










Pyinstaller打包Keras程序
- 前言
- 準備工作
- 打包
- 實驗
- 實驗一:在打包的docker內跑(GPU)
- 實驗二:在打包的機器上的其它docker內跑(CPU)
- 實驗三:在打包的機器上跑(GPU)
- 實驗四:在其它機器上的Ubuntu docker跑(CPU)
- 實驗五:在其他機器上的Ubuntu16.04,CUDA9.0 docker上跑(GPU)
- 實驗六:在其他機器上的Ubuntu16.04,CUDA8.0 docker上跑(GPU)
- 實驗七:在其他機器上的CentOS7,CUDA9.0 docker上跑(失敗)
- 實驗八:在其他機器上的Ubuntu14.04,CUDA8.0 docker上跑(失敗)
- 實驗九:在其他機器上的nvidia-driver docker上跑(失敗)
- 後記
- 結論
- 參考連結
前言
要在Linux系統上將Python檔案打包成可執行檔,參考Freezing Your Code這篇文章,可以使用PyInstaller及bbfreeze這兩個套件。
但是bbfreeze的GitHub官網說明該項目己無人維護,所以這裡選擇PyInstaller。
筆者在Ubuntu 16.04,CUDA V9.0.176的docker環境中將keras的mnist範例打包。把打包好的執行檔拿到其它機器上,相同環境的docker內,發現可以執行成功,GPU也會被調用。
準備工作
筆者先使用keras的mnist範例來試:
'''Trains a simple convnet on the MNIST dataset.
Gets to 99.25% test accuracy after 12 epochs
(there is still a lot of margin for parameter tuning).
16 seconds per epoch on a GRID K520 GPU.
'''
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
import numpy as np
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, split between train and test sets
