CUDA编程(九)
矩阵乘法
在之前我们一直围绕着一个非常简单的求立方和的小程序学习CUDA,从编写到优化,学习了很多,包括CUDA GPU的架构,如何评估程序,并行优化,内存优化,等等,把程序的运行时间从679680304个时钟周期(对于我的显卡是0.853S)最终优化到了133133个时钟周期(对于我的显卡是1.67e-4S),优化的效果还是非常明显的,前后总共加速了5015倍。
不过这个立方和的小程序实际上没有什么实用价值,之前也提到过了,CUDA广泛用于神经网络,计算机视觉这些领域,因为这些领域的算法往往可并行性极强,运算量大,非常适合使用GPU计算,说白了就是有大量的浮点数矩阵计算。
所以接下来我们就想办法用CUDA去并行一个常用的矩阵运算,矩阵加法没什么好说的,所以我们接下来去并行一下矩阵乘法~
矩阵乘法
为了简单起见,我们以方阵为例,矩阵的乘法大家应该都是比较熟悉的,比如两个方阵A,B
C = AB
for(i = 0; i < n; i++)
{
for(j = 0; j < n; j++)
{
C[i][j] = 0;
for(k = 0; k < n; k++)
{
C[i][j] += A[i][k] * B[k][j];
}
}
}
计算的思路还是非常简单清晰的,那么我们如何把这个过程并行呢?
并行矩阵乘法
我们先试着写一下最简单的并行方式,之后再慢慢优化~
现在我们先考虑最核心的核函数,仿照不并行的程序,首先我们需要有AB和C三个浮点数矩阵,还要知道它们的大小,之后还需要计算时间,所以我们核函数的参数就非常明确了:
__global__ static void matMultCUDA(const float* a, const float* b, float* c, int n, clock_t* time){}
我们之前也说了,程序不可能一蹴而就,所以先用最简单的形式写好核函数:
__global__ static void matMultCUDA(const float* a, const float* b, float* c, int n, clock_t* time)
{
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int idx = bid * THREAD_NUM + tid;
const int row = idx / n;
const int column = idx % n;
int i;
clock_t start;
if (tid == 0) time[bid] = clock();
if (row < n && column < n)
{
float t = 0;
for (i = 0; i < n; i++)
{
t += a[row * n + i] * b[i * n + column];
}
c[row * n + column] = t;
}
if (tid == 0)
{
time[bid + blocks_num] = clock();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
注释也写得比较清楚了,我们一开始就是用最简单的形式来完成计算,优化之后再说。下面我们先让这个程序能跑起来。
编写程序
和第一个程序一样,我们先引入需要的库,定义thread数量,方阵的大小,block的数量需要根据矩阵的大小进行计算:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <cuda_runtime.h>
#define THREAD_NUM 256
#define MATRIX_SIZE 1000
int blocks_num = (MATRIX_SIZE + THREAD_NUM - 1) / THREAD_NUM;
然后第一步还是要初始化CUDA,打印设备信息:
打印信息的方法:
//打印设备信息
void printDeviceProp(const cudaDeviceProp &prop)
{
printf("Device Name : %s.\n", prop.name);
printf("totalGlobalMem : %d.\n", prop.totalGlobalMem);
printf("sharedMemPerBlock : %d.\n", prop.sharedMemPerBlock);
printf("regsPerBlock : %d.\n", prop.regsPerBlock);
printf("warpSize : %d.\n", prop.warpSize);
printf("memPitch : %d.\n", prop.memPitch);
printf("maxThreadsPerBlock : %d.\n", prop.maxThreadsPerBlock);
printf("maxThreadsDim[0 - 2] : %d %d %d.\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
printf("maxGridSize[0 - 2] : %d %d %d.\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
printf("totalConstMem : %d.\n", prop.totalConstMem);
printf("major.minor : %d.%d.\n", prop.major, prop.minor);
printf("clockRate : %d.\n", prop.clockRate);
printf("textureAlignment : %d.\n", prop.textureAlignment);
printf("deviceOverlap : %d.\n", prop.deviceOverlap);
