对单帧深度估计模型进行 finetune,如上图所示,基于不同帧的稠密匹配关系采样匹配帧,将匹配帧送入单帧深度估计网络得到估计的深度图,通过对估计的深度图进行重投影,并对重投影结果的稠密匹配进行对比可以确认估计的深度图是否满足几何一致性,最后设计了 spatial loss 和 disparity loss 来对网络进行 finetune
预处理细节
- scale 匹配: SFM(colmap) 与深度估计网络的 scale 一般是不匹配的,也即两者估计的深度的值域范围不同,这里通过调节 SFM 的 scale 来进行匹配,因为只需要简单在相机内参上乘上一个 sacle,匹配方式为对每张深度图进行中值对齐配准:
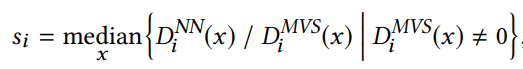
其中 D i N N D_{i}^{NN} DiNN 为深度估计网络得到的深度, D i M V S D_{i}^{MVS} DiMVS 为 colmap 产生的深度, D(x) 代表 pixel x 处的深度- 整体 scale 就是对所有深度图 scale 取平均
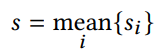
- 对相机内参进行更新
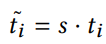
- 整体 scale 就是对所有深度图 scale 取平均
- 匹配帧选取: 因为直接选取所有匹配对是 O(N2) 的时间复杂度,所以这里采用的是对相邻帧及逐步稀疏采样的帧进行光流计算,从而在 O(N) 时间复杂度下处理
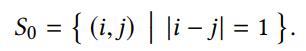
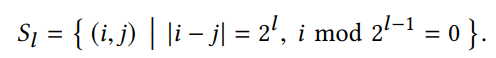
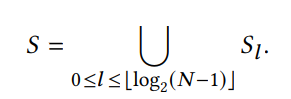
- 光流计算: 这里光流计算需要先基于 homography warp 保证匹配帧之间的重合区域足够多,从而确保光流估计的效果;为了处理运动物体及遮挡问题,这里使用前向后向一致性检查:移除前向-后向误差大于 1 pixel 的像素
- 另外移除 overlap 太小的匹配帧:有效像素匹配小于 20%
测试时训练
- Geometric loss
- 基于光流得到匹配帧 i,j 之间的对应关系
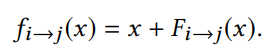
- 将 i 帧中的点基于内参和深度映射到相机坐标系中
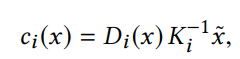
- 将 i 帧相机坐标系中的点通过相机外参转换到 j 帧的相机坐标系中
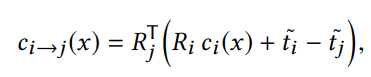
- 将 i 帧中转换到 j 帧的点重新映射会图像坐标系

-
image-space loss(图像空间损失):即对比光流映射得到的图像像素( f i → j ( x ) f_{i \to j}(x) fi→j(x) )与基于重投影得到的像素( p i → j ( x ) p_{i \to j}(x) pi→j(x) )计算 L2 损失
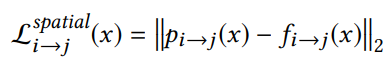
-
disparity loss(视差损失): 约束不同相机坐标系下的视差一致,也即希望同一个空间点在不同帧预测的深度图中深度保持一致(几何一致性)
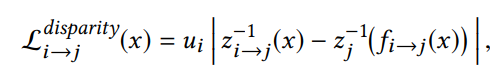
其中 u i u_{i} ui 是 i 帧的焦距, z i z_{i} zi、 z i → j z_{i \to j} zi→j 分别是是将 i 帧相机坐标系与 i 到 j 的 z 分量 (深度)
- 基于光流得到匹配帧 i,j 之间的对应关系
- 整体损失:
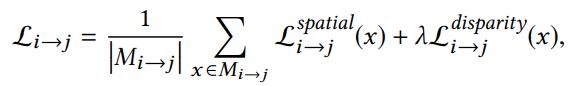
实验结果
- finetune 设置:一般训练 20 epoch,对于 244 帧的视频,在 4 NVIDIA Tesla M40 上需要训练 40 min
自采集数据实验
- 因为现有数据集主要是合成场景,特定场景(自动驾驶),单张图片,静态场景的视频,所以这里使用了自采集的数据集,4个静态场景,3个动态场景
- 注意采集设备是 stereo 相机,后续会利用右目数据及 stereo disparity 进行评测