# (x_train, y_train), (x_test, y_test) = mnist.load_data()
data = np.load("mnist.npz")
x_train, y_train, x_test, y_test = data['x_train'], data['y_train'], data['x_test'], data['y_test']
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
筆者將這一行:
(x_train, y_train), (x_test, y_test) = mnist.load_data()
改為:
data = np.load("mnist.npz")
x_train, y_train, x_test, y_test = data['x_train'], data['y_train'], data['x_test'], data['y_test']
這是希望打包後的可執行檔不要從網上下載數據,而是直接使用執行路徑下的mnist.npz。
首先試著執行mnist.py檔:
# 首先切換到mnist.npz所在的路徑
python3 ./xxx/mnist_cnn.py #mnist_cnn.py可能在不同的路徑下
確認可以運行後,就可以開始打包了。
打包
筆者是在Ubuntu 16.04.5 LTS系統的docker容器(nvcr.io/nvidia/tensorflow:18.08-py3)內將mnist_cnn.py檔打包,
Python版本是3.5.2。
CUDA版本是V9.0.176。
keras版本是2.2.4。
TF版本是1.9.0。
使用以下指令:
pyinstaller mnist_cnn.py
結果會生成:build, dist兩個資料夾及mnist_cnn.spec這個文檔。
dist下的mnist這個資料夾就是打包好的結果。
dist/mnist_cnn下共有102個文檔/資料夾:
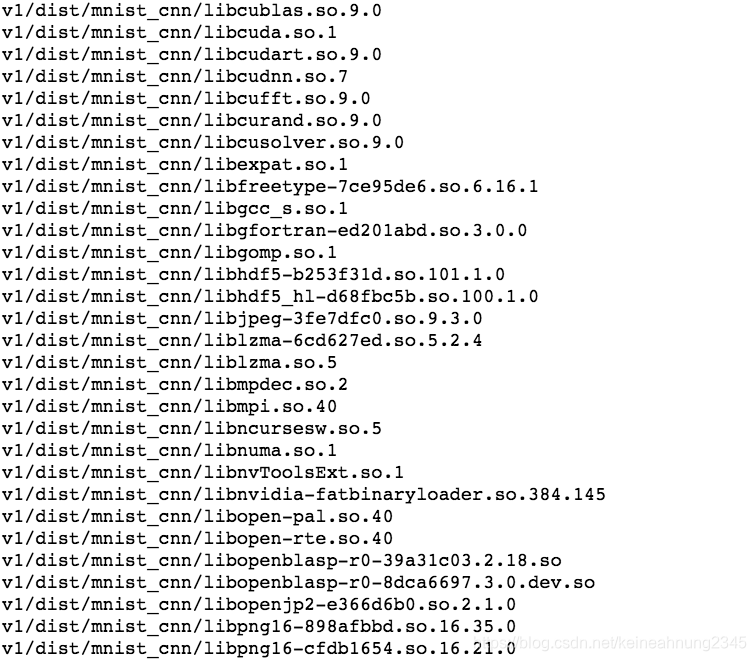
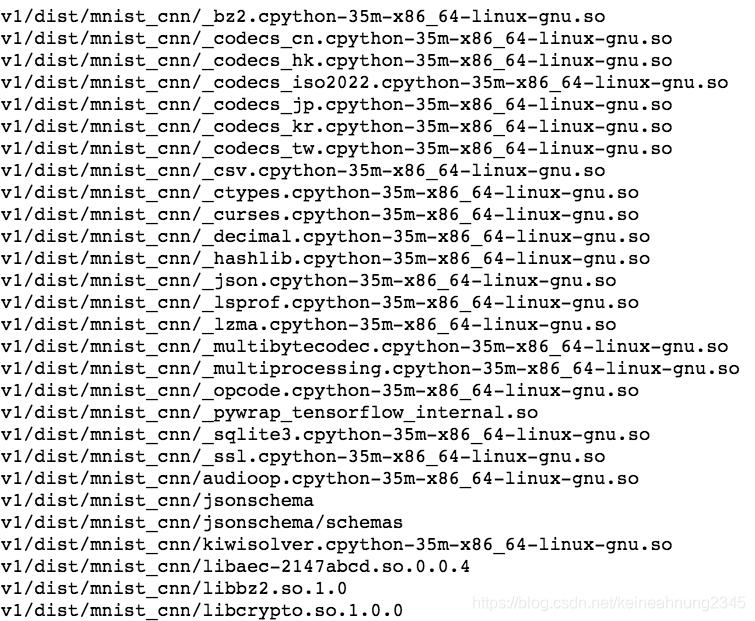
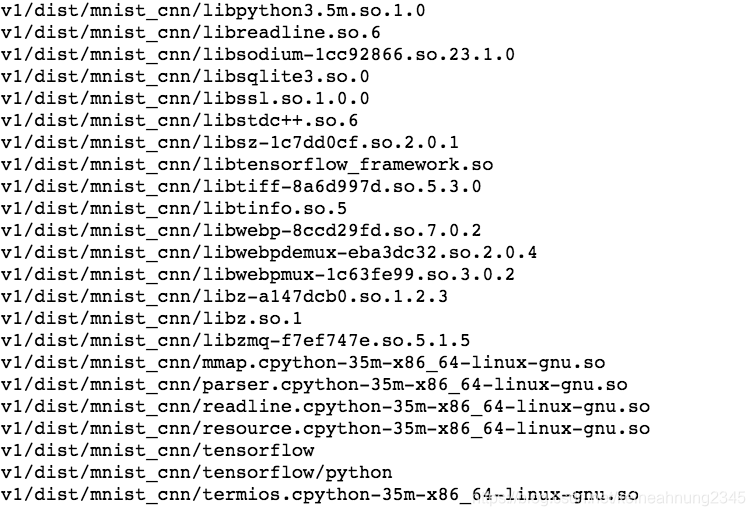
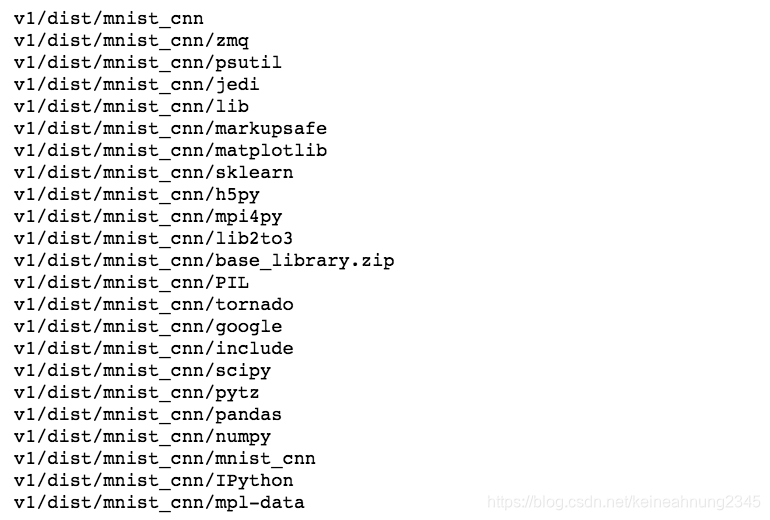