printf("multiProcessorCount : %d.\n", prop.multiProcessorCount);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
CUDA初始化的方法:
bool InitCUDA()
{
int count;
cudaGetDeviceCount(&count);
if (count == 0)
{
fprintf(stderr, "There is no device.\n");
return false;
}
int i;
for (i = 0; i < count; i++)
{
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, i);
printDeviceProp(prop);
if (cudaGetDeviceProperties(&prop, i) == cudaSuccess)
{
if (prop.major >= 1)
{
break;
}
}
}
if (i == count)
{
fprintf(stderr, "There is no device supporting CUDA 1.x.\n");
return false;
}
cudaSetDevice(i);
return true;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
下一步要生成我们要计算的矩阵,上个立方和的程序是一个生成大量随机数的程序,这里要随机生成一个浮点数方阵,我们的矩阵采用i * n + j 的方式来表示,所以我们要传入方阵的尺寸。
随机生成矩阵的方法:
void matgen(float* a, int n)
{
int i, j;
for (i = 0; i < n; i++)
{
for (j = 0; j < n; j++)
{
a[i * n + j] = (float)rand() / RAND_MAX + (float)rand() / (RAND_MAX * RAND_MAX);
}
}
}
有了这三个方法,我们其他的工作直接在main中完成就好了:
int main()
{
if (!InitCUDA()) return 0;
float *a, *b, *c, *d;
int n = MATRIX_SIZE;
a = (float*)malloc(sizeof(float)* n * n);
b = (float*)malloc(sizeof(float)* n * n);
c = (float*)malloc(sizeof(float)* n * n);
d = (float*)malloc(sizeof(float)* n * n);
srand(0);
matgen(a, n);
matgen(b, n);
float *cuda_a, *cuda_b, *cuda_c;
clock_t* time;
cudaMalloc((void**)&cuda_a, sizeof(float)* n * n);
cudaMalloc((void**)&cuda_b, sizeof(float)* n * n);
cudaMalloc((void**)&cuda_c, sizeof(float)* n * n);
cudaMalloc((void**)&time, sizeof(clock_t)* blocks_num * 2);
cudaMemcpy(cuda_a, a, sizeof(float)* n * n, cudaMemcpyHostToDevice);
cudaMemcpy(cuda_b, b, sizeof(float)* n * n, cudaMemcpyHostToDevice);
matMultCUDA << < blocks_num, THREAD_NUM, 0 >> >(cuda_a , cuda_b , cuda_c , n , time);
clock_t time_use[blocks_num * 2];
cudaMemcpy(c, cuda_c, sizeof(float)* n * n, cudaMemcpyDeviceToHost);
cudaMemcpy(&time_use, time, sizeof(clock_t)* blocks_num * 2, cudaMemcpyDeviceToHost);
cudaFree(cuda_a);
cudaFree(cuda_b);
cudaFree(cuda_c);
cudaFree(time);
clock_t min_start, max_end;
min_start = time_use[0];
max_end = time_use[blocks_num];
for (int i = 1; i < blocks_num; i++)
{
if (min_start > time_use[i]) min_start = time_use[i];
if (max_end < time_use[i + blocks_num]) max_end = time_use[i + blocks_num];
}
clock_t final_time = max_end - min_start;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
double t = 0;
for (int k = 0; k < n; k++)
{
t += a[i * n + k] * b[k * n + j];
}
d[i * n + j] = t;
}
}
float max_err = 0;
float average_err = 0;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
if (d[i * n + j] != 0)