-
评价指标设定
- Photometric error Ep : 利用左图估计的深度转换为视差,将左图的像素映射到右图上,计算 photometric loss
- 单目深度尺度不确定性是通过将深度与 stereo disparity 的 scale 、shift进行对齐,stereo disparity 是利用了光流网络预测值的水平分量,对齐方式是基于 RANSAC 的线性回归
- Instability Es : 衡量时序帧预测的稳定性,方式是基于 KLT tracker 得到 2D 的 track,基于预测的深度、相机内参、camera pose 映射到 3D 中对比映射点的稳定性,理论上同一个 track 映射到 3D 中应该是一个固定的点(注:这里值计算所有相邻帧的映射偏差)
- Drift Ed:上面的指标 Es 只计算相邻帧的映射偏差,这里会以所有帧映射到 3D 的 track 的协方差矩阵的最大特征值作为评测指标,评测随着时间增加造成的累积误差
- Photometric error Ep : 利用左图估计的深度转换为视差,将左图的像素映射到右图上,计算 photometric loss
-
对比实验结果
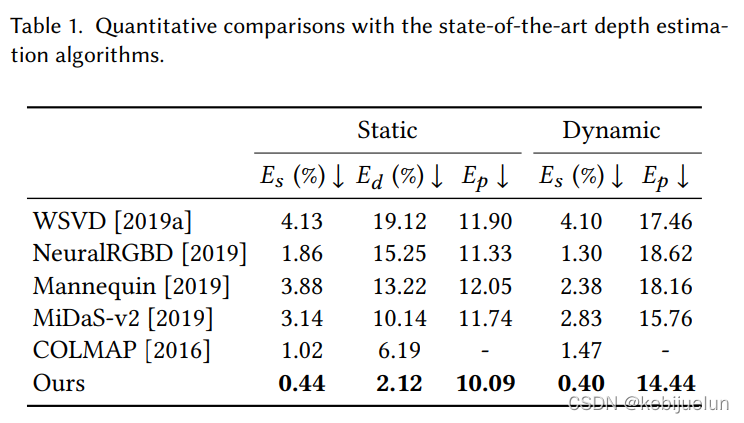
-
消融实验
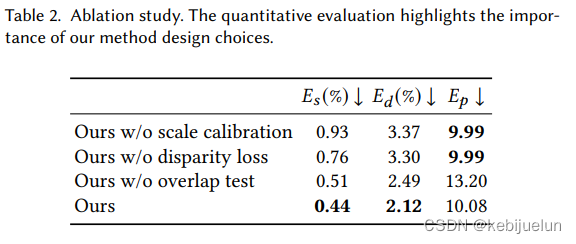
-
仅用相邻帧的效果不如使用长时间约束的好
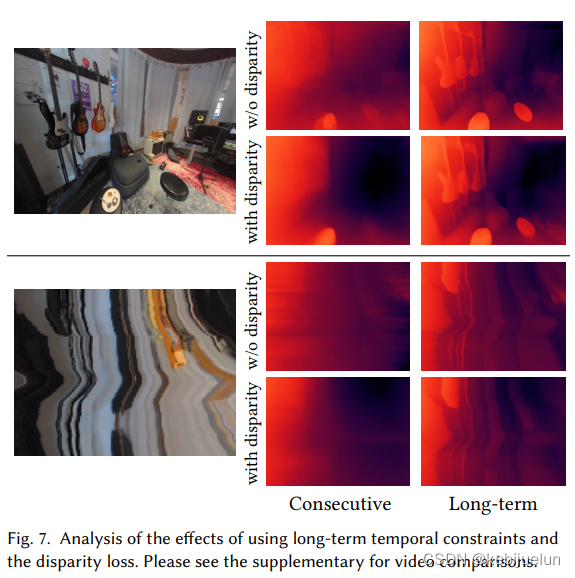
-
有了时序一致性较好的深度,可以支持更好的 CG 合成效果

公开数据集实验
- 可视化(第一列是原图,第二列是通过时空体积的扫描线切片)