其中dist/mnist_cnn/mnist_cnn是可執行檔,其它的則是它所依賴的套件。
如果希望dist/mnist_cnn下只有單一的檔案,可以改用以下指令打包:
pyinstaller --onefile mnist_cnn.py
結果一樣會產生build, dist兩個資料夾及mnist_cnn.spec這個文檔。
但這時dist資料夾下就只會有mnist一個可執行檔。
實驗
想要將打包好的可執行檔拿到其它環境裡運行,需要把整份mnist資料夾移到該環境下。
並且同樣要記得必須將mnist.npz放在執行路徑下。
實驗一:在打包的docker內跑(GPU)
筆者的mnist.npz是放在當前目錄中,在當前目錄使用以下指令:
./dist/mnist_cnn/mnist_cnn
機器上有8顆GPU,而該docker容器上可以看到其中2顆。
以下是執行log:

可以看到它會調用2顆GPU。
注意mnist.npz必須存在於運行目錄下,否則會出現以下錯誤:

實驗二:在打包的機器上的其它docker內跑(CPU)
在Ubuntu 16.04(無Python及CUDA)。
NV_GPU=0,1 nvidia-docker run -it -v `pwd`:/root ubuntu:16.04

可以成功運行,但是沒有使用GPU。
使用以下指令檢查容器內是否看得到GPU:
nvidia-docker run --rm -e NVIDIA_VISIBLE_DEVICES=all ubuntu:16.04 nvidia-smi
報了個錯:
docker: Error response from daemon: OCI runtime create failed: container_linux.go:348: starting container process caused “exec: “nvidia-smi”: executable file not found in $PATH”: unknown.
看來是在容器內它並不認得nvidia-smi這個指令。
後來去網上找到了這個issue"exec: “nvidia-smi”: executable file not found in $PATH". ,有大佬建議將nvidia-docker升級到2.0版。
在機器上(容器外),查詢一下nvidia-docker版本:
nvidia-docker version
發現nvidia-docker是1.0.1版。
因此這次實驗沒用到GPU其實是nvidia-docker本身的問題,跟docker內的環境無關。
接下來試試直接在打包的機器上跑。
實驗三:在打包的機器上跑(GPU)
打包的機器的作業系統是Ubuntu 16.04.4 LTS。
CUDA版本是7.5.17版,Python版本是3.5.2版。
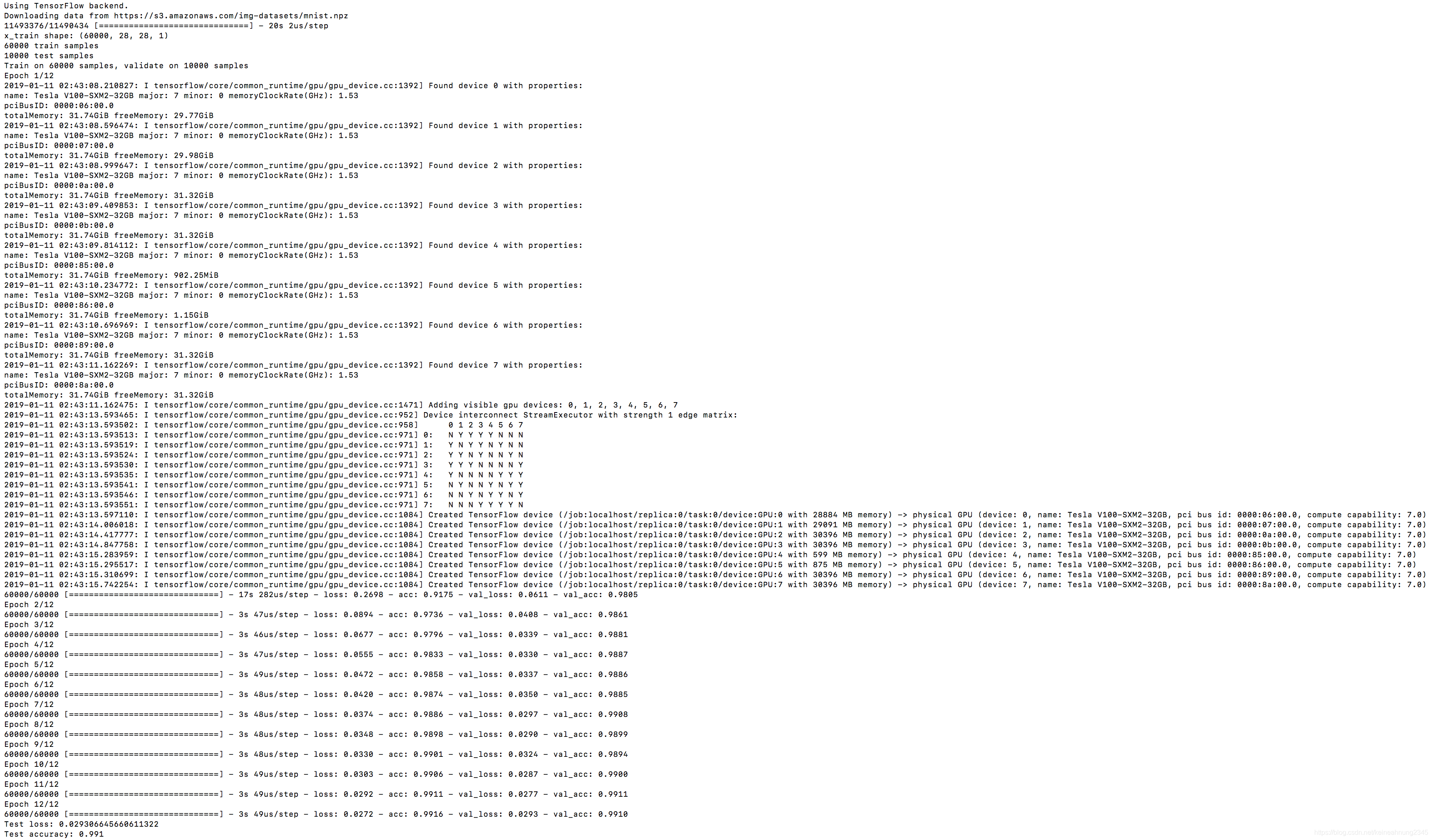
從圖中看來,運行也是成功的,並且調用了8顆GPU。
實驗四:在其它機器上的Ubuntu docker跑(CPU)
筆者選了一台有兩顆GeForce GTX 1080的GPU,顯卡版本為396.37的機器。
然後在上面運行一台Ubuntu16.04的docker容器(裡面沒裝Python跟CUDA)。
NV_GPU=0,1 nvidia-docker run -td --rm --name ubt ubuntu:16.04 #可以用nvidia-smi
docker cp dist ubt:/root
docker cp mnist.npz ubt:/root
docker exec -it ubt bash
# nvidia-docker run -it --rm ubuntu:16.04 #無法用nvidia-smi
# docker run -it --rm ubuntu:16.04 #無法用nvidia-smi
以下是執行畫面:
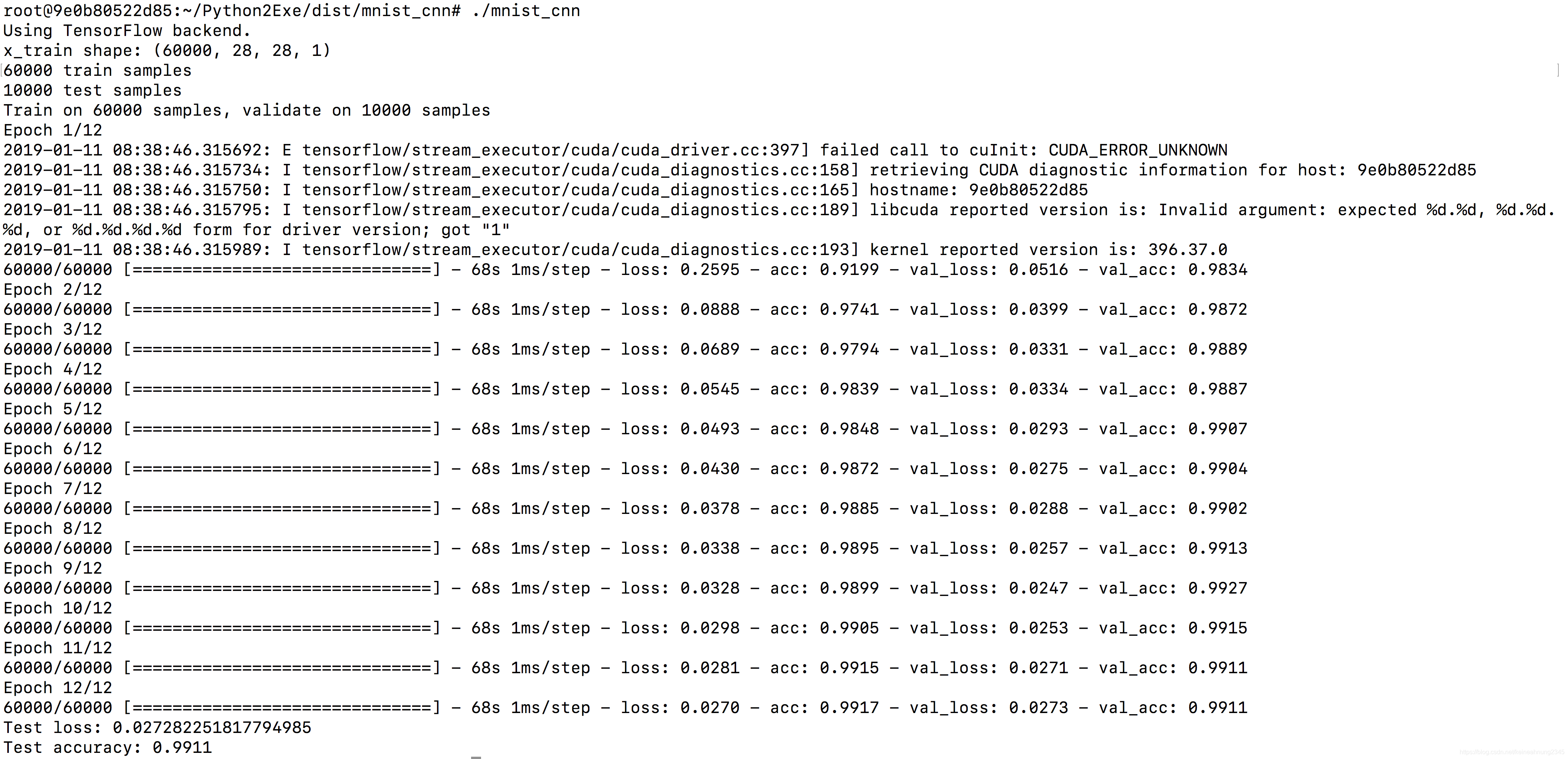
雖然運行成功,但是過程中是沒有調用GPU的。這似乎是CUDA的問題。
但是在dist/mnist_cnn裡有看到cuda相關的.so檔,不知道他們的作用是什麼。
注:在容器內下nvidia-smi可以成功。
後記:
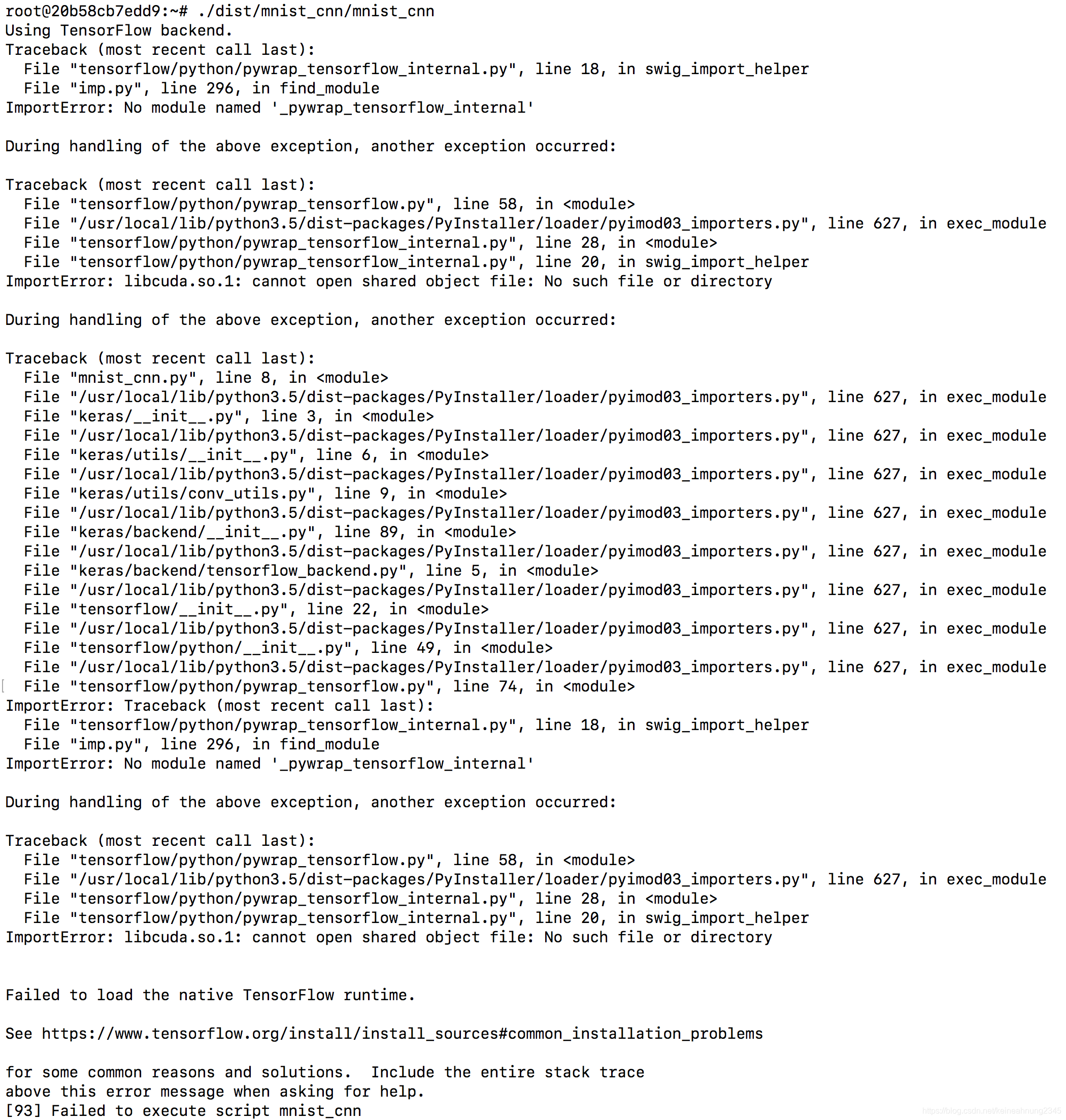
在實驗五中移除libcuda.so.1就可以用到GPU,這裡也試試看同樣的方法:
mv dist/mnist_cnn/libcuda.so.1 dist/mnist_cnn/libcuda.so.1.bak
發現會失敗。
從錯誤訊息看來libcuda.so.1似乎仍是個必要的檔案。
實驗五:在其他機器上的Ubuntu16.04,CUDA9.0 docker上跑(GPU)