{
float err = fabs((c[i * n + j] - d[i * n + j]) / d[i * n + j]);
if (max_err < err) max_err = err;
average_err += err;
}
}
}
printf("Max error: %g Average error: %g\n",max_err, average_err / (n * n));
printf("gputime: %d\n", final_time);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
在GPU上计算完成之后,我们又从CPU上计算了一次,注意这里使用的是double,用来提高精度,然后通过与GPU的结果进行做差比较,计算了精度上的差距(最大相对误差和平均相对误差)。
下面是完整程序:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <cuda_runtime.h>
#define THREAD_NUM 256
#define MATRIX_SIZE 1000
const int blocks_num = MATRIX_SIZE*(MATRIX_SIZE + THREAD_NUM - 1) / THREAD_NUM;
void printDeviceProp(const cudaDeviceProp &prop)
{
printf("Device Name : %s.\n", prop.name);
printf("totalGlobalMem : %d.\n", prop.totalGlobalMem);
printf("sharedMemPerBlock : %d.\n", prop.sharedMemPerBlock);
printf("regsPerBlock : %d.\n", prop.regsPerBlock);
printf("warpSize : %d.\n", prop.warpSize);
printf("memPitch : %d.\n", prop.memPitch);
printf("maxThreadsPerBlock : %d.\n", prop.maxThreadsPerBlock);
printf("maxThreadsDim[0 - 2] : %d %d %d.\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
printf("maxGridSize[0 - 2] : %d %d %d.\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
printf("totalConstMem : %d.\n", prop.totalConstMem);
printf("major.minor : %d.%d.\n", prop.major, prop.minor);
printf("clockRate : %d.\n", prop.clockRate);
printf("textureAlignment : %d.\n", prop.textureAlignment);
printf("deviceOverlap : %d.\n", prop.deviceOverlap);
printf("multiProcessorCount : %d.\n", prop.multiProcessorCount);
}
bool InitCUDA()
{
int count;
cudaGetDeviceCount(&count);
if (count == 0)
{
fprintf(stderr, "There is no device.\n");
return false;
}
int i;
for (i = 0; i < count; i++)
{
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, i);
printDeviceProp(prop);
if (cudaGetDeviceProperties(&prop, i) == cudaSuccess)
{
if (prop.major >= 1)
{
break;
}
}
}
if (i == count)
{
fprintf(stderr, "There is no device supporting CUDA 1.x.\n");
return false;
}
cudaSetDevice(i);
return true;
}
void matgen(float* a, int n)
{
int i, j;
for (i = 0; i < n; i++)
{
for (j = 0; j < n; j++)
{
a[i * n + j] = (float)rand() / RAND_MAX + (float)rand() / (RAND_MAX * RAND_MAX);
}
}
}
__global__ static void matMultCUDA(const float* a, const float* b, float* c, int n, clock_t* time)
{
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int idx = bid * THREAD_NUM + tid;
const int row = idx / n;
const int column = idx % n;
int i;
clock_t start;
if (tid == 0) time[bid] = clock();
if (row < n && column < n)
{
float t = 0;
for (i = 0; i < n; i++)
{