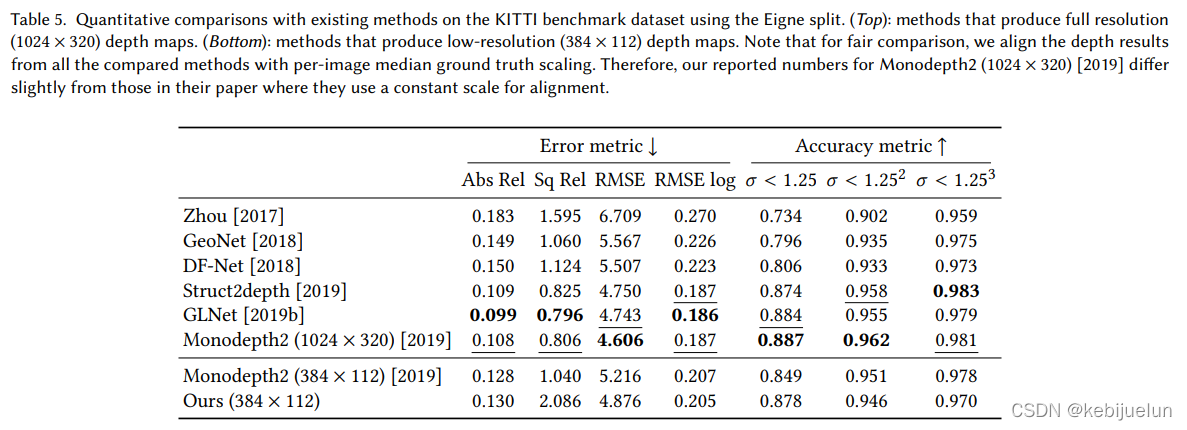
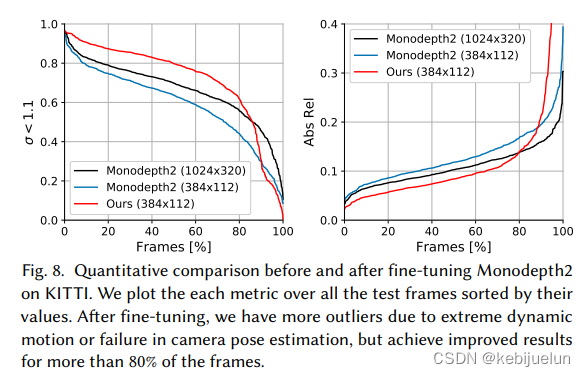
- 公开数据集点一般,据说主要是光流估计不太准(KITTI车前向移动较大),使用 monodepth2 作为基础网络,可以看到也没怎么掉点(作者具体调查发现在 80%的帧都是涨点的,视频可视化效果也是更好,但就是点更低,因为 COLMAP 生成的 camera pose 在动态目标下不够准,所以 finetune 后部分帧效果明显变差)
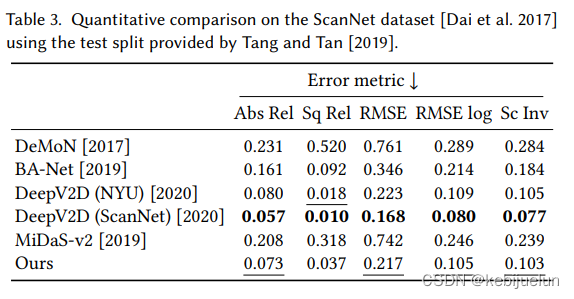
- ScanNet 数据集下可以相比于 baseline 涨点
Thoughts
- 以前的时序一致性约束的根本原理主要是在时序上增加时序一致性的 loss,比如深度估计里面基于 RNN 的隐式一致性约束,或基于光流的显示一致性约束,这里直接希望学习到的时序深度能满足几何空间的一致性约束,显然是更直接有效的约束方式
- 预处理中众多繁琐的操作都是希望测试时训练的数据尽量准确,保证 finetune 时的数据准确性很关键
- 其中 kitti 数据集相比于 pretrain 模型掉点作者给的解释方法值得借鉴,证明了该方法能在 80% 的帧涨点,只是剩下 20% 数据的掉点更严重导致了整体掉点

















 3126
3126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









