













解题思路
按照数据,分类讨论n-1=m和n=m的情况。
对于树上的情况(n=m),题目暗含条件:当我们到达一个点时,我们必须遍历完它的整个子树才能后退然后去到别的点。
此时,我们可以用vector来存储它的所有边然后按这条边的终点的编号从小到大排一下序,这样就可以保证字典序最小了。于是,我们用一个dfs按顺序遍历每一个节点,在dfs过程中把它们压入ans数组中,最后输出ans数组就可以了。
后四个子任务n=m,而整个图又是联通的,这说明,这个图是一个基环树。
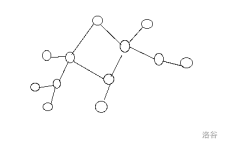
基环树:可以理解成在一棵树上的两个节点多连了一条边,拿刚才那张图举个例子,我们删掉环上的一条边它就变成了一棵树
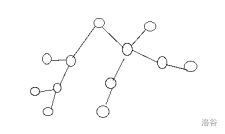
思考一下可以发现,在我们遍历整个图的时候,环上总有一条边是不会被经过的,所以我们可以枚举断哪一条边,然后对整个图按照60分做法跑一边dfs,最后对所有情况取最大值。
代码
#include<cstdio>
#include<iostream>
#include<queue>
#include<algorithm>
#include<cstring>
#include<cmath>
#define ll long long
using namespace std;
vector<int>v[5010];
int n,m,k,x,y,z,p,q,cnt;
int ans[5010],s[5010],vis[5010];
struct c {
int x,y;
} a[100010];
void add(int x,int y) {
a[++k].x=x;
a[k].y=y;
}
void dfs(int x,int fa) {
ans[++cnt]=x;
for(int i=0; i<v[x].size(); i++) {
int y=v[x][i];
if(y!=fa)
dfs(y,x);
}
}
void dfs2(int x,int fa) {
if(vis[x])
return;
vis[x]=1;
s[++cnt]=x;
for(int i=0; i<v[x].size(); i++) {
int y=v[x][i];
if(y==fa)continue;
if((x==p&&y==q)||(x==q&&y==p))continue;
dfs2(y,x);
}
}
bool check() {
for(int i=1; i<=n; i++) {
if(s[i]<ans[i])
return 1;
else if(s[i]>ans[i])return 0;
}
return 0;
}
int main() {
scanf("%d%d",&n,&m);
for(int i=1; i<=m; i++) {
scanf("%d%d",&x,&y);
add(x,y);
add(y,x);
v[x].push_back(y);
v[y].push_back(x);
}
for(int i=1; i<=n; i++)
sort(v[i].begin(),v[i].end());
if(n-1==m) {
dfs(1,0);
for(int i=1; i<=cnt; i++)
printf("%d ",ans[i]);
return 0;
}
if(n==m) {
for(int i=1; i<=k; i+=2) {
memset(vis,0,sizeof(vis));
p=a[i].x,q=a[i].y;
cnt=0;
dfs2(1,0);
if(cnt<n)continue;
if(ans[1]==0) {
for(int i=1; i<=n; i++)
ans[i]=s[i];
continue;
}
if(check()) {
for(int i=1; i<=n; i++)
ans[i]=s[i];
}
}
for(int i=1; i<=n; i++)
printf("%d ",ans[i]);
return 0;
}
}














 297
297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