t += a[row * n + i] * b[i * n + column];
}
c[row * n + column] = t;
}
if (tid == 0)
{
time[bid + blocks_num] = clock();
}
}
int main()
{
if (!InitCUDA()) return 0;
float *a, *b, *c, *d;
int n = MATRIX_SIZE;
a = (float*)malloc(sizeof(float)* n * n);
b = (float*)malloc(sizeof(float)* n * n);
c = (float*)malloc(sizeof(float)* n * n);
d = (float*)malloc(sizeof(float)* n * n);
srand(0);
matgen(a, n);
matgen(b, n);
float *cuda_a, *cuda_b, *cuda_c;
clock_t* time;
cudaMalloc((void**)&cuda_a, sizeof(float)* n * n);
cudaMalloc((void**)&cuda_b, sizeof(float)* n * n);
cudaMalloc((void**)&cuda_c, sizeof(float)* n * n);
cudaMalloc((void**)&time, sizeof(clock_t)* blocks_num * 2);
cudaMemcpy(cuda_a, a, sizeof(float)* n * n, cudaMemcpyHostToDevice);
cudaMemcpy(cuda_b, b, sizeof(float)* n * n, cudaMemcpyHostToDevice);
matMultCUDA << < blocks_num, THREAD_NUM, 0 >> >(cuda_a , cuda_b , cuda_c , n , time);
clock_t time_use[blocks_num * 2];
cudaMemcpy(c, cuda_c, sizeof(float)* n * n, cudaMemcpyDeviceToHost);
cudaMemcpy(&time_use, time, sizeof(clock_t)* blocks_num * 2, cudaMemcpyDeviceToHost);
cudaFree(cuda_a);
cudaFree(cuda_b);
cudaFree(cuda_c);
cudaFree(time);
clock_t min_start, max_end;
min_start = time_use[0];
max_end = time_use[blocks_num];
for (int i = 1; i < blocks_num; i++)
{
if (min_start > time_use[i]) min_start = time_use[i];
if (max_end < time_use[i + blocks_num]) max_end = time_use[i + blocks_num];
}
clock_t final_time = max_end - min_start;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
double t = 0;
for (int k = 0; k < n; k++)
{
t += a[i * n + k] * b[k * n + j];
}
d[i * n + j] = t;
}
}
float max_err = 0;
float average_err = 0;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
if (d[i * n + j] != 0)
{
float err = fabs((c[i * n + j] - d[i * n + j]) / d[i * n + j]);
if (max_err < err) max_err = err;
average_err += err;
}
}
}
printf("Max error: %g Average error: %g\n",max_err, average_err / (n * n));
printf("gputime: %d\n", final_time);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
运行结果:
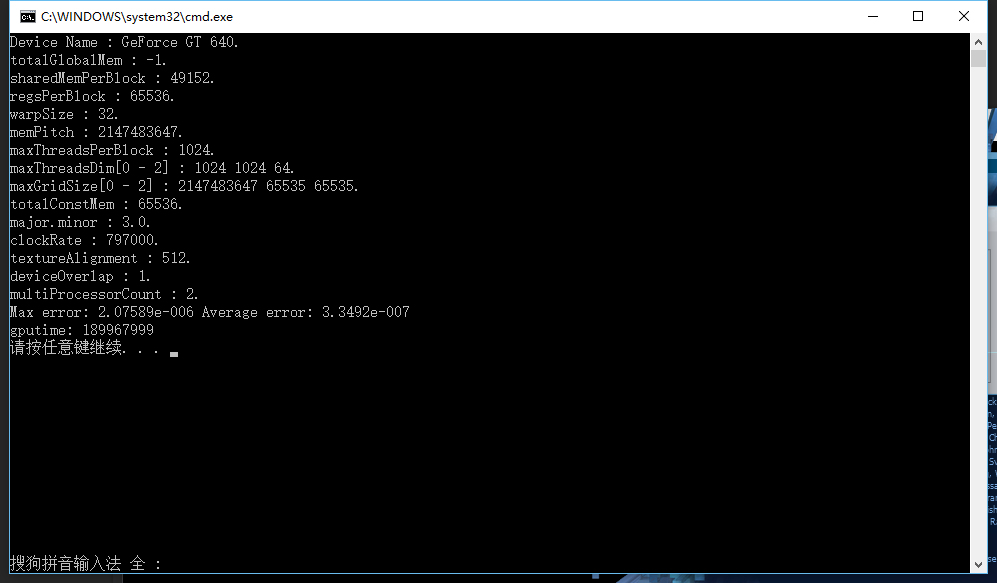
这里我们看到,非常明显的,执行效率相当的低下,用了189967999个周期,大概是0.23秒,这是非常差的一个结果了。
同时精度也非常差,最大相对误差偏高,理想上应该要低于 1e-6。
计算结果的误差偏高的原因是,在 CPU 上进行计算时,我们使用 double(即 64 bits 浮点数)来累进计算过程,而在 GPU 上则只能用 float(32 bits 浮点数)。在累加大量数字的时候,由于累加结果很快会变大,因此后面的数字很容易被舍去过多的位数。
不过我们已经算是完成了程序的初级版本,精度和速度的问题我们慢慢优化。
总结:
这篇博客我们用CUDA完成了矩阵乘法,问题也比较简单,基于上一个立方和程序的经验,完成这个程序也不算太难,但是当然会存在很多问题,毕竟我们还没有开始优化,不过除了速度问题,GPU浮点数运算的精度也成了一个大问题,这些我们后面再一步步解决~
希望我的博客能帮助到大家~
参考资料:《深入浅出谈CUDA》
























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