剛剛是在沒有CUDA的容器上跑,發現不會調用GPU,這次改用自帶CUDA的容器看看:
NV_GPU=0,1 nvidia-docker run -td --rm --name cdubt nvidia/cuda:9.0-base-ubuntu16.04
docker cp dist cdubt:/root
docker cp mnist.npz cdubt:/root
docker exec -it cdubt bash
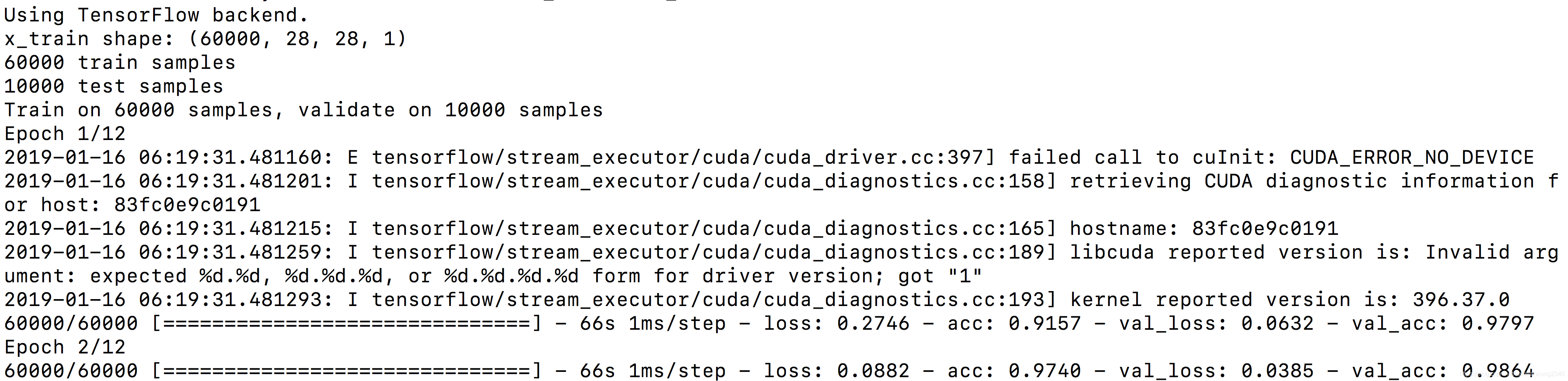
這次雖然一樣可以運行,但是同樣不會調用GPU。
這次使用的是帶有CUDA的docker,可以看到它說libcuda的版本是1(錯誤!),而顯卡驅動器的版本是396.37(正確,在容器中及容器外使用nvidia-smi查證,結果一致)。
先說解法,這是筆者試了好久才試出來的:
mv dist/mnist_cnn/libcuda.so.1 dist/mnist_cnn/libcuda.so.1.bak
# cp /usr/lib/x86_64-linux-gnu/libcuda.so.396.37 dist/mnist_cnn
./dist/mnist_cnn/mnist_cnn
以上指令相當於是把libcuda.so.1這個檔案移除,因為它就是導致libcuda版本被誤判為1的原因。
以下是執行結果,可以看到有成功調用2顆GPU:
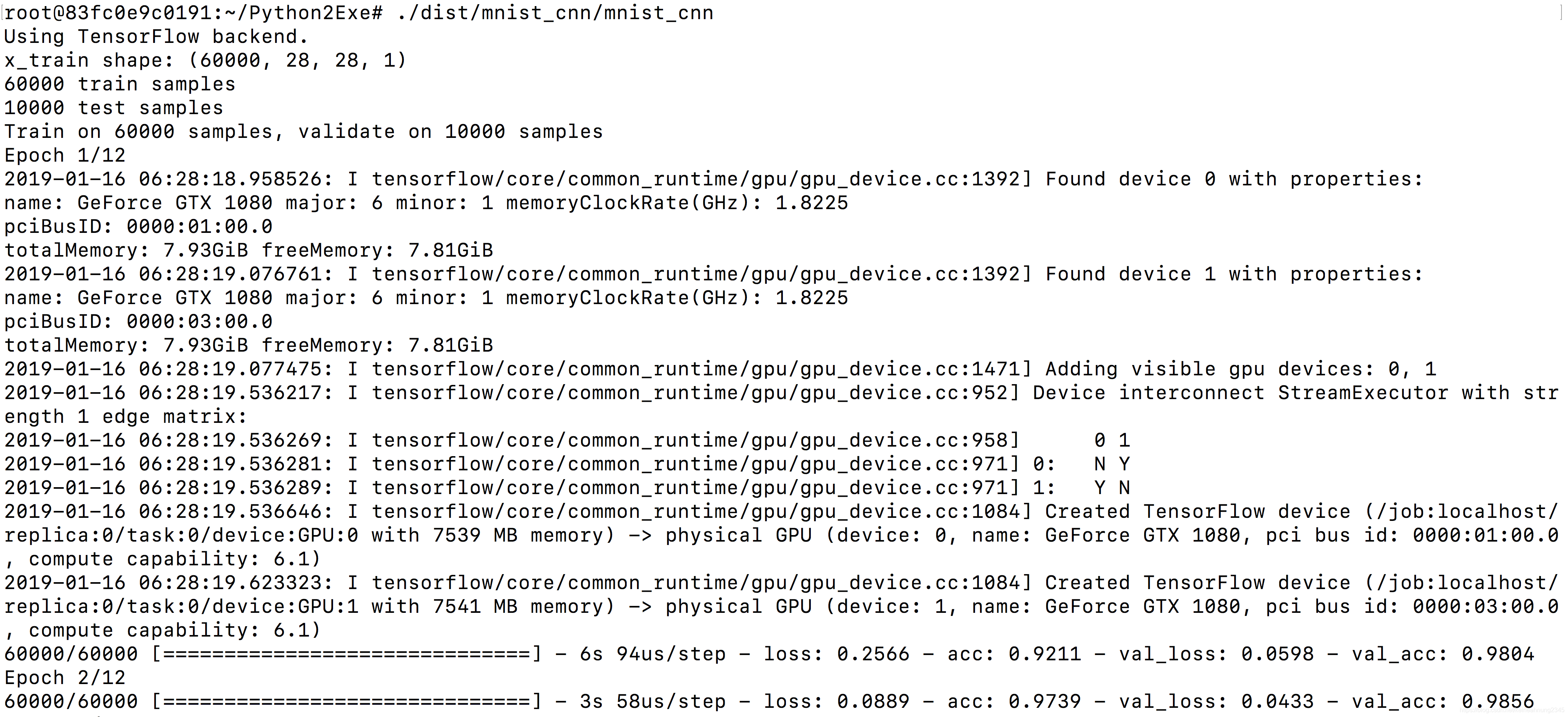
踩坑記
以下是冗長的踩坑記:
設定CUDA_VISIBLE_DEVICES環境變量
查到了一則相關問答:failed call to cuInit: CUDA_ERROR_UNKNOWN,使用以下指令設定CUDA_VISIBLE_DEVICES環境變量:
export CUDA_VISIBLE_DEVICES="0"
但發現沒用,結果還是一樣。
使用以下指令復原:
unset CUDA_VISIBLE_DEVICES
安裝libcuda1-396
因為錯誤訊息裡有提到libcuda版本為1,看起來十分可疑。
首先查一下容器內有沒有安裝CUDA:
nvcc -V #bash: nvcc: command not found
,並且發現/usr/local/cuda-9.0/裡不存在bin這個資料夾。(??)
既然問題跟CUDA有關,就試著安裝一下libcuda:
參考libcuda reported version is: Not found: was unable to find libcuda.so DSO loaded into this program,使用以下指令安裝:
apt-get update -y
先查詢跟libcuda相關的套件名稱:
apt-get search ".*libcuda.*"
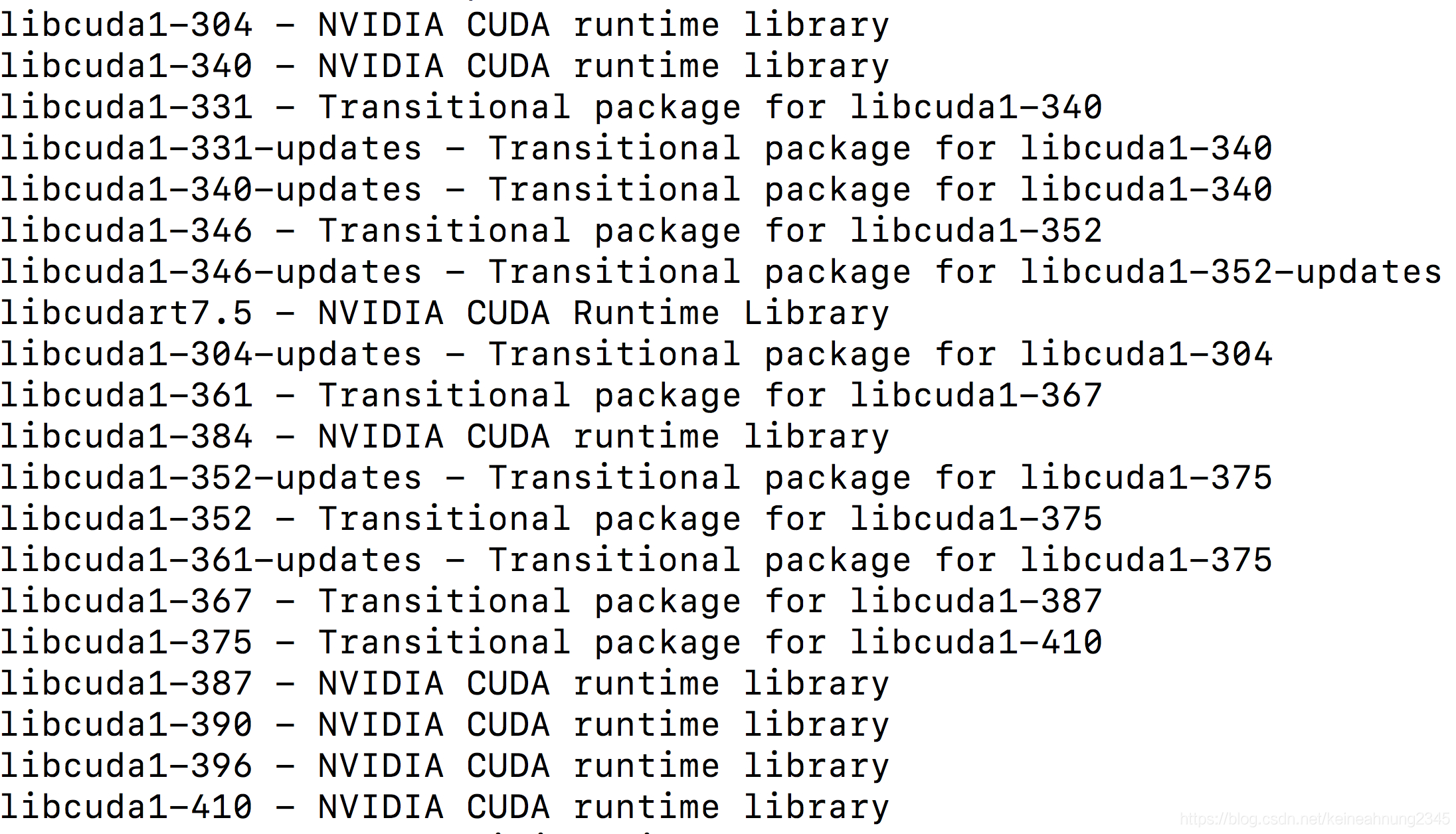
因為機器上的顯卡版本號同樣是396開頭,這裡選擇安裝libcuda1-396:
apt-get install -y libcuda1-396
# apt-get purge -y libcuda1-396 #卸載
再次重新運行,直接報錯,甚至無法單用CPU運行:
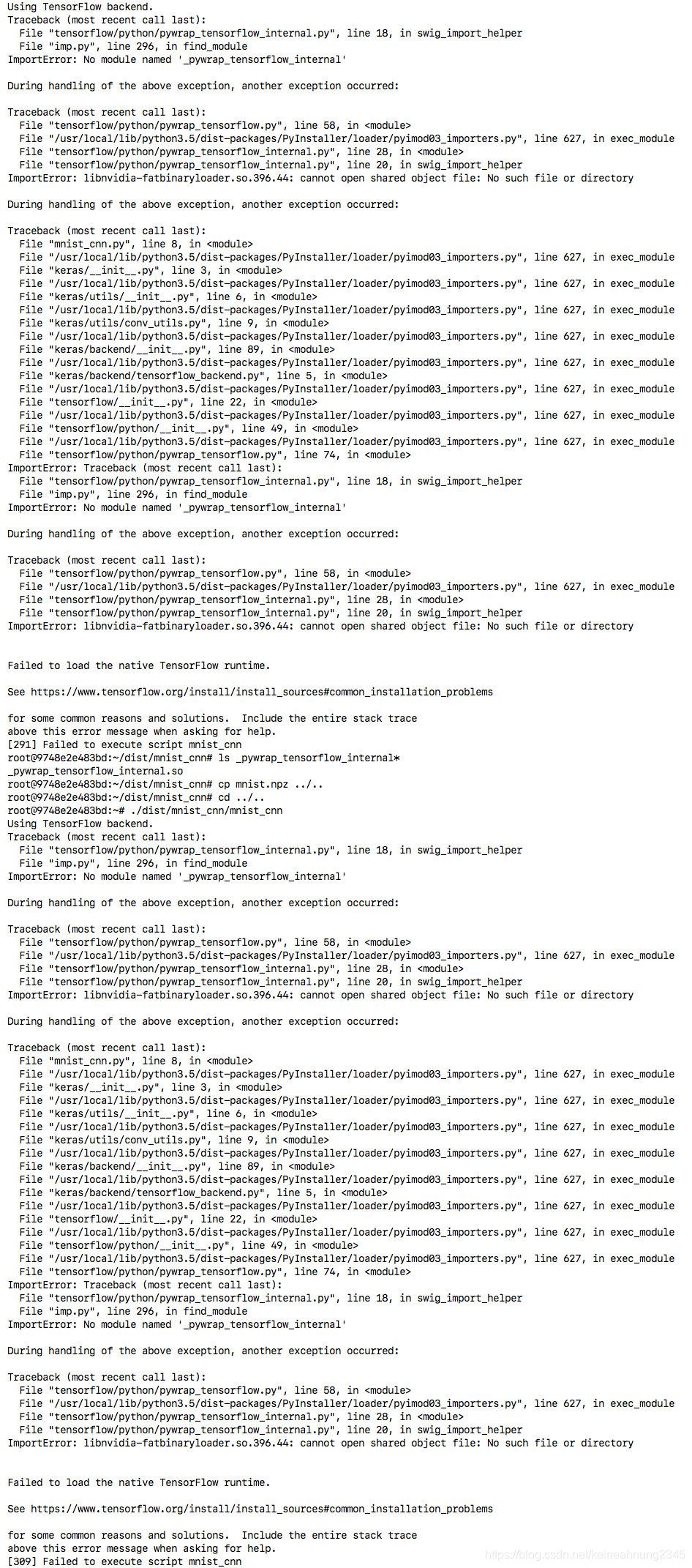
將錯誤訊息中的libnvidia-fatbinaryloader.so.396.44複製到dist/mnist_cnn/目錄下:
cp /usr/lib/nvidia-396/libnvidia-fatbinaryloader.so.396.44 ./dist/mnist_cnn/
變得可以運行了,但是同樣只能跑在CPU上:
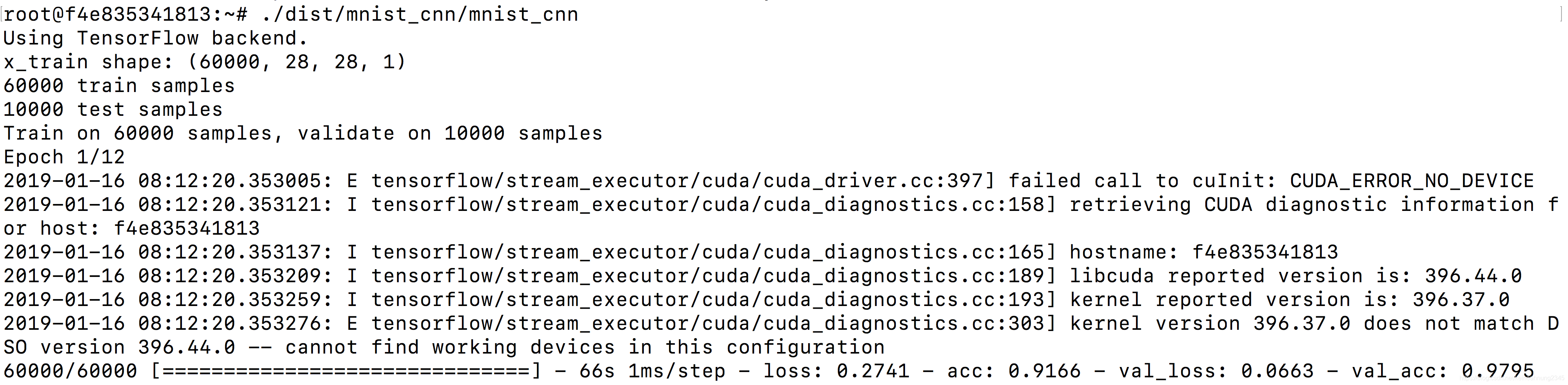
訊息有一行說到libcuda與顯卡版本不符。
後來才發現跟本不應該安裝libcuda1-396。使用以下指令來卸載:
apt-get purge -y libcuda1-396
實驗六:在其他機器上的Ubuntu16.04,CUDA8.0 docker上跑(GPU)
在這個docker容器中,CUDA的版本由原來的9.0降為8.0。
NV_GPU=0,1 nvidia-docker run -td --rm --name cd8ubt nvidia/cuda:8.0-runtime-ubuntu16.04
這次實驗的情況跟"實驗五:在其他機器上的Ubuntu16.04,CUDA9.0 docker上跑"是一樣的。
不刪除dist/mnist_cnn/libcuda.so.1的話只能用CPU跑,刪除之後就可以在GPU上運行。
根據Which TensorFlow and CUDA version combinations are compatible?,TF1.9需要的是CUDA 9,但是這個實驗卻能成功???
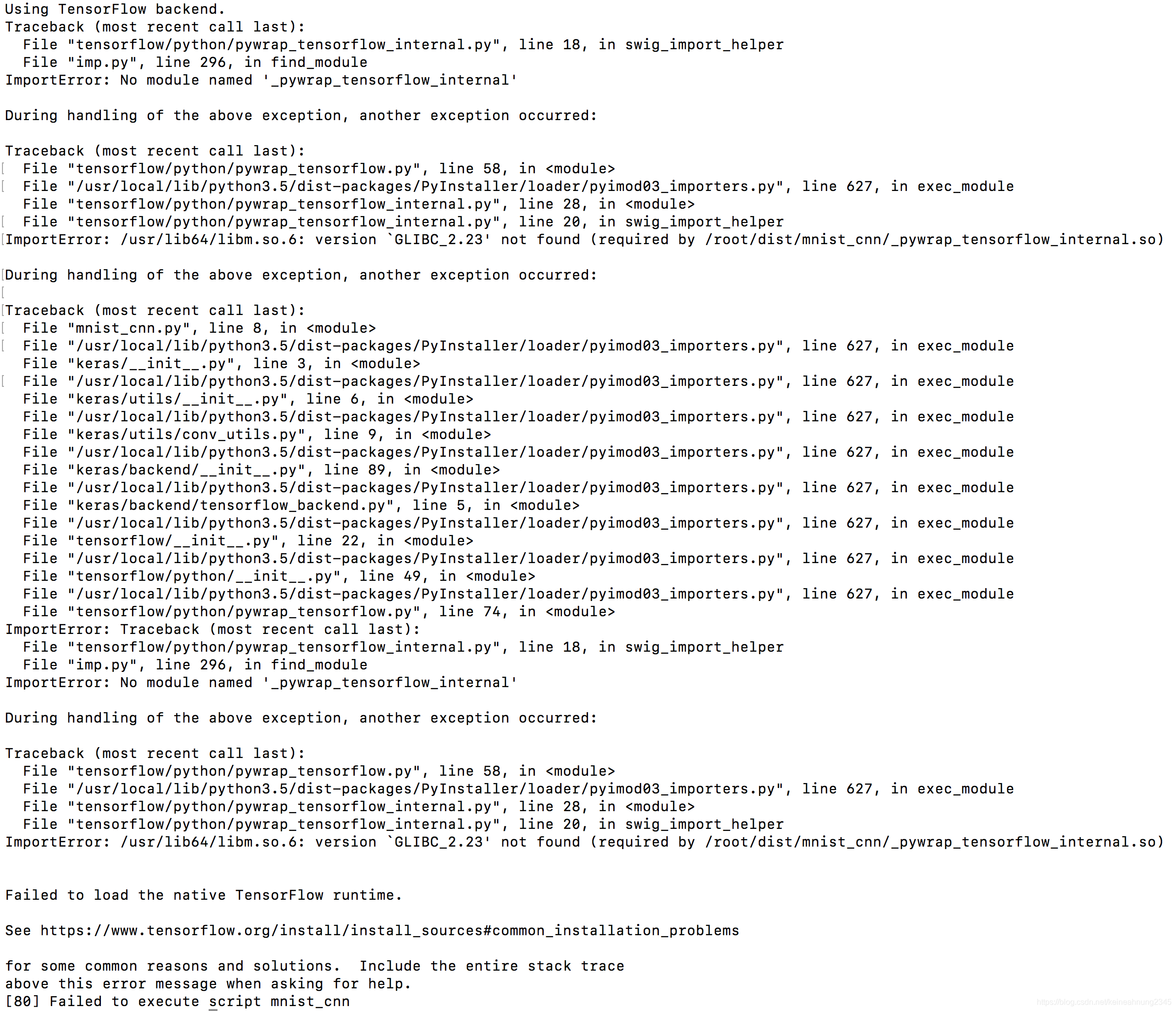
實驗七:在其他機器上的CentOS7,CUDA9.0 docker上跑(失敗)
如果將CUDA 9.0保留,作業系統換成CentOS7會怎麼樣呢?
(本來想試試Ubuntu 14.04+CUDA 9.0,但CUDA 9.0要求Ubuntu的版本需高於16.04)
NV_GPU=0,1 nvidia-docker run -td --rm --name cd9ct7 nvidia/cuda:9.0-runtime-centos7
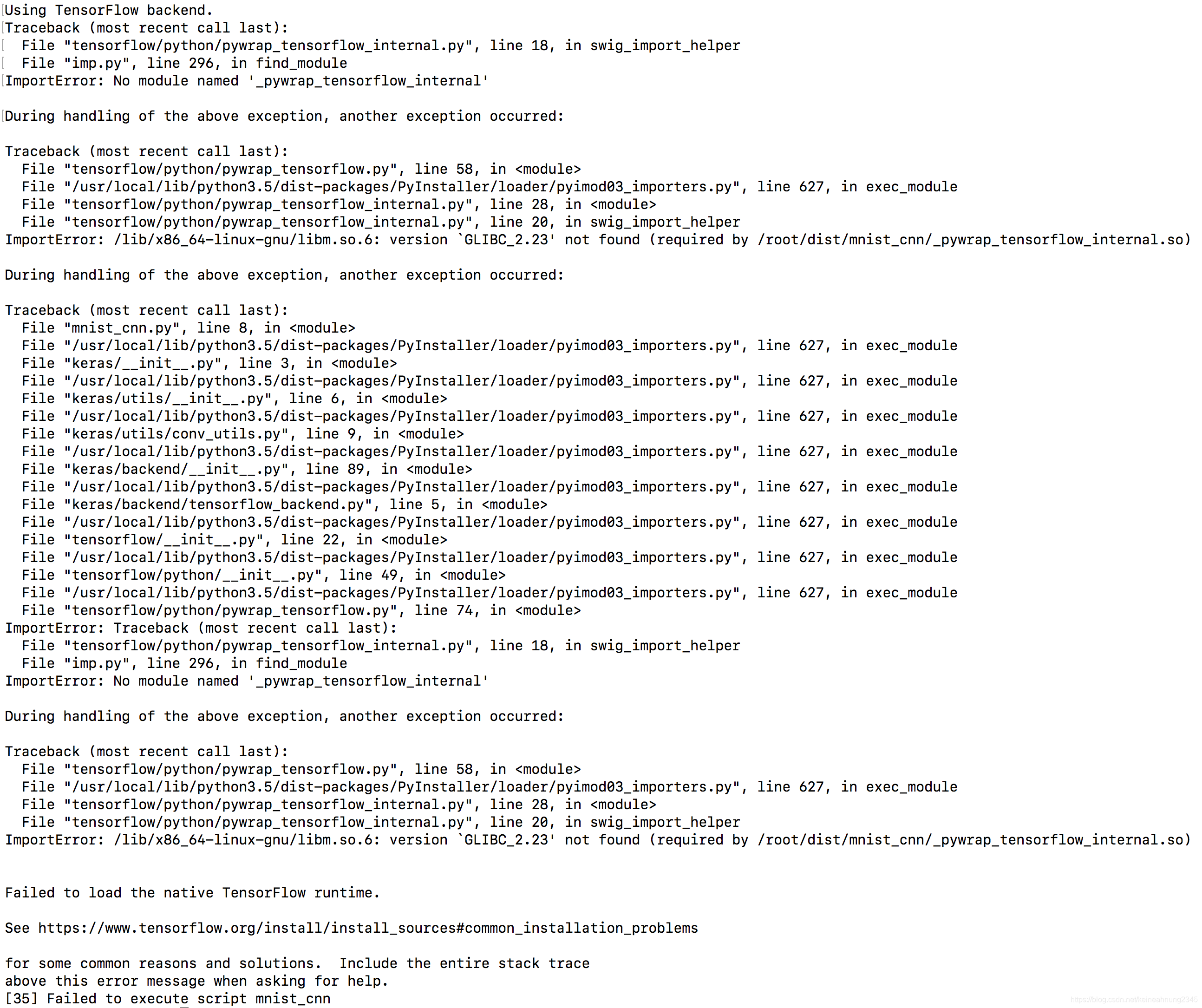
實驗八:在其他機器上的Ubuntu14.04,CUDA8.0 docker上跑(失敗)
NV_GPU=0,1 nvidia-docker run -td --rm --name cd8ubt14 nvidia/cuda:8.0-runtime-ubuntu14.04
連使用CPU運行都會失敗:
實驗九:在其他機器上的nvidia-driver docker上跑(失敗)
NV_GPU=0,1 nvidia-docker run -it --name drv nvidia/driver:396.37-ubuntu16.04
出現以下錯誤訊息:

這個docker裡的顯卡是容器啟動後才裝?
後記
參考:How to remove/exclude modules and files from pyInstaller?。
如果想要在打包時就排除libcuda.so.1這個檔案,要分兩步走,先用:
pyi-makespec mnist_cnn.py
生成mnist_cnn.spec這個檔案。然後:
方法一(失敗)
然後在mnist_cnn.spec的Analysis裡找到excludes,加上'libcuda.so.1':
a = Analysis(['mnist_cnn.py'],
pathex=['/xxx/xxx/xxx'],
binaries=[],
datas=[],
hiddenimports=[],
hookspath=[],
runtime_hooks=[],
excludes=['libcuda.so.1'],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
接著執行:
pyinstaller mnist_cnn.spec
但是檢查dist/mnist_cnn這個資料夾,卻發現libcuda.so.1這個檔案還在裡面。
方法二(成功)
在a = Analysis(...)下面加上:
a.binaries = a.binaries - TOC([
('libcuda.so.1', None, None)])
然後同樣:
pyinstaller mnist_cnn.spec
去檢查dist/mnist_cnn這個資料夾,發現己經沒有libcuda.so.1這個檔案了。
重做實驗六,發現可以用GPU運行,也不需要再手動移除libcuda.so.1。
onefile打包方法
pyi-makespec --onefile mnist_cnn.py
然後按照方法二修改mnist_cnn.spec,再用:
pyinstaller mnist_cnn.spec
來生成執行檔。
重做實驗六,發現可以用GPU運行。
結論
從實驗結果看來,在Ubuntu 16.04,CUDA9.0的容器裡打包的Python執行檔,要在相同系統,並安裝有CUDA的容器內才可以成功的執行。
參考連結
Freezing Your Code
bbfreeze的GitHub官網
PyInstaller官方文檔
“exec: “nvidia-smi”: executable file not found in $PATH”.
failed call to cuInit: CUDA_ERROR_UNKNOWN
libcuda reported version is: Not found: was unable to find libcuda.so DSO loaded into this program
NVIDIA CUDA 9.0 Installation Guide for Linux
nvidia-driver docker
How to remove/exclude modules and files from pyInstaller?
Python: Excluding Modules Pyinstaller
Which TensorFlow and CUDA version combinations are compatible?

















 4612
4612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









